Structured_Dreambooth_LoRA
1.0.0
models , datasets , engines , tools , utils 포함한 다른 모듈로 다시 구조화하여 더 읽기 쉽고 관리 가능하며 다른 작업으로 쉽게 확장 할 수 있습니다.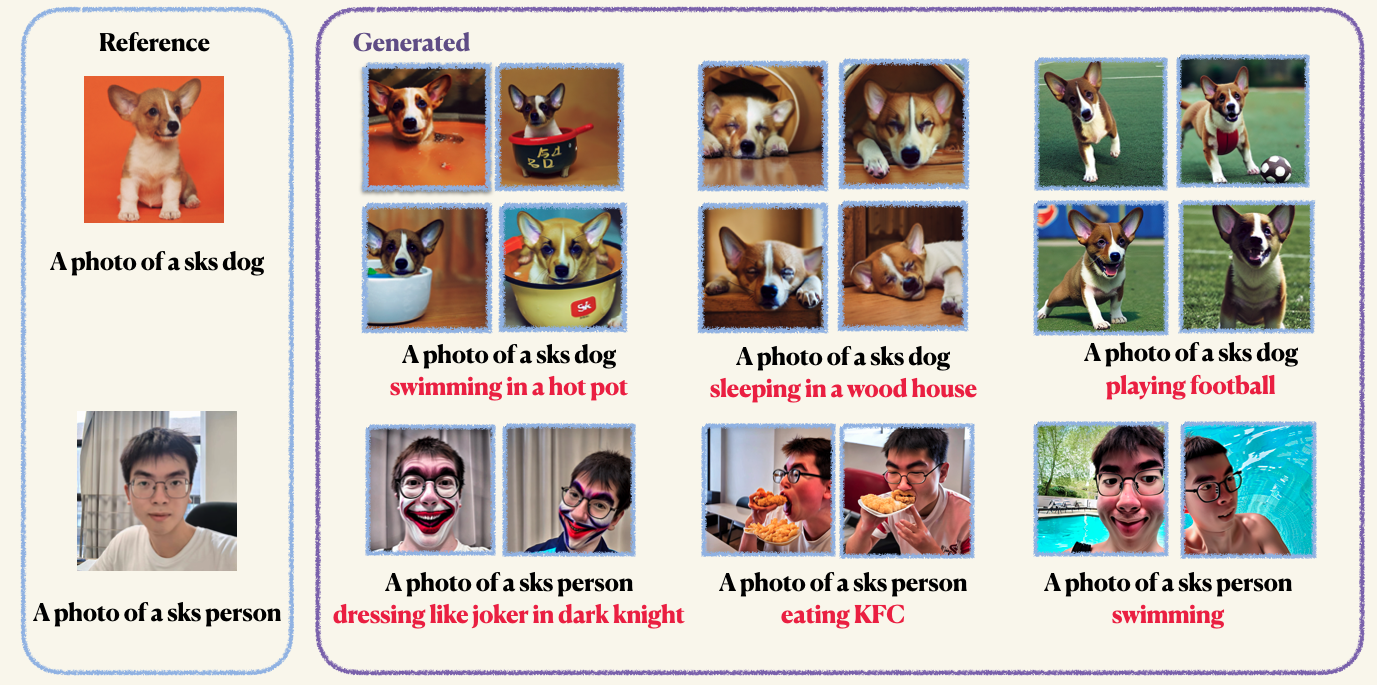
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 : 사용자 정의 이미지를 준비하고 폴더에 넣으십시오. 일반적으로 5 ~ 10 개의 이미지로 충분합니다. 원치 않는 인공물을 피하기 위해 이미지를 같은 크기 (512x512와 같은 크기로 잘라내는 것이 좋습니다.Step2 : 가속 환경을 초기화하십시오. Accelerate는 다중 GPU 교육 및 평가 작업을 시작하는 프로세스를 단순화하는 Pytorch 라이브러리입니다. 얼굴을 껴안아 개발되었습니다. accelerate configStep3 : 훈련 스크립트를 실행하십시오. 체크 포인트와 샘플은 모두 work_dirs 폴더에 저장됩니다. 일반적으로 8GB gpu memoroccupied로 모델을 미세 조정하는 데 1-2 분 밖에 걸리지 않습니다 . 150 에포크는 물체를 훈련시키기에 충분하지만 인간의 얼굴을 훈련시 800 개의 에포크를 훈련하는 것이 좋습니다. Dreambooth의 하이퍼 파라미터는 상당히 민감하며, 원래 블로그를 참조하여 몇 가지 통찰력을 얻을 수 있습니다. accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4사전 보존은 오버 피트팅 및 언어 중심을 피하기 위해 사용됩니다 (관심이있는 경우 자세한 내용은 논문을 확인하십시오). 사전 보존의 경우 교육 과정의 일부와 동일한 클래스의 다른 이미지를 사용합니다. 좋은 점은 안정적인 확산 모델 자체를 사용하여 해당 이미지를 생성 할 수 있다는 것입니다! 교육 스크립트는 생성 된 이미지를 지정한 로컬 경로에 저장합니다.
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10lora로 텍스트 인코더 (클립)를 미세 조정할 수 있습니다. 그러나 우리는 이것이 변하지 않은 결과로 이어진다는 것을 알게됩니다. 이 현상은 원래 구현에서보고 된 결과와 반대입니다.
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4교육 후 다음 명령을 사용하여 프롬프트에서 이미지를 생성 할 수 있습니다. 우리는 또한 개에 대한 사전 검사 점을 제공합니다 (예에서)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

