Structured_Dreambooth_LoRA
1.0.0
models , datasets , engines , tools , utils , umstrukturiert, um ihn lesbarer und wartenableer zu gestalten, und können leicht auf andere Aufgaben erweitert werden.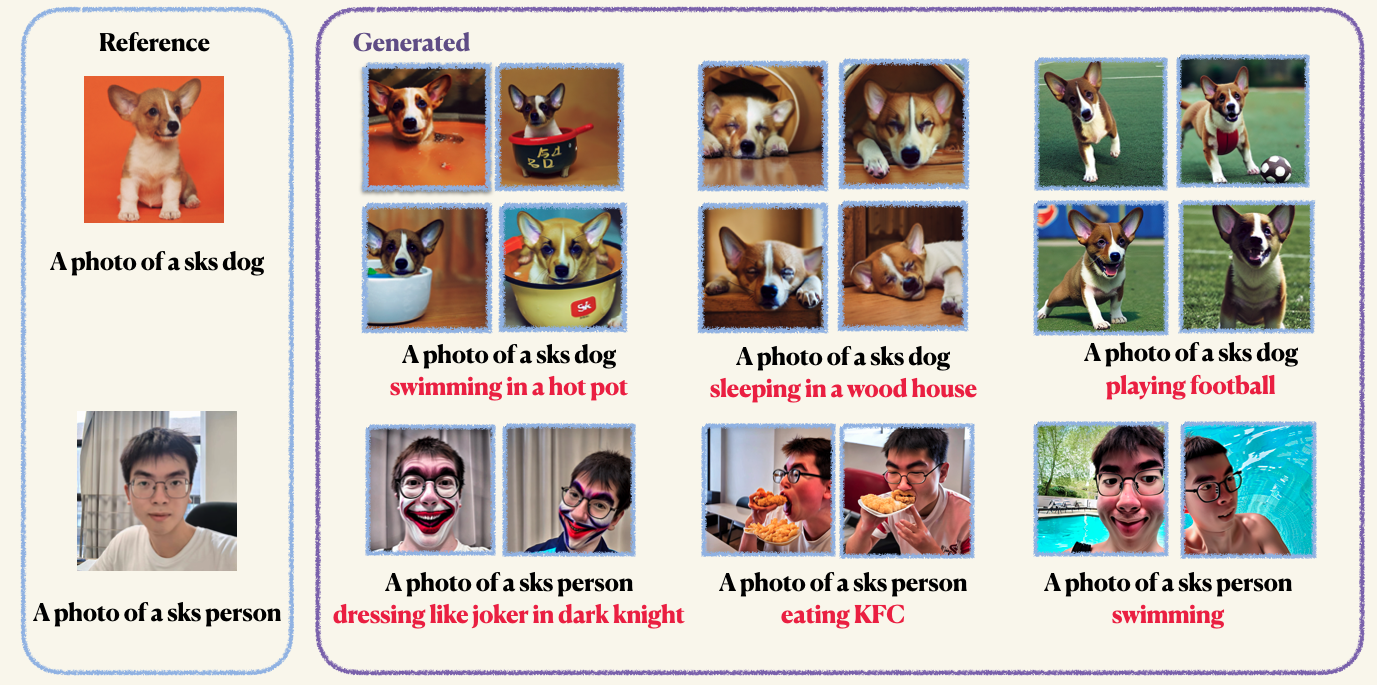
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 : Bereiten Sie Ihre benutzerdefinierten Bilder vor und legen Sie sie in einen Ordner. Normalerweise reichen 5 bis 10 Bilder aus. Wir empfehlen Ihnen, die Bilder auf die gleiche Größe zu beschneiden, z. B. 512x512, um unerwünschte Artefakte zu vermeiden.Step2 : Initialisieren Sie eine Beschleunigungsumgebung. Accelerate ist eine Pytorch-Bibliothek, die den Prozess der Einführung von Multi-GPU-Schulungs- und Bewertungsjobs vereinfacht. Es wird durch Umarmung entwickelt. accelerate configStep3 : Führen Sie das Trainingsskript aus. Beide Kontrollpunkte und Beispiele werden im Ordner work_dirs gespeichert. Normalerweise dauert es nur 1-2 Minuten, um das Modell mit nur 8 GB GPU-Memoroccup-Stimmen zu optimieren . 150 Epochen reichen aus, um ein Objekt auszubilden. Wenn wir jedoch beim Training auf menschlichem Gesicht Sie für 800 Epochen trainieren. Die Hyper-Parameter von Dreambooth sind sehr sensibel, Sie können sich auf den Original-Blog verweisen, um einige Erkenntnisse zu erhalten. accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4Die Vorbehandlung wird verwendet, um Überanpassung und Sprachdrift zu vermeiden (schauen Sie sich das Papier an, um mehr zu erfahren, wenn Sie interessiert sind). Für die vorherige Erhaltung verwenden Sie andere Bilder derselben Klasse als Teil des Trainingsprozesses. Das Schöne ist, dass Sie diese Bilder mit dem stabilen Diffusionsmodell selbst generieren können! Das Trainingsskript speichert die generierten Bilder in einem lokalen Pfad, den Sie angegeben haben.
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10Sie können den Text-Encoder (Clip) mit Lora fein stimmen. Wir finden jedoch, dass dies zu nicht konvergierten Ergebnissen führt. Dieses Phänomen ist entgegengesetzt zu den in der ursprünglichen Implementierung angegebenen Ergebnisse
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4Nach dem Training können Sie den folgenden Befehl verwenden, um Bilder aus einer Eingabeaufforderung zu generieren. Wir bieten auch einen vorbereiteten Kontrollpunkt für den Hund (im Beispiel)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

