Structured_Dreambooth_LoRA
1.0.0
models , datasets , engines , tools , utils , para torná-lo mais legível e sustentável e pode ser facilmente estendido a outras tarefas.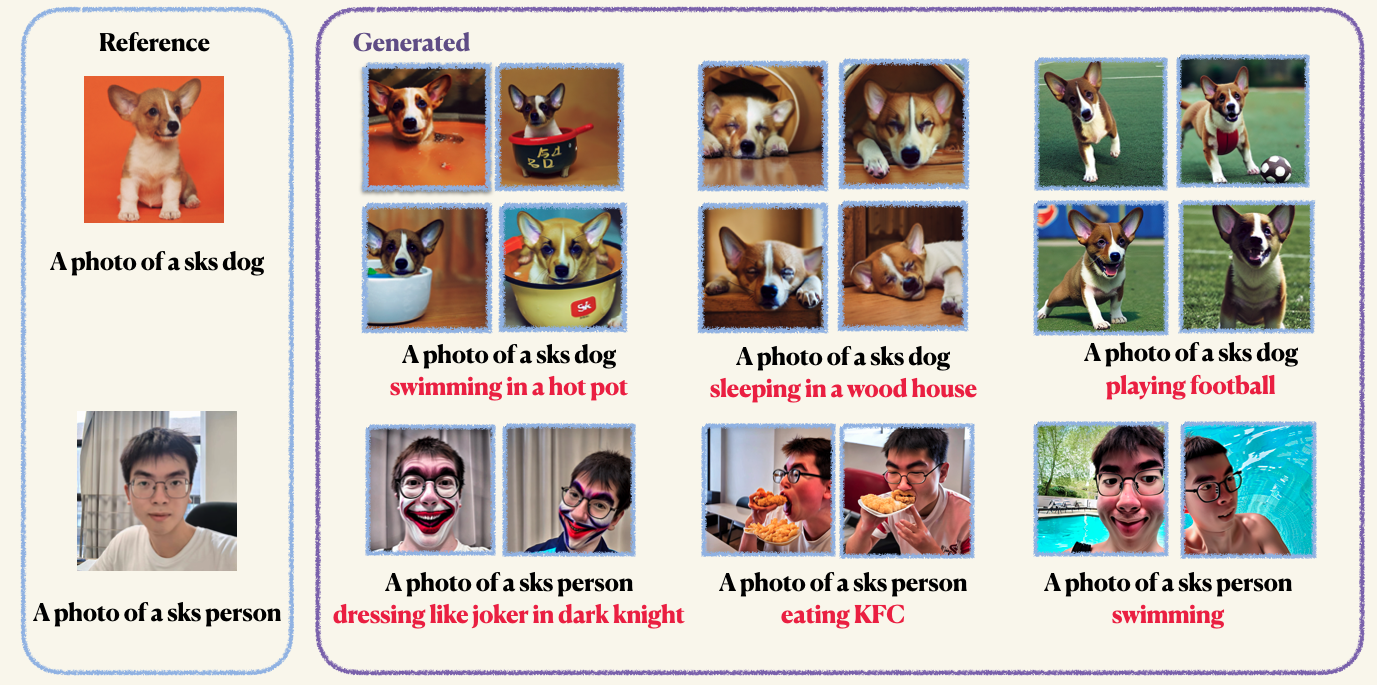
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 : Prepare suas imagens personalizadas e coloque -as em uma pasta. Normalmente, 5 a 10 imagens são suficientes. Recomendamos que você coloque as imagens mangually do mesmo tamanho, por exemplo, 512x512, para evitar artefatos indesejados.Step2 : Inicialize um ambiente acelerado. O Acelerate é uma biblioteca Pytorch que simplifica o processo de lançamento de trabalhos de treinamento e avaliação de multi-GPU. É desenvolvido abraçando o rosto. accelerate configStep3 : Execute o script de treinamento. Os pontos de verificação e as amostras serão salvos na pasta work_dirs . Normalmente, leva apenas 1-2 minutos para ajustar o modelo com apenas 8 GB de Memorcuped . 150 épocas são suficientes para treinar um objeto, no entanto, ao treinar no rosto humano, recomendamos que você treine para 800 épocas. Os hiper-parâmetros do Dreambooth são bastante sensíveis, você pode consultar o blog original para obter algumas idéias. accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4A preservação prévia é usada para evitar o excesso de ajuste e a deriva do idioma (confira o papel para saber mais se você estiver interessado). Para preservação prévia, você usa outras imagens da mesma classe como parte do processo de treinamento. O bom é que você pode gerar essas imagens usando o próprio modelo de difusão estável! O script de treinamento salvará as imagens geradas em um caminho local que você especificar.
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10Você pode ajustar o codificador de texto (clipe) com Lora. No entanto, descobrimos que isso leva a resultados não conversados. Este fenômeno é oposto aos resultados relatados na implementação original
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4Após o treinamento, você pode usar o seguinte comando para gerar imagens de um prompt. Também fornecemos um ponto de verificação pré -treinamento para cachorro (no exemplo)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

