tying wv and wc
1.0.0
Реализация для "связывания векторов слов и классификаторов слов: структура потерь для языкового моделирования"
Эта статья пытается использовать разнообразие значения слова для обучения глубокой нейронной сети.
В языковом моделировании (прогнозирование последовательности слова) мы хотим выразить разнообразие значения слова.
Например, при прогнозировании слова рядом с «бананом восхитительно ___», ответ - «фрукты», но «сладости», «еда» также в порядке. Но обычное одножелательное векторное обучение не подходит для его достижения. Потому что любые подобные слова игнорировались, но точный ответ на ответ.
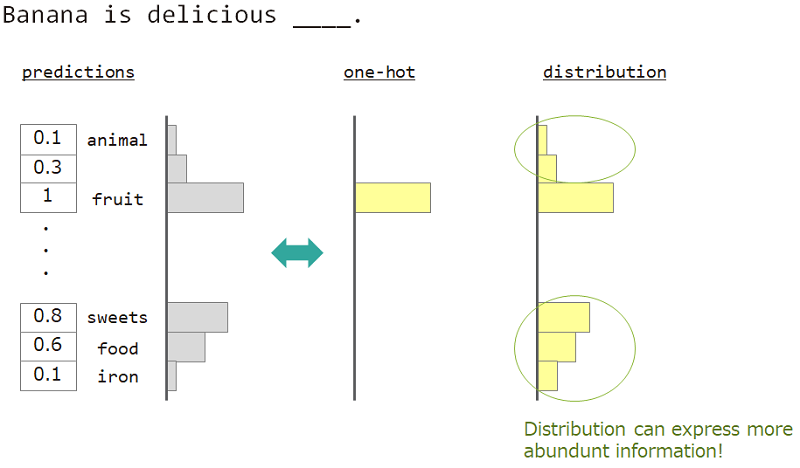
Если мы можем использовать не одножелательное, а «распределение», мы можем научить это разнообразие.
Таким образом, мы используем «распределение слова» для обучения модели. Это распределение, приобретенное из ответного слова и встраиваю матрицу поиска.


Если мы используем эту потерю типа распределения, то мы можем доказать эквивалентность между входной матрицей внедрения и выходной проекции.
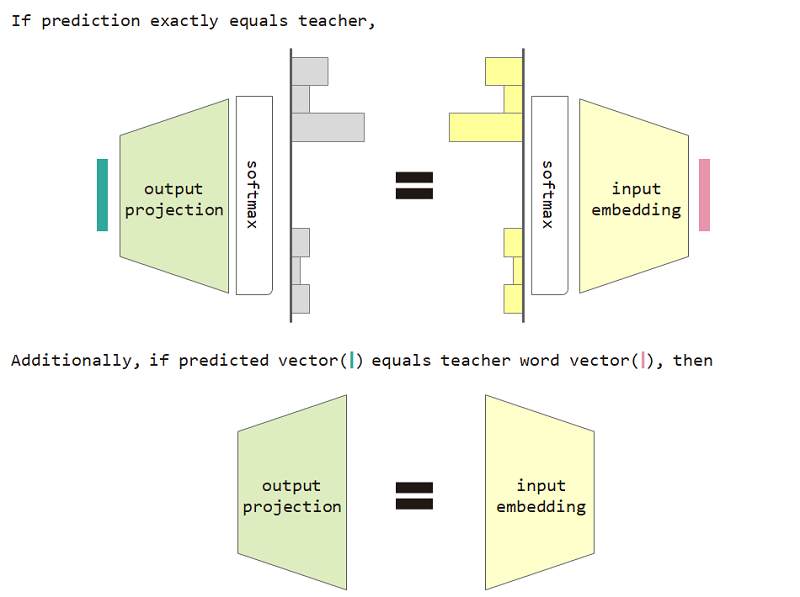
Использовать потерю потери типа распределения и входное вкладывание и эквивалентность вывода эквивалентности проекции улучшает недоумение модели.
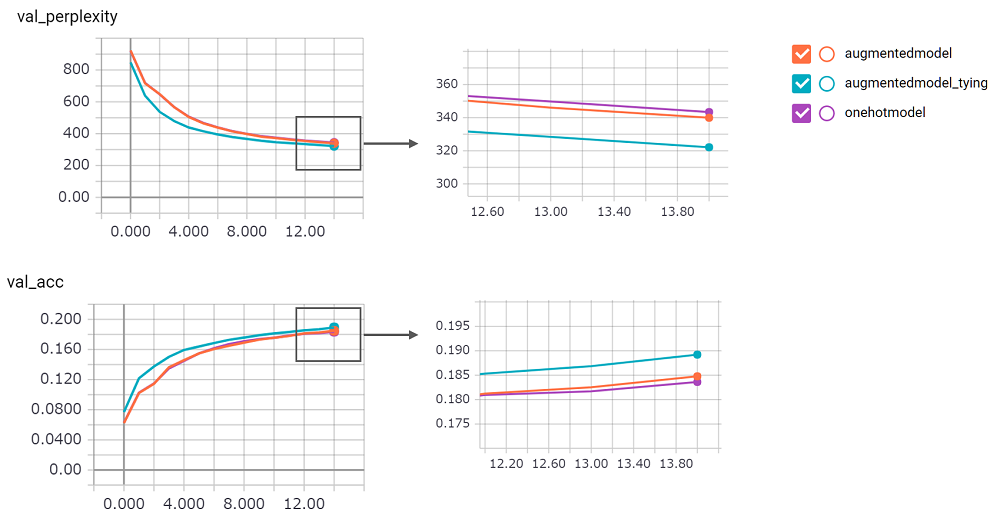
perplexity велика, я не мог уверен в его реализации. Я жду просьбу о просьбе!augmentedmodel работает лучше, чем базовая линия ( onehotmodel ), и augmentedmodel_tying превосходит базовую линию!python train.pyЯ внедрил версию LSTM Stateful. Его результат в следующем.
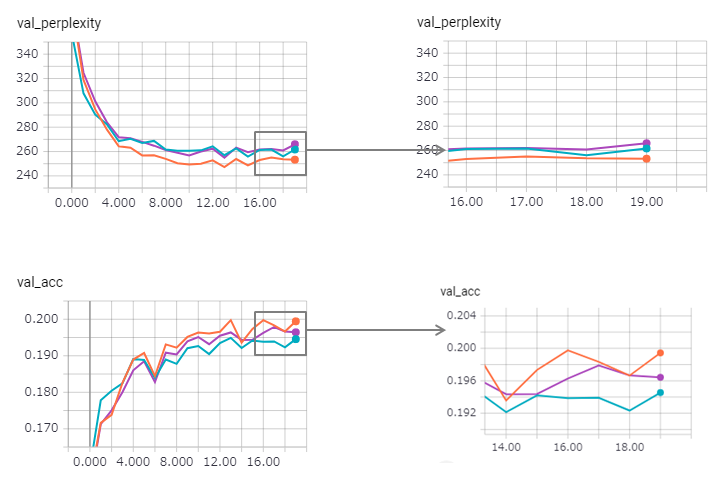
Смущение улучшается (но загар), а метод привязки немного теряет его эффект.
Использовать LSTM Stateful в керасах слишком сложно (особенно reset_states в наборе проверки), поэтому может быть некоторый ограничение.
Кстати, пример Pytorch уже использует метод связывания! Не бойтесь использовать его!


