ChatGLM Efficient Tuning
v0.1.5:
Fine-tuning? ChatGLM-6B Model dengan? Peft.
Bergabunglah dengan WeChat kami.
[Bahasa Inggris | 中文]
Jika Anda memiliki pertanyaan, silakan merujuk ke wiki kami?.
Repo ini tidak akan dipertahankan di masa depan. Harap ikuti llama-factory untuk menyempurnakan model bahasa (termasuk chatglm2-6b).
[23/07/15] Sekarang kami mengembangkan UI web all-in-one untuk pelatihan, evaluasi, dan inferensi. Coba train_web.py untuk menyempurnakan model chatglm-6b di browser web Anda. Terima kasih @kanadessiina dan @codemayq atas upaya mereka dalam pengembangan.
[23/07/09] Sekarang kami merilis FastEdit⚡?, Paket yang mudah digunakan untuk mengedit pengetahuan faktual tentang model bahasa besar secara efisien. Harap ikuti Fasitedit jika Anda tertarik.
[23/06/25] Sekarang kami menyelaraskan Demo API dengan format Openai di mana Anda dapat memasukkan model yang disesuaikan dalam aplikasi berbasis chatgpt yang sewenang-wenang.
[23/06/25] Sekarang kami mendukung penyesuaian model chatglm2-6b dengan kerangka kerja kami!
[23/06/05] Sekarang kami mendukung pelatihan Lora 4-bit (alias Qlora). Coba --quantization_bit 4 argumen untuk bekerja dengan model kuantisasi 4-bit. (Fitur Eksperimental)
[23/06/01] Kami menerapkan kerangka kerja yang mendukung penyetelan model Llama dan Bloom yang efisien. Harap ikuti llama-efisien-tuning jika Anda tertarik.
[23/05/19] Sekarang kami mendukung menggunakan pengembangan yang ditetapkan untuk mengevaluasi model saat pelatihan. Coba --dev_ratio Argumen untuk menentukan ukuran set pengembangan.
[23/04/29] Sekarang kami mendukung pelatihan chatglm dengan pembelajaran penguatan dengan umpan balik manusia (RLHF) ! Kami memberikan beberapa contoh untuk menjalankan pelatihan RLHF, silakan merujuk ke folder examples untuk detailnya.
[23/04/20] Repo kami mencapai 100 bintang dalam waktu 12 hari! Selamat!
[23/04/19] Sekarang kami mendukung penggabungan bobot model yang disesuaikan dengan lora! Coba --checkpoint_dir checkpoint1,checkpoint2 untuk terus-menerus menyempurnakan model.
[23/04/18] Sekarang kami mendukung pelatihan model terkuantisasi menggunakan tiga metode penyempurnaan! Coba argumen quantization_bit untuk melatih model dalam 4/8 bit.
[23/04/12] Sekarang kami mendukung pelatihan dari pos pemeriksaan ! Gunakan --checkpoint_dir Argumen untuk menentukan model pos pemeriksaan untuk menyempurnakan dari.
[23/04/11] Sekarang kami mendukung pelatihan dengan kumpulan data gabungan ! Coba --dataset dataset1,dataset2 untuk pelatihan dengan banyak set data.
Silakan merujuk ke data/readme.md untuk detailnya.
Beberapa set data memerlukan konfirmasi sebelum menggunakannya, jadi kami sarankan masuk dengan akun pemeluk Anda menggunakan perintah ini.
pip install --upgrade huggingface_hub
huggingface-cli loginScript kami sekarang mendukung metode fine-tuning berikut:
Dan GPU yang kuat !
Silakan merujuk ke data/example_dataset untuk memeriksa detail tentang format file dataset. Anda dapat menggunakan file .json tunggal atau skrip memuat dataset dengan beberapa file untuk membuat dataset khusus.
Catatan: Harap perbarui data/dataset_info.json untuk menggunakan dataset khusus Anda. Tentang format file ini, silakan merujuk ke data/README.md .
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt Jika Anda ingin mengaktifkan lora (qlora) yang dikuantisasi pada platform Windows, Anda akan diminta untuk menginstal versi bitsandbytes versi pra-dibangun, yang mendukung CUDA 11.1 hingga 12.1.
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.pySaat ini Web UI hanya mendukung pelatihan pada satu GPU .
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16Silakan merujuk ke wiki kami tentang detail argumen.
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate Jika Anda ingin memprediksi sampel dengan respons kosong, silakan isi kolom response dengan token dummy untuk memastikan sampel tidak akan dibuang sepanjang fase preprocessing.
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint Kunjungi http://localhost:8000/docs untuk dokumentasi API.
