Structured_Dreambooth_LoRA
1.0.0
models , datasets , engines , tools , utils , чтобы сделать его более читаемым и поддерживать, и может быть легко распространено на другие задачи.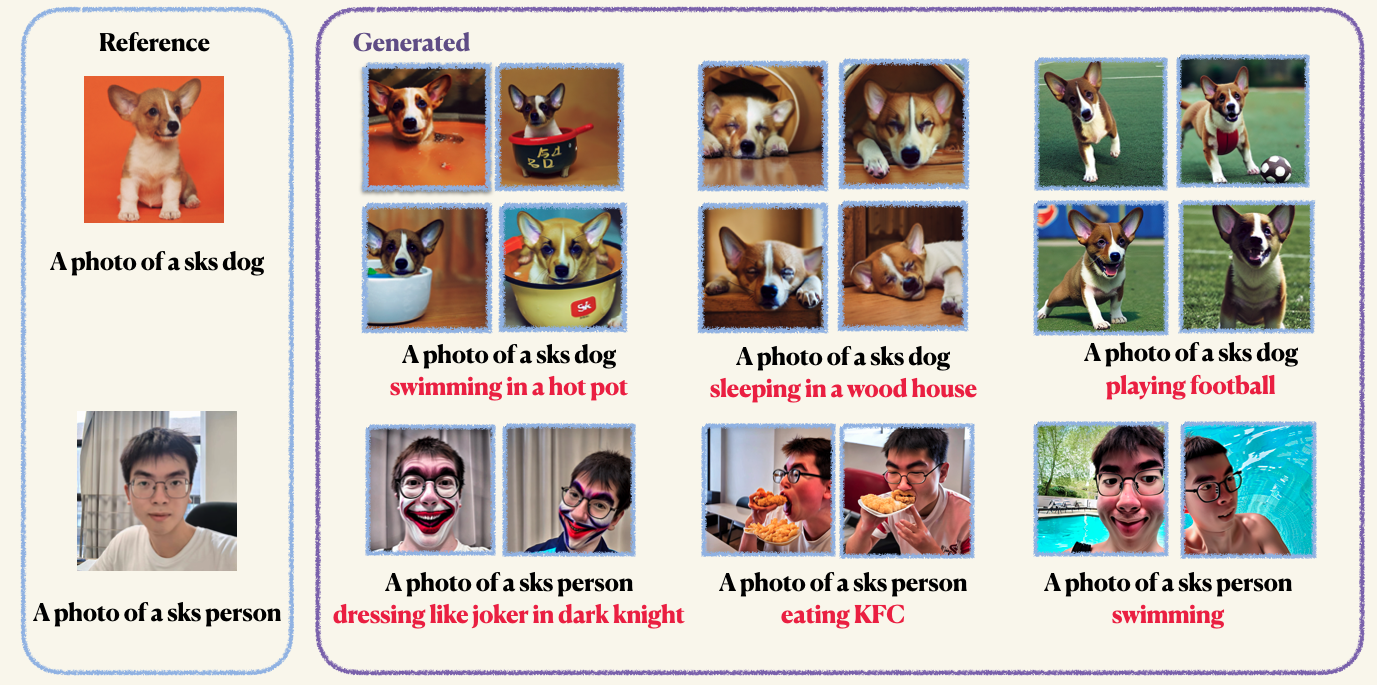
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 : Приготовьте свои пользовательские изображения и поместите их в папку. Обычно от 5 до 10 изображений достаточно. Мы рекомендуем вам Mannually Count -изображения до того же размера, например, 512x512, чтобы избежать нежелательных артефактов.Step2 : Инициализируйте среду ускорения. AcceLerate-это библиотека Pytorch, которая упрощает процесс запуска мульти-GPU обучения и оценки. Это разработано, обнимая лицо. accelerate configStep3 : Запустите сценарий обучения. Как контрольные точки, так и образцы будут сохранены в папке work_dirs . Обычно, для точной настройки модели требуется всего 1-2 минуты с помощью Memorockepled только 8 ГБ GPU . 150 эпох достаточно, чтобы тренировать объект, однако, когда тренируемся на человеческом лице, мы рекомендуем вам тренироваться на 800 эпох. Гиперпараметры Dreambooth довольно чувствительны, вы можете ссылаться на оригинальный блог для некоторых знаний. accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4Предыдущая сохранение используется, чтобы избежать переосмысления и дрейфа языка (проверьте бумагу, чтобы узнать больше, если вам интересно). Для предыдущего сохранения вы используете другие изображения того же класса в качестве часть учебного процесса. Приятно то, что вы можете генерировать эти изображения, используя саму стабильную диффузионную модель! Сценарий обучения сохранит сгенерированные изображения на локальном пути, который вы указали.
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10Вы можете точно настроить текстовый энкодер (клип) с Лорой. Однако мы находим, что это приводит к неревернутым результатам. Это явление противоположно результатам, представленным в исходной реализации
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4После обучения вы можете использовать следующую команду для генерации изображений из приглашения. Мы также предоставляем предварительную контрольную точку для собаки (в примере)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

