ChatGLM Efficient Tuning
v0.1.5:
Ajuste fino? Chatglm-6b modelo con? Peft.
Únete a nuestro WeChat.
[Inglés | 中文]
Si tiene alguna pregunta, consulte nuestro wiki?.
Este repositorio no se mantendrá en el futuro. Siga la Factor de Llama para ajustar los modelos de idiomas (incluido el chatglm2-6b).
[23/07/15] Ahora desarrollamos una interfaz de usuario web todo en uno para capacitación, evaluación e inferencia. Pruebe train_web.py para ajustar el modelo CHATGLM-6B en su navegador web. Gracias a @kanadesiina y @codemayq por sus esfuerzos en el desarrollo.
[23/07/09] Ahora lanzamos Fastedit⚡?, Un paquete fácil de usar para editar el conocimiento fáctico de modelos de idiomas grandes de manera eficiente. Siga Fastedit si está interesado.
[23/06/25] Ahora alineamos la API de demostración con el formato de OpenAI donde puede insertar el modelo ajustado en aplicaciones arbitrarias basadas en ChatGPT.
[23/06/25] ¡Ahora admitimos ajustar el modelo CHATGLM2-6B con nuestro marco!
[23/06/05] Ahora apoyamos la capacitación de Lora de 4 bits (también conocido como Qlora). Prueba --quantization_bit 4 Argumento para trabajar con un modelo cuantificado de 4 bits. (característica experimental)
[23/06/01] Implementamos un marco que respalda el ajuste eficiente de los modelos LLAMA y Bloom. Siga el ajuste de eficiencia de LLAMA si está interesado.
[23/05/19] Ahora apoyamos el uso del conjunto de desarrollo para evaluar el modelo mientras capacita. Pruebe --dev_ratio Argumento para especificar el tamaño del conjunto de desarrollo.
[23/04/29] ¡Ahora apoyamos la capacitación de chatglm con aprendizaje de refuerzo con comentarios humanos (RLHF) ! Brindamos varios ejemplos para ejecutar capacitación RLHF, consulte la carpeta de examples para obtener más detalles.
[23/04/20] ¡Nuestro repositorio alcanzó 100 estrellas en 12 días! ¡Felicidades!
[23/04/19] ¡Ahora apoyamos fusionar los pesos de los modelos finos entrenados por Lora! Pruebe --checkpoint_dir checkpoint1,checkpoint2 Argumento para ajustar continuamente los modelos.
[23/04/18] ¡Ahora admitimos capacitar a los modelos cuantificados utilizando tres métodos de ajuste fino! Pruebe el argumento quantization_bit para entrenar el modelo en 4/8 bits.
[23/04/12] ¡Ahora apoyamos la capacitación desde los puntos de control ! Use --checkpoint_dir argumento para especificar el modelo de punto de control para ajustar.
[23/04/11] ¡Ahora apoyamos la capacitación con conjuntos de datos combinados ! Pruebe --dataset dataset1,dataset2 Argumento para capacitar con múltiples conjuntos de datos.
Consulte Data/ReadMe.md para más detalles.
Algunos conjuntos de datos requieren confirmación antes de usarlos, por lo que recomendamos iniciar sesión con su cuenta de abrazadera de abrazo utilizando estos comandos.
pip install --upgrade huggingface_hub
huggingface-cli loginNuestro script ahora admite los siguientes métodos de ajuste:
¡Y poderosas GPU !
Consulte data/example_dataset para verificar los detalles sobre el formato de los archivos de conjunto de datos. Puede usar un solo archivo .json o un conjunto de datos de datos con múltiples archivos para crear un conjunto de datos personalizado.
Nota: Actualice data/dataset_info.json para usar su conjunto de datos personalizado. Sobre el formato de este archivo, consulte data/README.md .
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt Si desea habilitar la Lora cuantificada (Qlora) en la plataforma de Windows, se le solicitará que instale una versión preconstruida de la biblioteca bitsandbytes , que admite CUDA 11.1 a 12.1.
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.pyActualmente, la interfaz de usuario web solo admite capacitación en una sola GPU .
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16Consulte nuestro wiki sobre los detalles de los argumentos.
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate Si desea predecir las muestras con respuestas vacías, llene amablemente la columna response con tokens ficticios para asegurarse de que la muestra no se descarte en toda la fase de preprocesamiento.
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint Visite http://localhost:8000/docs para la documentación de la API.
