tying wv and wc
1.0.0
Implémentation pour "Vectors de mots et classificateurs de mots: un cadre de perte pour la modélisation du langage"
Cet article essaie d'utiliser la diversité du sens des mots pour former le réseau neuronal profond.
Dans la modélisation du langage (prédiction de la séquence de mots), nous voulons exprimer la diversité du sens des mots.
Par exemple, lors de la prévision du mot à côté de "la banane est délicieuse ___", la réponse est "fruit", mais "bonbons", "la nourriture" est également OK. Mais l'enseignement vectoriel ordinaire ne convient pas pour y parvenir. Parce que tous les mots similaires ont ignoré, mais le mot de réponse exact.
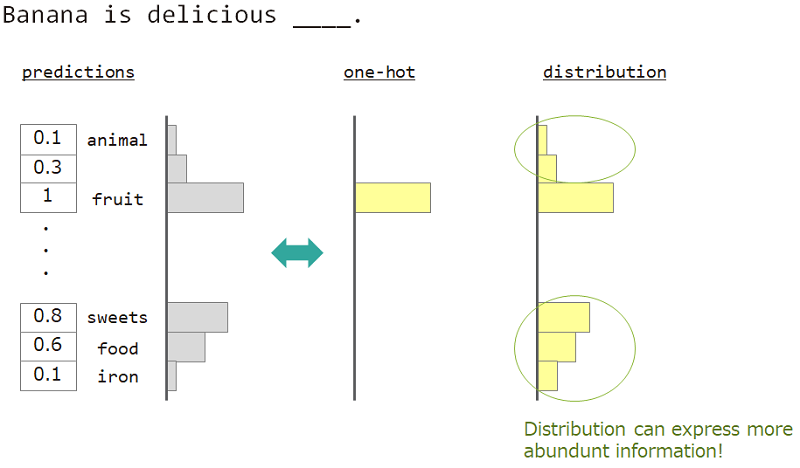
Si nous pouvons utiliser non pas un hot mais une «distribution», nous pouvons enseigner cette variété.
Nous utilisons donc "la distribution du mot" pour enseigner le modèle. Cette distribution acquise à partir du mot de réponse et de la matrice de recherche d'intégration.


Si nous utilisons cette perte de type de distribution, nous pouvons prouver l'équivalence entre l'intégration d'entrée et la matrice de projection de sortie.
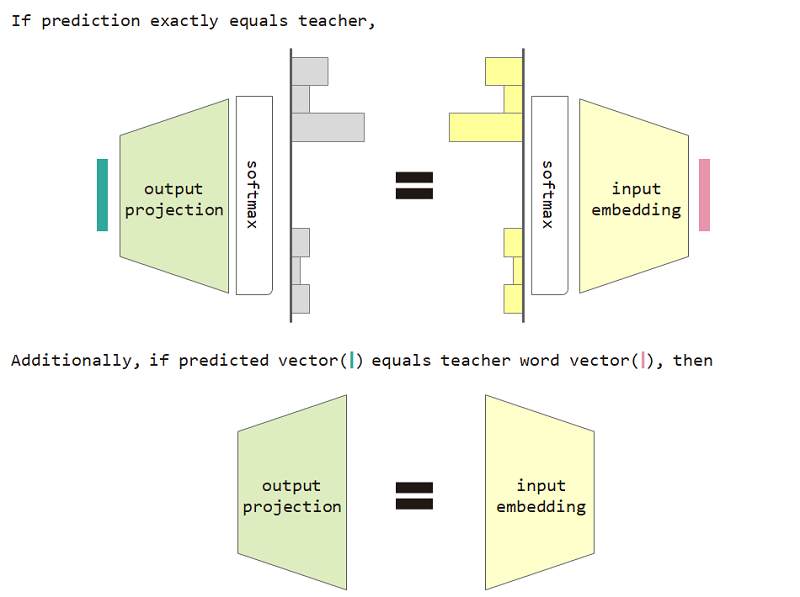
Pour utiliser le type de distribution, la perte et la restriction de l'équivalence de la projection de la projection d'entrée améliorent la perplexité du modèle.
