ChatGLM Efficient Tuning
v0.1.5:
微调?chatglm-6b型号使用?peft。
加入我们的微信。
[英语| 中文]]
如果您有任何疑问,请参考我们的Wiki?
将来将无法维持此存储库。请关注Llama-Factory进行微调语言模型(包括ChatGLM2-6B)。
[23/07/15]现在,我们开发了一个全in-In-In-In-in-In-Web UI用于培训,评估和推理。尝试使用train_web.py在网络浏览器中微调chatglm-6b型号。感谢@kanadesiina和@codemayq在开发方面所做的努力。
[23/07/09]现在,我们发布了一个易于使用的包装,用于有效地编辑大型语言模型的事实知识。如果您有兴趣,请关注Fastedit。
[23/06/25]现在,我们将演示API与OpenAI的格式保持一致,您可以在基于任意ChatGPT的应用程序中插入微型模型。
[23/06/25]现在,我们使用我们的框架来支持chatglm2-6b型号的微调!
[23/06/05]现在,我们支持4位LORA培训(又名Qlora)。尝试--quantization_bit 4参数与4位量化模型一起使用。 (实验特征)
[23/06/01]我们实施了一个框架,以支持Llama和Bloom模型的有效调整。如果您有兴趣,请关注骆驼效率调节。
[23/05/19]现在,我们支持使用开发集在训练时评估模型。尝试--dev_ratio参数指定开发集的大小。
[23/04/29]现在,我们通过人为反馈(RLHF)支持培训ChatGlm!我们提供了几个进行RLHF培训的示例,请参阅examples文件夹以获取详细信息。
[23/04/20]我们的回购在12天内达到了100颗星!恭喜!
[23/04/19]现在,我们支持合并由洛拉(Lora)训练的微型模型的权重!尝试--checkpoint_dir checkpoint1,checkpoint2参数以不断调整模型。
[23/04/18]现在,我们支持使用三种微调方法训练量化模型!尝试使用4/8位训练模型的quantization_bit参数。
[23/04/12]现在我们支持检查点的培训!使用--checkpoint_dir参数指定要从中微调的检查点模型。
[23/04/11]现在我们支持组合数据集的培训!尝试--dataset dataset1,dataset2参数。
有关详细信息,请参阅数据/readme.md。
一些数据集在使用之前需要确认,因此我们建议使用这些命令使用拥抱面帐户登录。
pip install --upgrade huggingface_hub
huggingface-cli login我们的脚本现在支持以下微调方法:
和强大的GPU !
请参阅data/example_dataset ,以检查有关数据集文件格式的详细信息。您可以使用一个.json文件或带有多个文件的数据集加载脚本来创建自定义数据集。
注意:请更新data/dataset_info.json以使用您的自定义数据集。关于此文件的格式,请参阅data/README.md 。
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt如果要在Windows平台上启用量化的Lora(Qlora),则需要安装支持CUDA 11.1至12.1的bitsandbytes库的预构建版本。
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.py当前,Web UI仅支持单个GPU的培训。
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16请参考我们的Wiki有关论点的详细信息。
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate如果您想预测具有空响应的样本,请用虚拟令牌填充response列,以确保在整个预处理阶段不会丢弃样本。