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| Método de ajuste fino | Tamaño por lotes | Modo | GRAMO | Velocidad |
|---|---|---|---|---|
| Lora (r = 8) | 16 | FP16 | 28 GB | 8ex/s |
| Lora (r = 8) | 8 | FP16 | 24 GB | 8ex/s |
| Lora (r = 8) | 4 | FP16 | 20GB | 8ex/s |
| Lora (r = 8) | 4 | Int8 | 10 GB | 8ex/s |
| Lora (r = 8) | 4 | Int4 | 8GB | 8ex/s |
| Puning P (P = 16) | 4 | FP16 | 20GB | 8ex/s |
| Puning P (P = 16) | 4 | Int8 | 16 GB | 8ex/s |
| Puning P (P = 16) | 4 | Int4 | 12 GB | 8ex/s |
| Congelarse (l = 3) | 4 | FP16 | 24 GB | 8ex/s |
| Método RM | Tamaño por lotes | Modo | GRAMO | Velocidad |
|---|---|---|---|---|
| Lora (r = 8) + rm | 4 | FP16 | 22GB | - |
| Lora (r = 8) + rm | 1 | Int8 | 11 GB | - |
| Método RLHF | Tamaño por lotes | Modo | GRAMO | Velocidad |
|---|---|---|---|---|
| Lora (r = 8) + PPO | 4 | FP16 | 23GB | - |
| Lora (r = 8) + PPO | 1 | Int8 | 12 GB | - |
Nota:
res el rango Lora,pes el número de tokens de prefijo,les el número de capas entrenables,ex/ses los ejemplos por segundo en el entrenamiento. Elgradient_accumulation_stepsse establece en1. Todos se evalúan en una sola GPU TESLA V100 (32G), son valores aproximados y pueden variar en diferentes GPU.
Utilizamos todo el conjunto de datos alpaca_gpt4_zh para ajustar el modelo CHATGLM con Lora (R = 8) para una época, utilizando los hiper-parámetros predeterminados. La curva de pérdida durante el entrenamiento se presenta a continuación.
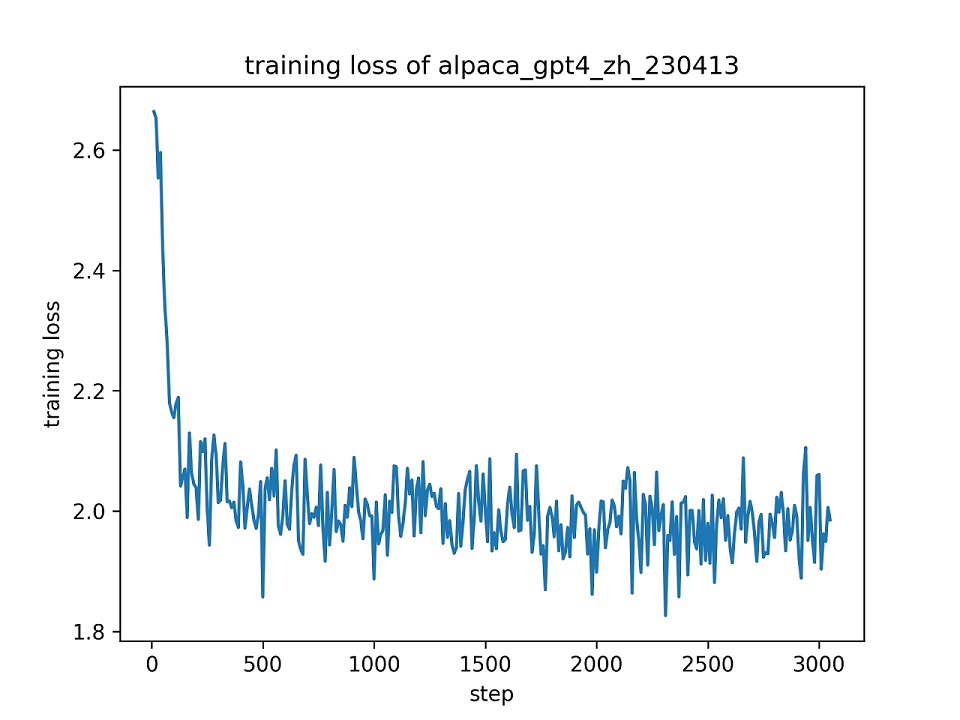
Seleccionamos 100 instancias en el conjunto de datos alpaca_gpt4_zh para evaluar el modelo CHATGLM sintonizado y calcular las puntuaciones Bleu y Rouge. Los resultados se presentan a continuación.
| Puntaje | Original | FZ (L = 2) | PT (P = 16) | Lora (r = 8) |
|---|---|---|---|---|
| Bleu-4 | 15.75 | 16.85 | 16.06 | 17.01 ( +1.26 ) |
| Rouge-1 | 34.51 | 36.62 | 34.80 | 36.77 ( +2.26 ) |
| Rouge-2 | 15.11 | 17.04 | 15.32 | 16.83 ( +1.72 ) |
| Ruge-l | 26.18 | 28.17 | 26.35 | 28.86 ( +2.68 ) |
| Parámetros (%) | / | 4.35% | 0.06% | 0.06% |
FZ: Freeze Tuning, PT: P-Tuning V2 (usamos
pre_seq_len=16para una comparación justa con Lora), Params: el porcentaje de parámetros capacitables.
Este repositorio tiene licencia bajo la licencia Apache-2.0. Siga la licencia modelo para usar el modelo CHATGLM-6B.
Si este trabajo es útil, cite como:
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}Este repositorio se beneficia de ChatGlm-6b, Chatglm-Tuning y Yuanzhoulvpi2017/Zero_NLP. Gracias por sus maravillosas obras.