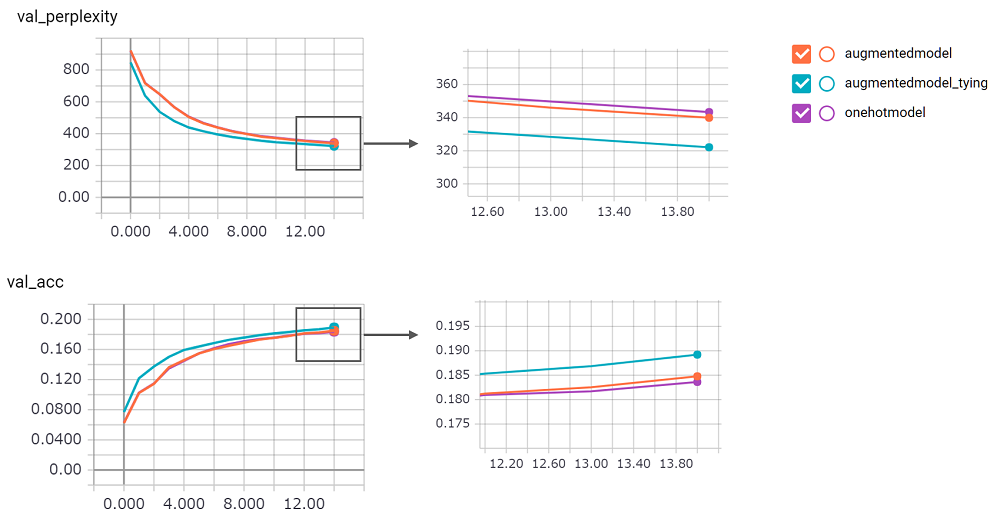
perplexity est important, je ne pouvais pas avoir confiance en sa mise en œuvre. J'attends la demande de traction!augmentedmodel fonctionne mieux que la ligne de base ( onehotmodel ), et augmentedmodel_tying surpasse la ligne de base!python train.pyJ'ai implémenté la version LSTM avec état. Son résultat comme suit.
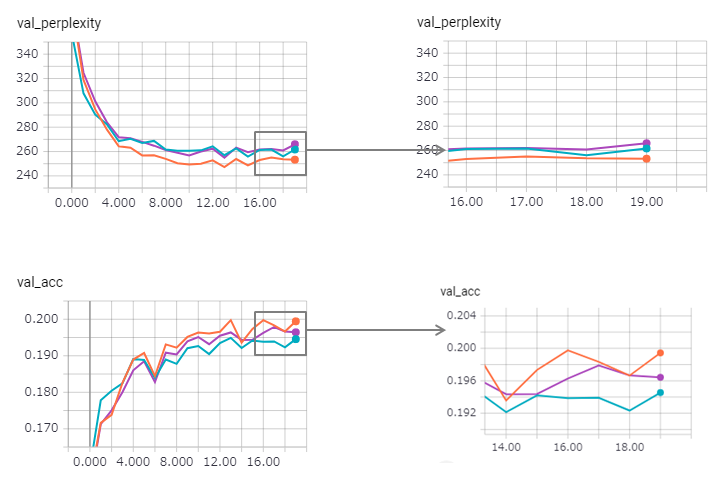
La perplexité est améliorée (mais zaggy) et la méthode de liaison perd un peu son effet.
Utiliser le LSTM avec état dans KERAS est trop difficile (en particulier reset_states dans l'ensemble de validation), il peut donc y avoir une limite incluse.
Soit dit en passant, l'exemple Pytorch utilise déjà la méthode de liaison! N'ayez pas peur de l'utiliser!