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| Metode fine-tune | Ukuran batch | Mode | GRAM | Kecepatan |
|---|---|---|---|---|
| Lora (r = 8) | 16 | FP16 | 28GB | 8ex/s |
| Lora (r = 8) | 8 | FP16 | 24GB | 8ex/s |
| Lora (r = 8) | 4 | FP16 | 20GB | 8ex/s |
| Lora (r = 8) | 4 | Int8 | 10GB | 8ex/s |
| Lora (r = 8) | 4 | Int4 | 8GB | 8ex/s |
| P-tuning (p = 16) | 4 | FP16 | 20GB | 8ex/s |
| P-tuning (p = 16) | 4 | Int8 | 16GB | 8ex/s |
| P-tuning (p = 16) | 4 | Int4 | 12GB | 8ex/s |
| Beku (l = 3) | 4 | FP16 | 24GB | 8ex/s |
| Metode RM | Ukuran batch | Mode | GRAM | Kecepatan |
|---|---|---|---|---|
| Lora (r = 8) + rm | 4 | FP16 | 22GB | - |
| Lora (r = 8) + rm | 1 | Int8 | 11GB | - |
| Metode RLHF | Ukuran batch | Mode | GRAM | Kecepatan |
|---|---|---|---|---|
| Lora (r = 8) + ppo | 4 | FP16 | 23GB | - |
| Lora (r = 8) + ppo | 1 | Int8 | 12GB | - |
Catatan:
radalah peringkat Lora,padalah jumlah token awalan,ladalah jumlah lapisan yang dapat dilatih,ex/sadalah contoh per detik saat pelatihan.gradient_accumulation_stepsdiatur ke1. Semua dievaluasi pada GPU Tesla V100 (32G) tunggal, mereka adalah nilai yang diperkirakan dan dapat bervariasi dalam GPU yang berbeda.
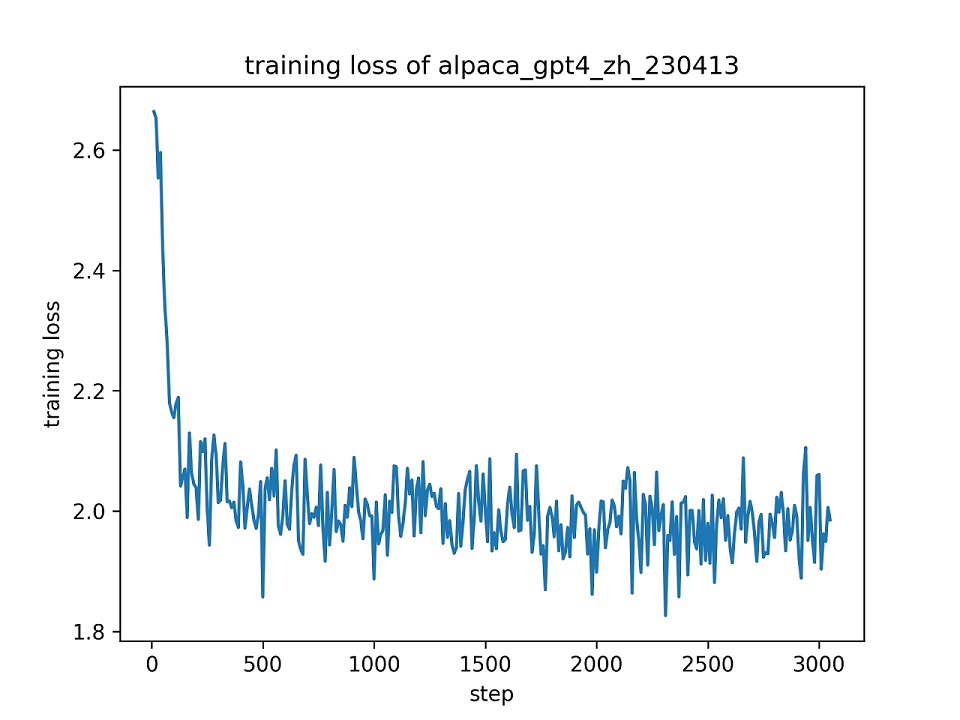
Kami menggunakan seluruh dataset alpaca_gpt4_zh untuk menyempurnakan model chatglm dengan lora (r = 8) untuk satu zaman, menggunakan hyper-parameter default. Kurva kerugian selama pelatihan disajikan di bawah ini.
Kami memilih 100 instance dalam dataset alpaca_gpt4_zh untuk mengevaluasi model chatglm yang disetel dan menghitung skor Bleu dan Rouge. Hasilnya disajikan di bawah ini.
| Skor | Asli | Fz (l = 2) | Pt (p = 16) | Lora (r = 8) |
|---|---|---|---|---|
| Bleu-4 | 15.75 | 16.85 | 16.06 | 17.01 ( +1.26 ) |
| Rouge-1 | 34.51 | 36.62 | 34.80 | 36.77 ( +2.26 ) |
| Rouge-2 | 15.11 | 17.04 | 15.32 | 16.83 ( +1.72 ) |
| Rouge-l | 26.18 | 28.17 | 26.35 | 28.86 ( +2.68 ) |
| Params (%) | / | 4,35% | 0,06% | 0,06% |
FZ: Tuning Beku, PT: P-Tuning V2 (kami menggunakan
pre_seq_len=16untuk perbandingan yang adil dengan LORA), Params: Persent jangkauan parameter yang dapat dilatih.
Repositori ini dilisensikan di bawah lisensi APACHE-2.0. Harap ikuti lisensi model untuk menggunakan model chatglm-6b.
Jika pekerjaan ini bermanfaat, silakan kutip sebagai:
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}Repo ini mendapat manfaat dari chatglm-6b, chatglm-tuning dan yuanzhoulvpi2017/zero_nlp. Terima kasih atas pekerjaan mereka yang luar biasa.