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint访问http://localhost:8000/docs用于API文档。
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| 微调方法 | 批量大小 | 模式 | 克 | 速度 |
|---|---|---|---|---|
| 洛拉(r = 8) | 16 | FP16 | 28GB | 8Ex/s |
| 洛拉(r = 8) | 8 | FP16 | 24GB | 8Ex/s |
| 洛拉(r = 8) | 4 | FP16 | 20GB | 8Ex/s |
| 洛拉(r = 8) | 4 | INT8 | 10GB | 8Ex/s |
| 洛拉(r = 8) | 4 | INT4 | 8GB | 8Ex/s |
| p-tuning(p = 16) | 4 | FP16 | 20GB | 8Ex/s |
| p-tuning(p = 16) | 4 | INT8 | 16 GB | 8Ex/s |
| p-tuning(p = 16) | 4 | INT4 | 12GB | 8Ex/s |
| 冻结(L = 3) | 4 | FP16 | 24GB | 8Ex/s |
| RM方法 | 批量大小 | 模式 | 克 | 速度 |
|---|---|---|---|---|
| 洛拉(r = 8) + rm | 4 | FP16 | 22GB | - |
| 洛拉(r = 8) + rm | 1 | INT8 | 11GB | - |
| RLHF方法 | 批量大小 | 模式 | 克 | 速度 |
|---|---|---|---|---|
| 洛拉(r = 8) + ppo | 4 | FP16 | 23GB | - |
| 洛拉(r = 8) + ppo | 1 | INT8 | 12GB | - |
注意:
r是洛拉等级,p是前缀令牌的数量,l是可训练的层的数量,ex/s是训练中每秒的示例。gradient_accumulation_steps设置为1。所有这些都在单个Tesla V100(32G)GPU上进行评估,它们是近似值,并且可能在不同的GPU中有所不同。
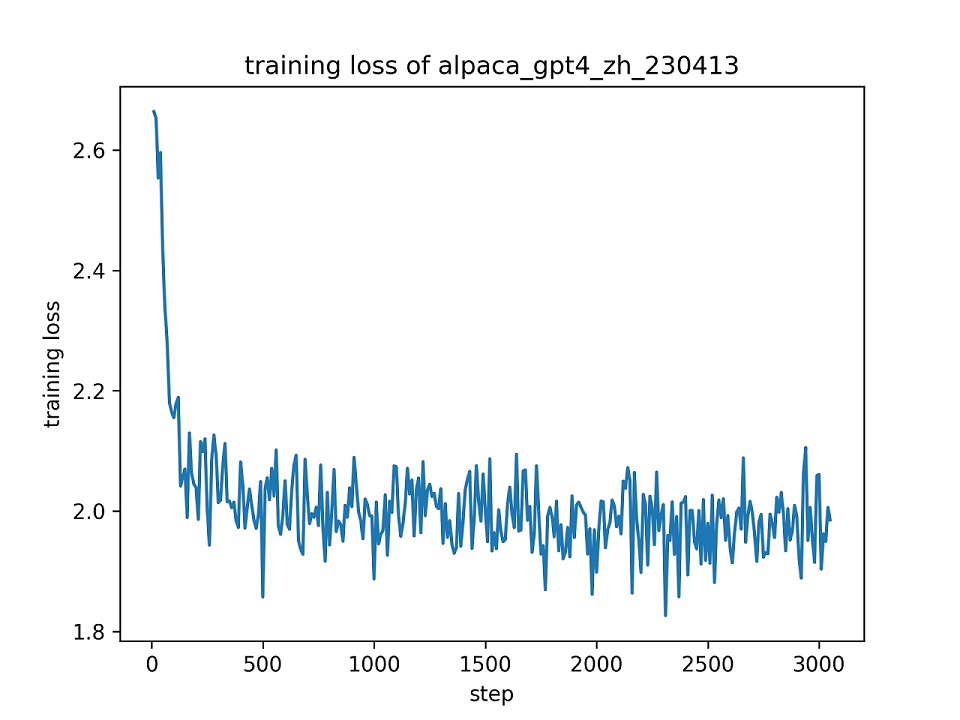
我们使用默认的超参数使用整个alpaca_gpt4_zh数据集用lora(r = 8)对Chatglm模型进行微调。下面介绍了训练期间的损失曲线。
我们在alpaca_gpt4_zh数据集中选择100个实例来评估微型ChatGLM型号并计算BLEU和Rouge分数。结果如下所示。
| 分数 | 原来的 | fz(L = 2) | pt(p = 16) | 洛拉(r = 8) |
|---|---|---|---|---|
| bleu-4 | 15.75 | 16.85 | 16.06 | 17.01( +1.26 ) |
| Rouge-1 | 34.51 | 36.62 | 34.80 | 36.77( +2.26 ) |
| Rouge-2 | 15.11 | 17.04 | 15.32 | 16.83( +1.72 ) |
| 胭脂-l | 26.18 | 28.17 | 26.35 | 28.86( +2.68 ) |
| 参数(%) | / | 4.35% | 0.06% | 0.06% |
FZ:冻结,PT:P-Tuning V2(我们使用
pre_seq_len=16进行与Lora的公平比较),参数:可训练参数的百分比。
该存储库是根据Apache-2.0许可证获得许可的。请遵循模型许可使用ChatGLM-6B型号。
如果这项工作有帮助,请引用为:
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}此存储库受益于ChatGLM-6B,ChatGlm-Tuning和Yuanzhoulvpi2017/Zero_NLP。感谢他们的精彩作品。


