Structured_Dreambooth_LoRA
1.0.0
models 、 datasets 、 engines 、 tools 、 utilsを含むさまざまなモジュールに元のコードを再構築して、より読みやすく保守可能にし、他のタスクに簡単に拡張できます。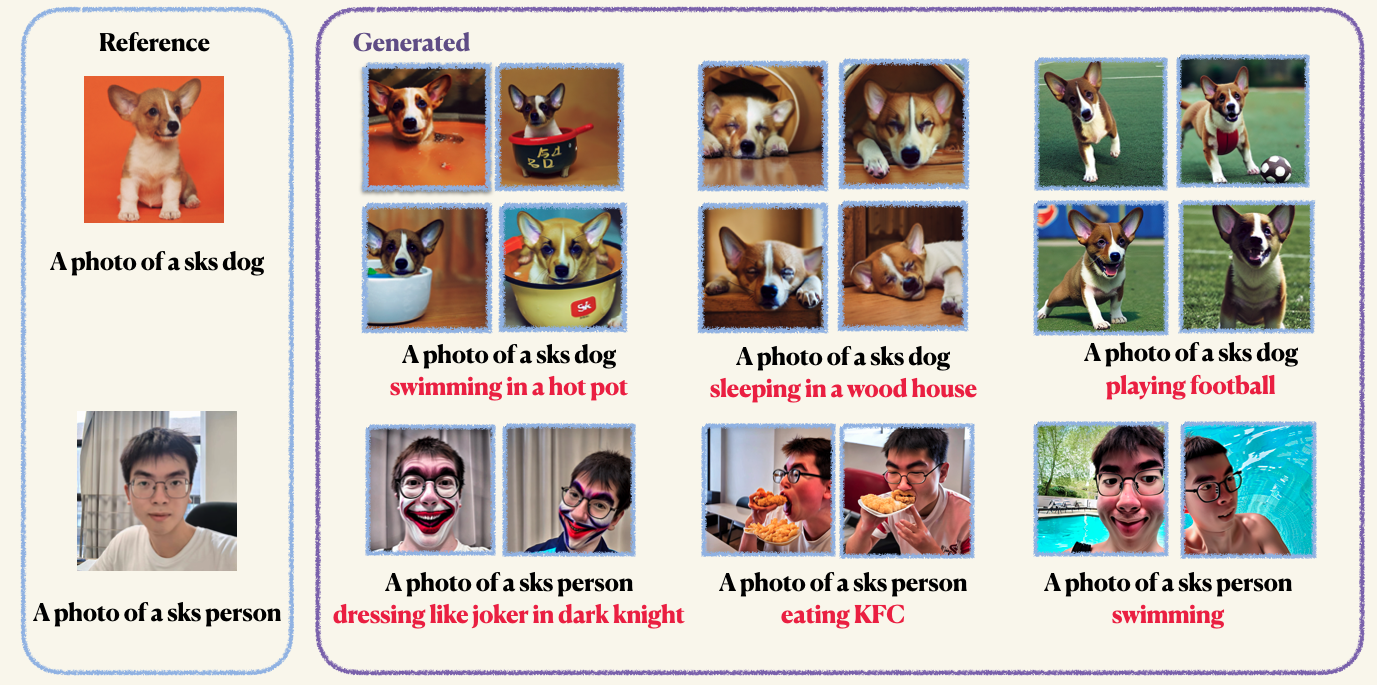
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 :カスタム画像を準備し、フォルダーに入れます。通常、5〜10個の画像で十分です。不要なアーティファクトを避けるために、たとえば512x512などの同じサイズに画像をmannualllyに収集することをお勧めします。Step2 :加速環境を初期化します。 Accelerateは、マルチGPUトレーニングと評価ジョブを立ち上げるプロセスを簡素化するPytorchライブラリです。顔を抱きしめて開発されています。 accelerate configStep3 :トレーニングスクリプトを実行します。チェックポイントとサンプルの両方が、 work_dirsフォルダーに保存されます。通常、モデルを微調整するのにわずか1〜2分かかり、8GB GPUの記憶しかありません。 150エポックはオブジェクトを訓練するのに十分ですが、人間の顔を訓練するときは、800エポックのためにトレーニングすることをお勧めします。 DreamBoothのハイパーパラメーターは非常に敏感です。いくつかの洞察については、元のブログを参照できます。 accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4過剰適合と言語の漂流を避けるために、事前の保存が使用されます(興味があれば詳細を確認するために論文をチェックしてください)。以前の保存には、トレーニングプロセスの一部と同じクラスの他の画像を使用します。良いことは、安定した拡散モデル自体を使用してそれらの画像を生成できることです!トレーニングスクリプトは、生成された画像を指定したローカルパスに保存します。
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10テキストエンコーダー(クリップ)をLORAで微調整できます。ただし、これはvervedされていない結果につながることがわかります。この現象は、元の実装で報告されている結果とは反対です
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4トレーニング後、次のコマンドを使用して、プロンプトから画像を生成できます。また、犬の前提条件のチェックポイントも提供します(例で)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

