Structured_Dreambooth_LoRA
1.0.0
models , datasets , engines , tools , utils ,以使其更可读和可维护,并且可以轻松扩展到其他任务。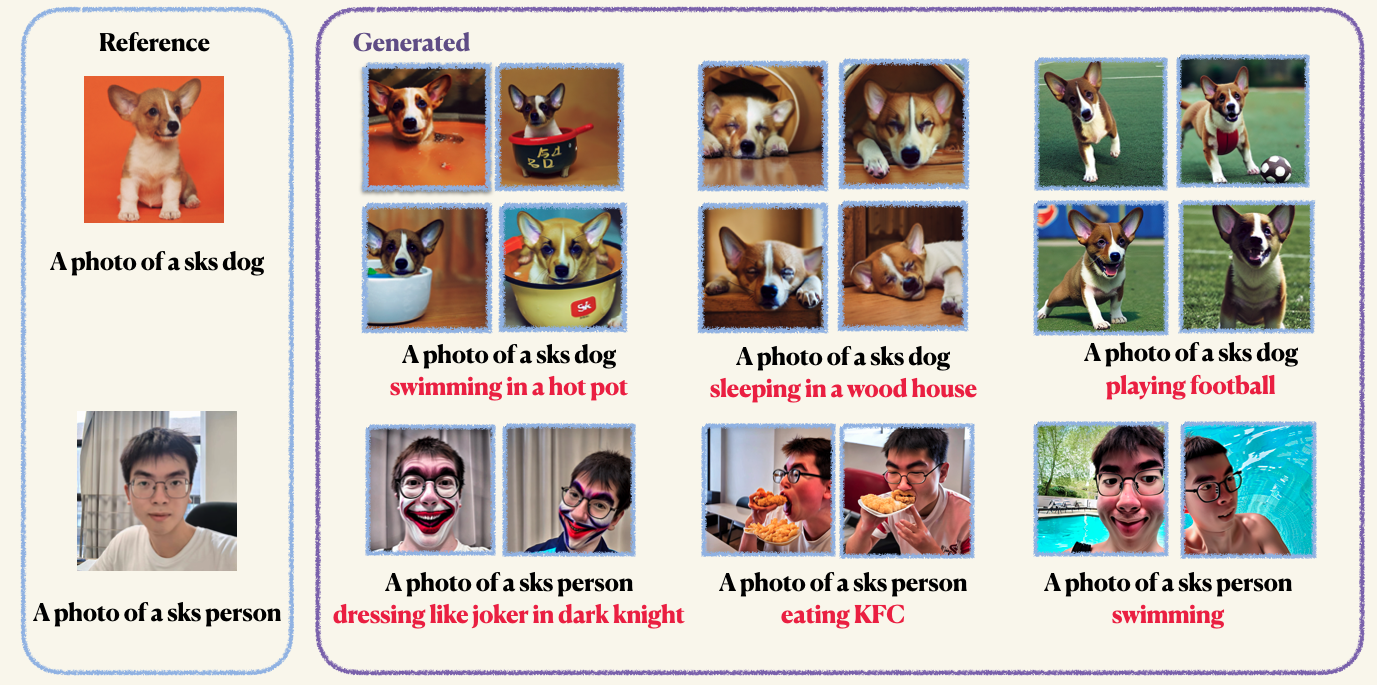
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 :准备自定义图像并将其放入文件夹中。通常,5至10张图像就足够了。我们建议您以相同尺寸的图像裁剪,例如512x512,以避免不必要的人工制品。Step2 :初始化加速度环境。 Accelerate是一个Pytorch库,它简化了启动多GPU培训和评估工作的过程。它是通过拥抱脸而开发的。 accelerate configStep3 :运行培训脚本。检查点和样本都将保存在work_dirs文件夹中。通常,只需1-2分钟即可用8GB GPU纪念量微调模型。 150个时代足以训练一个物体,但是,在对人脸进行训练时,我们建议您训练800个时代。 Dreambooth的超级参数非常敏感,您可以参考原始博客以获取一些见解。 accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4事先保存用于避免过度拟合和语言拖船(请查看纸张以了解您是否有兴趣)。为了事先保存,您将同一类的其他图像作为培训过程的一部分。好处是,您可以使用稳定的扩散模型本身生成这些图像!培训脚本将将生成的图像保存到您指定的本地路径中。
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10您可以用Lora微调文本编码器(剪辑)。但是,我们发现这导致了不融合的结果。这种现象与原始实施中报告的结果相反
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4训练后,您可以使用以下命令从提示中生成图像。我们还为狗提供了一个验证的检查站(示例)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

