Structured_Dreambooth_LoRA
1.0.0
models datasets engines tools utils เพื่อให้สามารถอ่านและบำรุงรักษาได้มากขึ้นและสามารถขยายไปยังงานอื่นได้อย่างง่ายดาย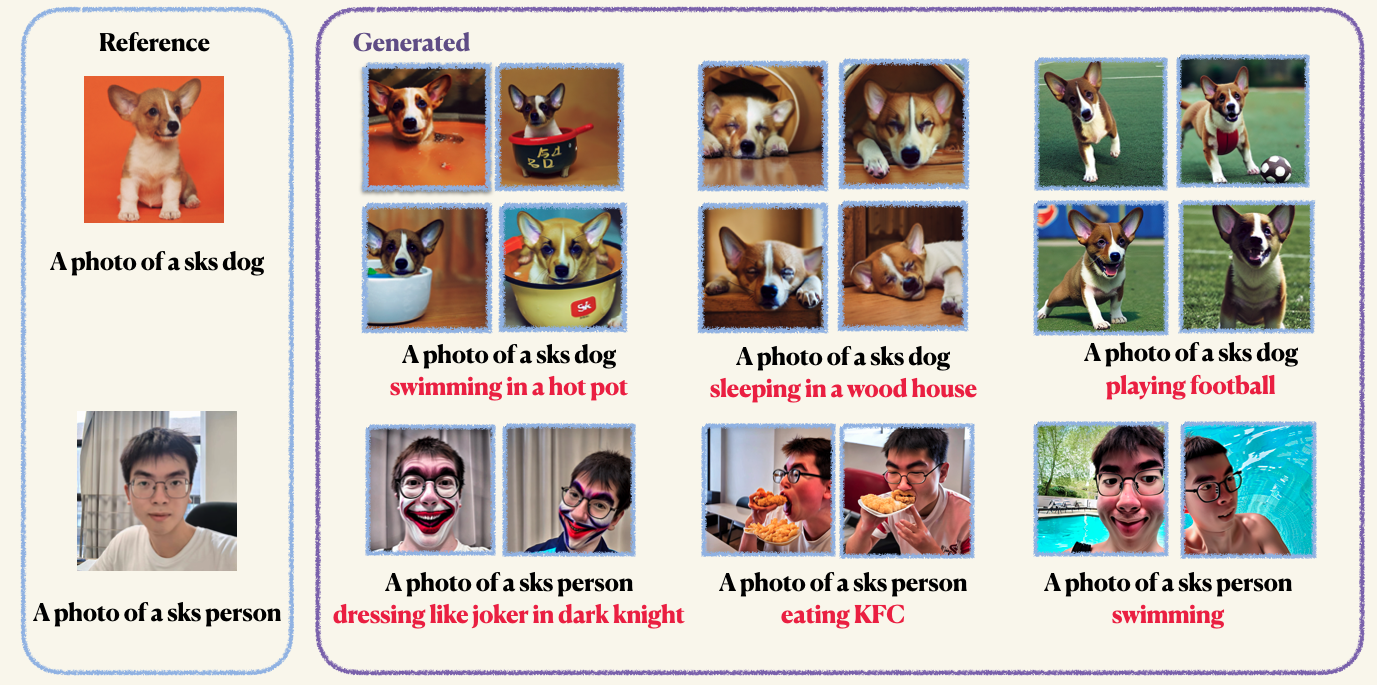
conda create -n dreambooth python=3.8
conda activate dreambooth
# install pytorch
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# install diffusers from source
pip install git+https://github.com/huggingface/diffusers
pip install -r requirements.txtStep1 : เตรียมภาพที่กำหนดเองของคุณและวางไว้ในโฟลเดอร์ โดยปกติแล้ว 5 ถึง 10 ภาพก็เพียงพอแล้ว เราขอแนะนำให้คุณใช้ภาพ Mannuallly ให้มีขนาดเท่ากันเช่น 512x512 เพื่อหลีกเลี่ยงสิ่งประดิษฐ์ที่ไม่พึงประสงค์Step2 : เริ่มต้นสภาพแวดล้อมเร่งความเร็ว Accelerate เป็นห้องสมุด Pytorch ที่ทำให้กระบวนการเปิดใช้งานการฝึกอบรมและการประเมินผลแบบหลาย GPU ง่ายขึ้น มันได้รับการพัฒนาโดยการกอดใบหน้า accelerate configStep3 : เรียกใช้สคริปต์การฝึกอบรม ทั้งจุดตรวจและตัวอย่างจะถูกบันทึกไว้ในโฟลเดอร์ work_dirs โดยปกติจะใช้เวลาเพียง 1-2 นาทีในการปรับแต่งโมเดลด้วยการบันทึก GPU 8GB เพียง 8GB 150 Epochs นั้นเพียงพอที่จะฝึกฝนวัตถุอย่างไรก็ตามเมื่อฝึกบนใบหน้าของมนุษย์เราขอแนะนำให้คุณฝึกฝน 800 Epochs พารามิเตอร์ไฮเปอร์ของ Dreambooth ค่อนข้างอ่อนไหวคุณสามารถอ้างถึงบล็อกดั้งเดิมสำหรับข้อมูลเชิงลึกบางอย่าง accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4การเก็บรักษาก่อนหน้านี้ใช้เพื่อหลีกเลี่ยงการล้นและการดริฟท์ภาษา (ตรวจสอบกระดาษเพื่อเรียนรู้เพิ่มเติมหากคุณสนใจ) สำหรับการอนุรักษ์ก่อนหน้านี้คุณใช้ภาพอื่น ๆ ของคลาสเดียวกันเป็นส่วนหนึ่งของกระบวนการฝึกอบรม สิ่งที่ดีคือคุณสามารถสร้างภาพเหล่านั้นโดยใช้โมเดลการแพร่กระจายที่เสถียรเอง! สคริปต์การฝึกอบรมจะบันทึกภาพที่สร้างขึ้นไปยังเส้นทางท้องถิ่นที่คุณระบุ
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 10คุณสามารถปรับแต่งตัวเข้ารหัสข้อความ (คลิป) ด้วย Lora อย่างไรก็ตามเราพบว่าสิ่งนี้นำไปสู่ผลลัพธ์ที่ไม่ตรงไปตรงมา ปรากฏการณ์นี้ตรงข้ามกับผลลัพธ์ที่รายงานในการดำเนินการดั้งเดิม
accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--instance_data_dir= " imgs/dogs "
--instance_prompt= " a photo of sks dog "
--validation_prompt= " a photo of sks dog is swimming "
--with_prior_preservation
--train_text_encoder
--class_prompt== ' a photo of dog '
--resolution=512
--train_batch_size=1
--gradient_accumulation_steps=1
--learning_rate=2e-4
--max_train_steps=150
--validation_epochs 4หลังจากการฝึกอบรมคุณสามารถใช้คำสั่งต่อไปนี้เพื่อสร้างภาพจากพรอมต์ นอกจากนี้เรายังมีจุดตรวจสอบสำหรับสุนัข (ในตัวอย่าง)
wget https://github.com/Mountchicken/Structured_Dreambooth_LoRA/releases/download/checkpoint_dog/checkpoint-200.zip
unzip -q checkpoint-200.zip accelerate launch main.py
--pretrained_model_name_or_path= " runwayml/stable-diffusion-v1-5 "
--checkpoint_dir= " checkpoint-200 "
--prompt= " A photo of sks dog is swimming
--output_dir= $OUTPUT_DIR 

