Structured_Dreambooth_LoRA
1.0.0
models datasets engines tools utils ، لجعلها أكثر قابلية للقراءة والصيانة ، ويمكن تمديدها بسهولة إلى مهام أخرى.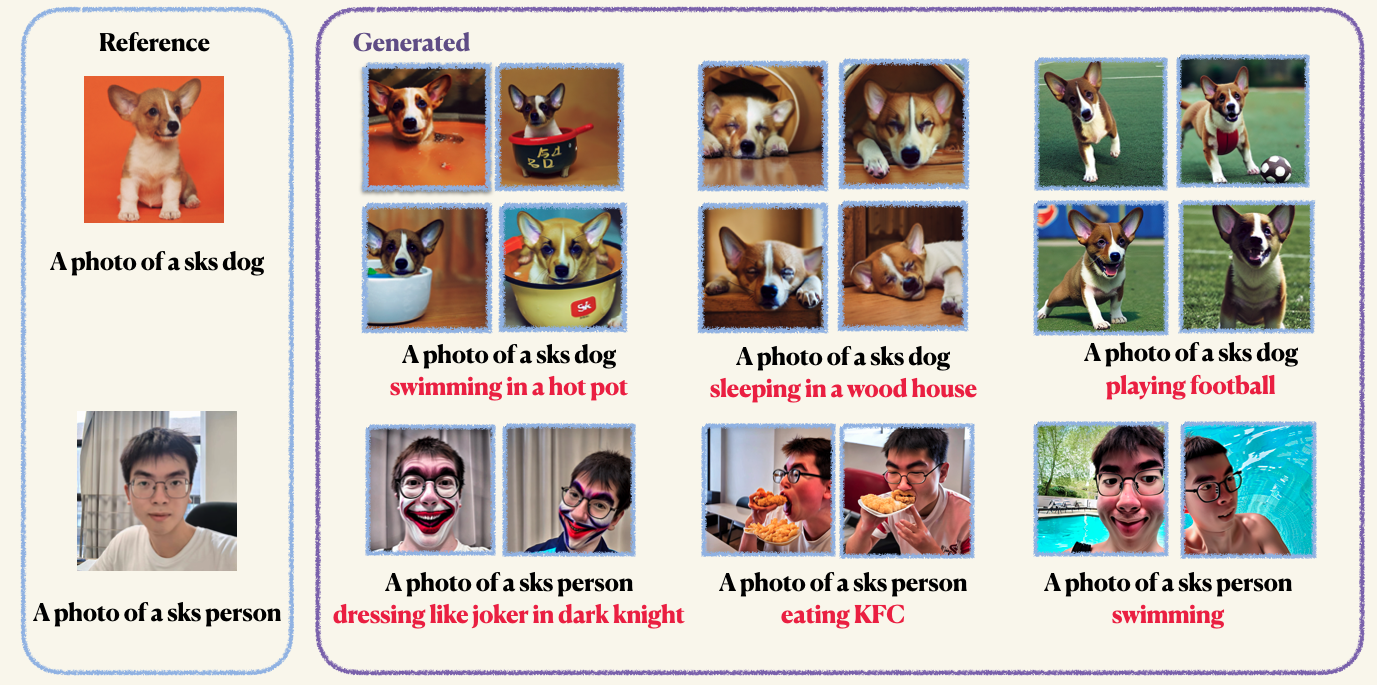
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 : قم بإعداد صورك المخصصة ووضعها في مجلد. عادة ، 5 إلى 10 صور كافية. نوصيك بتقديم الصور التماوية بنفس الحجم ، على سبيل المثال ، 512x512 ، لتجنب القطع الأثرية غير المرغوب فيها.Step2 : تهيئة بيئة تسريع. Accelerate هي مكتبة Pytorch التي تبسط عملية إطلاق وظائف التدريب والتقييم متعددة GPU. تم تطويره عن طريق معانقة الوجه. accelerate configStep3 : تشغيل البرنامج النصي التدريبي. سيتم حفظ كل من نقاط التفتيش والعينات في مجلد work_dirs . عادة ، لا يستغرق الأمر سوى 1-2 دقائق لضبط النموذج مع مذكرات GPU 8 جيجا بايت فقط . 150 حقبة تكفي لتدريب كائن ، ومع ذلك ، عند التدريب على الوجه البشري ، نوصيك بالتدريب على 800 عصر. إن المعلمات المفرطة في Dreambooth حساسة للغاية ، يمكنك الرجوع إلى المدونة الأصلية للحصول على بعض الأفكار. accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4يتم استخدام الحفاظ المسبق لتجنب الإفراط في التنقل والغسل (تحقق من الورقة لمعرفة المزيد إذا كنت مهتمًا). للحفاظ المسبق ، يمكنك استخدام صور أخرى لنفس الفصل كجزء من عملية التدريب. الشيء الجميل هو أنه يمكنك إنشاء تلك الصور باستخدام نموذج الانتشار المستقر نفسه! سيحفظ البرنامج النصي التدريبي الصور التي تم إنشاؤها إلى مسار محلي تحدده.
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10يمكنك أن تقوم بتصنيع مشفر النص (مقطع) مع Lora. ومع ذلك نجد هذا يؤدي إلى نتائج غير محددة. هذه الظاهرة عكس النتائج الواردة في التنفيذ الأصلي
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4بعد التدريب ، يمكنك استخدام الأمر التالي لإنشاء صور من مطالبة. نحن نقدم أيضًا نقطة تفتيش مسبق للكلب (في المثال)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

