Structured_Dreambooth_LoRA
1.0.0
models , datasets , engines , tools , utils , untuk membuatnya lebih mudah dibaca dan dipelihara, dan dapat dengan mudah diperluas ke tugas lain.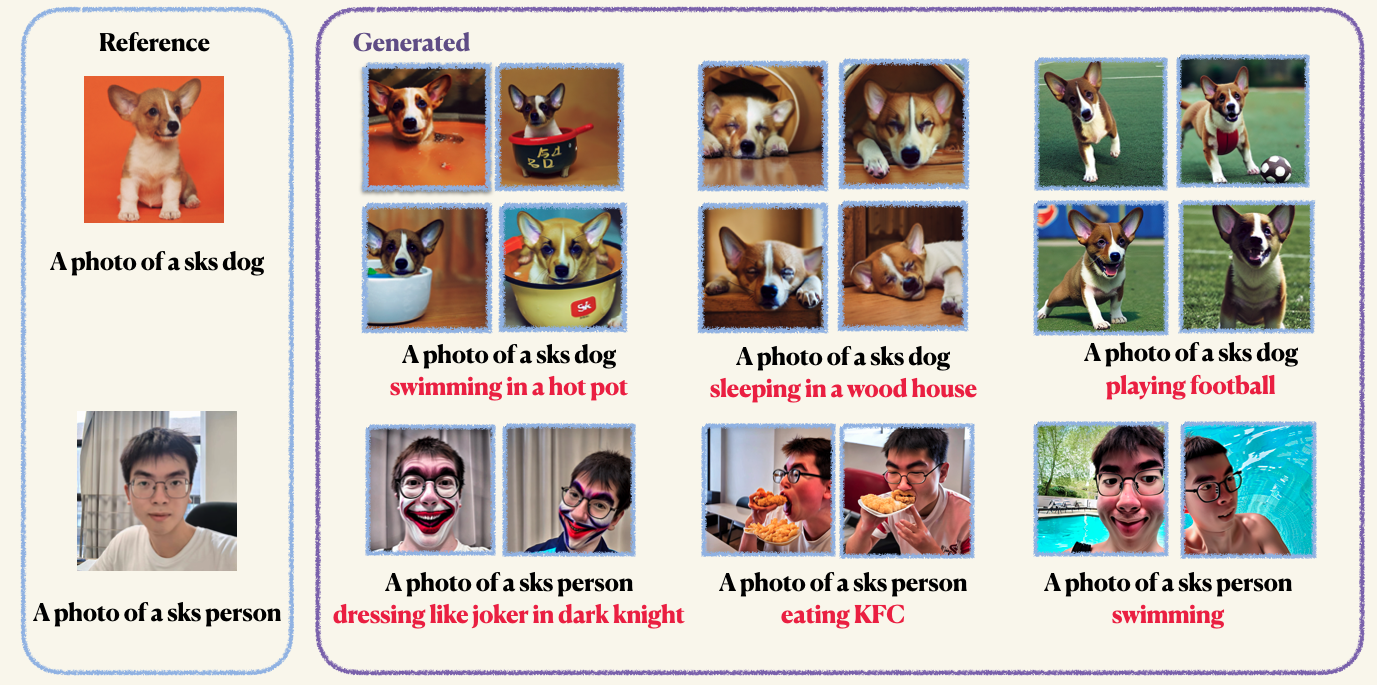
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 : Siapkan gambar khusus Anda dan masukkan ke dalam folder. Biasanya, 5 hingga 10 gambar sudah cukup. Kami menyarankan Anda untuk memangkas gambar dengan ukuran yang sama, misalnya, 512x512, untuk menghindari artefak yang tidak diinginkan.Step2 : Inisialisasi lingkungan yang dipercepat. Accelerate adalah perpustakaan Pytorch yang menyederhanakan proses meluncurkan pelatihan multi-GPU dan pekerjaan evaluasi. Ini dikembangkan dengan memeluk wajah. accelerate configStep3 : Jalankan skrip pelatihan. Kedua pos pemeriksaan dan sampel akan disimpan di folder work_dirs . Biasanya, hanya dibutuhkan 1-2 menit untuk menyempurnakan model dengan hanya 8GB GPU yang memori . 150 zaman sudah cukup untuk melatih objek, namun, saat berlatih di wajah manusia, kami sarankan Anda untuk berlatih 800 zaman. Hyper-parameter dari DreamBooth cukup sensitif, Anda dapat merujuk ke blog asli untuk beberapa wawasan. accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4Pelestarian sebelumnya digunakan untuk menghindari overfitting dan drift bahasa (lihat makalah untuk mempelajari lebih lanjut jika Anda tertarik). Untuk pelestarian sebelumnya, Anda menggunakan gambar lain dari kelas yang sama sebagai bagian dari proses pelatihan. Yang menyenangkan adalah Anda dapat menghasilkan gambar -gambar itu menggunakan model difusi stabil itu sendiri! Script pelatihan akan menyimpan gambar yang dihasilkan ke jalur lokal yang Anda tentukan.
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10Anda tidak bisa menyempurnakan encoder teks (klip) dengan lora. Namun kami menemukan ini mengarah pada hasil yang tidak bertumpu. Fenomena ini berlawanan dengan hasil yang dilaporkan dalam implementasi asli
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4Setelah pelatihan, Anda dapat menggunakan perintah berikut untuk menghasilkan gambar dari prompt. Kami juga menyediakan pos pemeriksaan pretrained untuk anjing (dalam contoh)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

