Structured_Dreambooth_LoRA
1.0.0
models , datasets , engines , tools , utils , para que sea más legible y mantenible, y se puede extender fácilmente a otras tareas.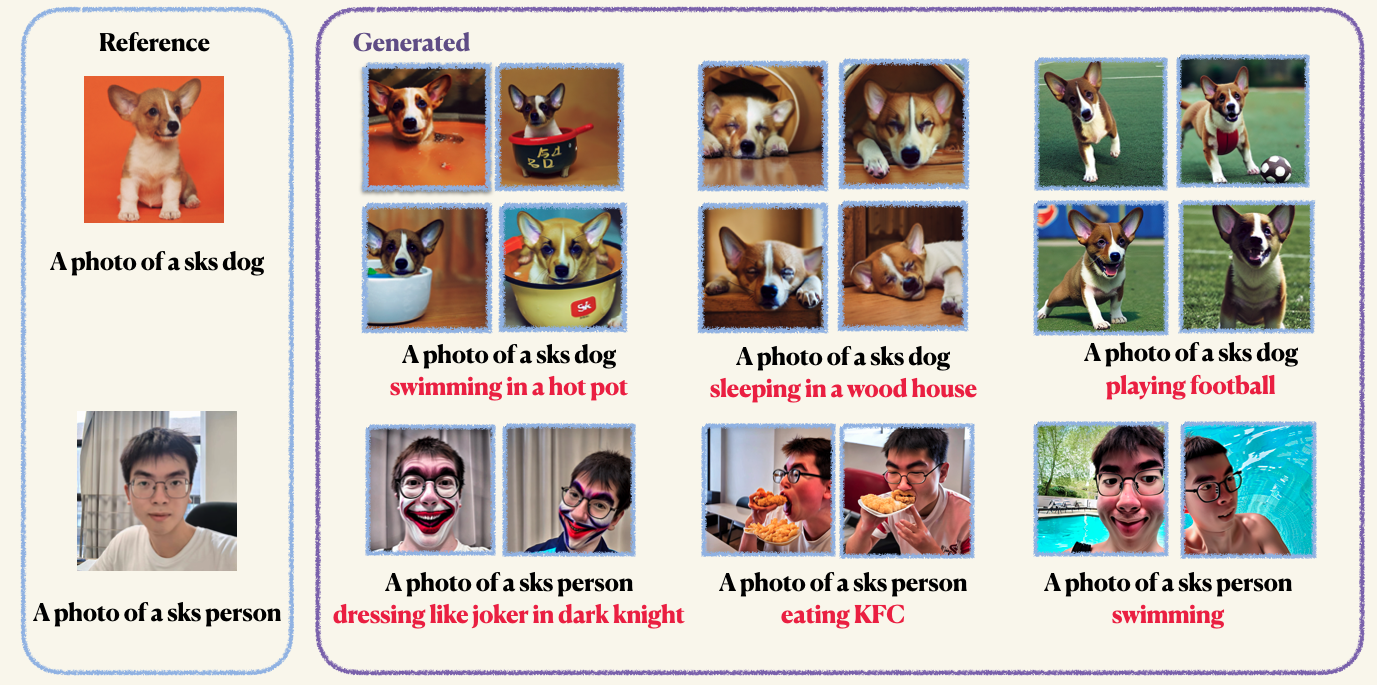
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 : Prepare sus imágenes personalizadas y colóquelas en una carpeta. Normalmente, 5 a 10 imágenes son suficientes. Le recomendamos que recorte mannUally las imágenes al mismo tamaño, por ejemplo, 512x512, para evitar artefactos no deseados.Step2 : Inicializar un entorno de aceleración. Accelerate es una biblioteca de Pytorch que simplifica el proceso de lanzamiento de trabajos de capacitación y evaluación de múltiples GPU. Está desarrollado por abrazar la cara. accelerate configStep3 : Ejecute el guión de entrenamiento. Tanto los puntos de control como las muestras se guardarán en la carpeta work_dirs . Normalmente, solo lleva 1-2 minutos ajustar el modelo con solo 8 GB de GPU memoroccupied . 150 épocas son suficientes para entrenar un objeto, sin embargo, al entrenar en la cara humana, le recomendamos que entren a entrenar para 800 épocas. Los hiperparametros de Dreambooth son bastante sensibles, puede consultar el blog original para obtener algunas ideas. accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4La preservación previa se usa para evitar el sobreajuste y la deriva del idioma (consulte el documento para obtener más información si está interesado). Para la preservación previa, utiliza otras imágenes de la misma clase que parte del proceso de capacitación. ¡Lo bueno es que puedes generar esas imágenes usando el modelo de difusión estable en sí! El script de capacitación guardará las imágenes generadas en una ruta local que especifique.
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10Puede ASLO ANINE EL CODER DE TEXTO (Clip) con Lora. Sin embargo, encontramos que esto conduce a resultados no convergentes. Este fenómeno es opuesto a los resultados informados en la implementación original.
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4Después del entrenamiento, puede usar el siguiente comando para generar imágenes a partir de un aviso. También proporcionamos un punto de control preventivo para el perro (en el ejemplo)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

