Structured_Dreambooth_LoRA
1.0.0
models , datasets , engines , tools , utils , pour le rendre plus lisible et maintenable, et peut être facilement étendu à d'autres tâches.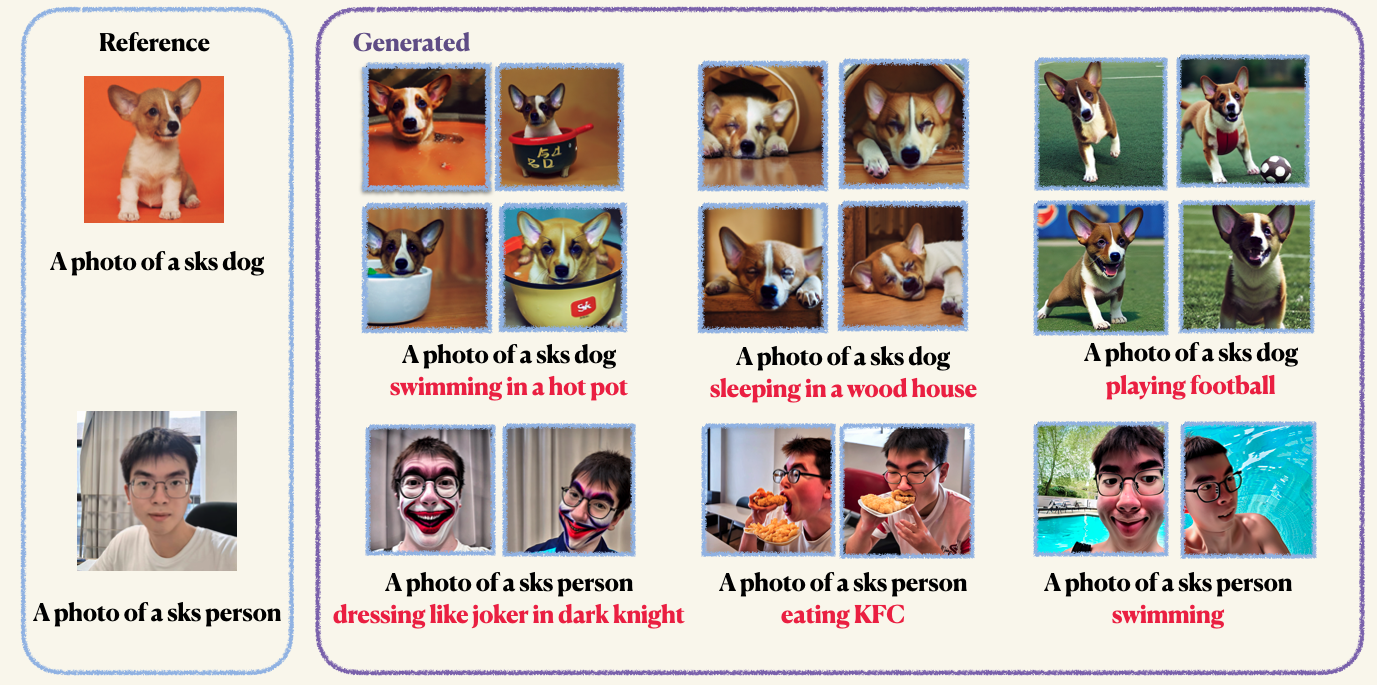
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 : Préparez vos images personnalisées et placez-les dans un dossier. Normalement, 5 à 10 images suffisent. Nous vous recommandons de recadrer les images à mannu à la même taille, par exemple, 512x512, pour éviter les artefacts indésirables.Step2 : Initialisez un environnement accéléré. Accelerate est une bibliothèque Pytorch qui simplifie le processus de lancement de travaux de formation et d'évaluation multi-GPU. Il est développé en étreignant le visage. accelerate configStep3 : Exécutez le script d'entraînement. Les points de contrôle et les échantillons seront enregistrés dans le dossier work_dirs . Normalement, il ne faut que 1 à 2 minutes pour affiner le modèle avec seulement 8 Go GPU mémorisé . 150 époques sont suffisantes pour former un objet, cependant, lors de la formation sur le visage humain, nous vous recommandons de vous entraîner pour 800 époques. Les hyper-paramètres de Dreambooth sont assez sensibles, vous pouvez vous référer au blog original pour quelques idées. accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4La préservation antérieure est utilisée pour éviter le sur-ajustement et la dérive du langage (consultez le document pour en savoir plus si vous êtes intéressé). Pour la préservation antérieure, vous utilisez d'autres images de la même classe dans le cadre du processus de formation. La bonne chose est que vous pouvez générer ces images en utilisant le modèle de diffusion stable lui-même! Le script de formation enregistrera les images générées sur un chemin local que vous spécifiez.
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10Vous pouvez faire affiner l'encodeur de texte (clip) avec Lora. Cependant, nous constatons que cela conduit à des résultats non vergnés. Ce phénomène est opposé aux résultats rapportés dans la mise en œuvre d'origine
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4Après la formation, vous pouvez utiliser la commande suivante pour générer des images à partir d'une invite. Nous fournissons également un point de contrôle pré-entraîné pour le chien (dans l'exemple)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

