ChatGLM Efficient Tuning
v0.1.5:
Точная настройка? Чатглм-6B Модель с? PEFT.
Присоединяйтесь к нашему WeChat.
[Английский | 中文]
Если у вас есть какие -либо вопросы, пожалуйста, обратитесь к нашей вики?
Это репо не будет поддерживаться в будущем. Пожалуйста, следуйте Llama-Factory для точной настройки языковых моделей (включая ChatGlM2-6B).
[23/07/15] Теперь мы разрабатываем все в одном веб-интерфейс для обучения, оценки и вывода. Попробуйте train_web.py , чтобы настройку модели Chatglm-6b в вашем веб-браузере. Спасибо @kanadesiina и @codemayq за их усилия в развитии.
[23/07/09] Теперь мы выпускаем FastEdit⚡?, Простой в использовании пакет для эффективного редактирования фактических знаний о крупных языковых моделях. Пожалуйста, следуйте Fastedit, если вам интересно.
[23/06/25] Теперь мы выравниваем демонстрационный API с форматом Openai, где вы можете вставить тонкую модель в произвольные приложения на основе CHATGPT.
[23/06/25] Теперь мы поддерживаем точную настройку модели Chatglm2-6b с нашей структурой!
[23/06/05] Теперь мы поддерживаем 4-битное обучение Lora (aka Qlora). Попробуйте --quantization_bit 4 аргумент для работы с 4-битной квантовой моделью. (экспериментальная особенность)
[23/06/01] Мы внедрили структуру, поддерживающую эффективную настройку моделей ламы и цветущего. Пожалуйста, следуйте за ламой-эффективной настройкой, если вам интересно.
[23/05/19] Теперь мы поддерживаем использование набора разработок для оценки модели во время обучения. Попробуйте --dev_ratio ARGERAT, чтобы указать размер набора разработки.
[23/04/29] Теперь мы поддерживаем обучение ChatGlm с обучением подкрепления с отзывом человека (RLHF) ! Мы приводим несколько примеров для проведения обучения RLHF, пожалуйста, обратитесь к папке examples для получения подробной информации.
[23/04/20] Наша репо достиг 100 звезд в течение 12 дней! Поздравляю!
[23/04/19] Теперь мы поддерживаем слияние весов тонких настройки моделей, обученных Лорой! Попробуйте --checkpoint_dir checkpoint1,checkpoint2 для постоянной настройки моделей.
[23/04/18] Теперь мы поддерживаем обучение квантованных моделей , используя три метода тонкой настройки! Попробуйте аргумент quantization_bit для обучения модели в 4/8 битах.
[23/04/12] Теперь мы поддерживаем обучение с контрольных точек ! Используйте аргумент --checkpoint_dir , чтобы указать модель контрольной точки для тонкой настройки.
[23/04/11] Теперь мы поддерживаем обучение с помощью комбинированных наборов данных ! Попробуйте --dataset dataset1,dataset2 для обучения с несколькими наборами данных.
Пожалуйста, обратитесь к данным/readme.md для получения подробной информации.
Некоторые наборы данных требуют подтверждения перед их использованием, поэтому мы рекомендуем войти в систему с вашей учетной записью обнимающего лица, используя эти команды.
pip install --upgrade huggingface_hub
huggingface-cli loginНаш сценарий теперь поддерживает следующие методы точной настройки:
И мощные графические процессоры !
Пожалуйста, обратитесь к data/example_dataset для проверки подробностей о формате файлов набора данных. Вы можете использовать один файл .json или сценарий загрузки набора данных с несколькими файлами для создания пользовательского набора данных.
Примечание. Пожалуйста, обновите data/dataset_info.json для использования пользовательского набора данных. О формате этого файла, пожалуйста, см. data/README.md .
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt Если вы хотите включить квантовую Lora (Qlora) на платформе Windows, вам потребуется установить предварительно построенную версию библиотеки bitsandbytes , которая поддерживает CUDA с 11.1 до 12.1.
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.pyВ настоящее время веб -интерфейс поддерживает обучение только на одном графическом процессоре .
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16Пожалуйста, обратитесь к нашей вики о деталях аргументов.
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate Если вы хотите предсказать образцы с пустыми ответами, пожалуйста, пожалуйста, заполните столбец response фиктивными токенами , чтобы убедиться, что образец не будет отброшен на протяжении всей фазы предварительной обработки.
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint Посетите http://localhost:8000/docs для документации API.
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| Метод тонкой настройки | Размер партии | Режим | Грамм | Скорость |
|---|---|---|---|---|
| Лора (r = 8) | 16 | FP16 | 28 ГБ | 8ex/s |
| Лора (r = 8) | 8 | FP16 | 24 ГБ | 8ex/s |
| Лора (r = 8) | 4 | FP16 | 20 ГБ | 8ex/s |
| Лора (r = 8) | 4 | Int8 | 10 ГБ | 8ex/s |
| Лора (r = 8) | 4 | Int4 | 8 ГБ | 8ex/s |
| P-Tuning (P = 16) | 4 | FP16 | 20 ГБ | 8ex/s |
| P-Tuning (P = 16) | 4 | Int8 | 16 ГБ | 8ex/s |
| P-Tuning (P = 16) | 4 | Int4 | 12 ГБ | 8ex/s |
| Заморозить (l = 3) | 4 | FP16 | 24 ГБ | 8ex/s |
| Метод RM | Размер партии | Режим | Грамм | Скорость |
|---|---|---|---|---|
| Lora (r = 8) + rm | 4 | FP16 | 22 ГБ | - |
| Lora (r = 8) + rm | 1 | Int8 | 11 ГБ | - |
| Метод RLHF | Размер партии | Режим | Грамм | Скорость |
|---|---|---|---|---|
| Lora (r = 8) + ppo | 4 | FP16 | 23 ГБ | - |
| Lora (r = 8) + ppo | 1 | Int8 | 12 ГБ | - |
Примечание:
r- это звание Lora,p- количество токенов префикса,l- количество обучаемых слоев,ex/s- это примеры в секунду при обучении.gradient_accumulation_stepsустановлен на1. Все они оцениваются на одном графическом процессоре Tesla V100 (32G), они являются аппроксимированными значениями и могут варьироваться в разных графических процессорах.
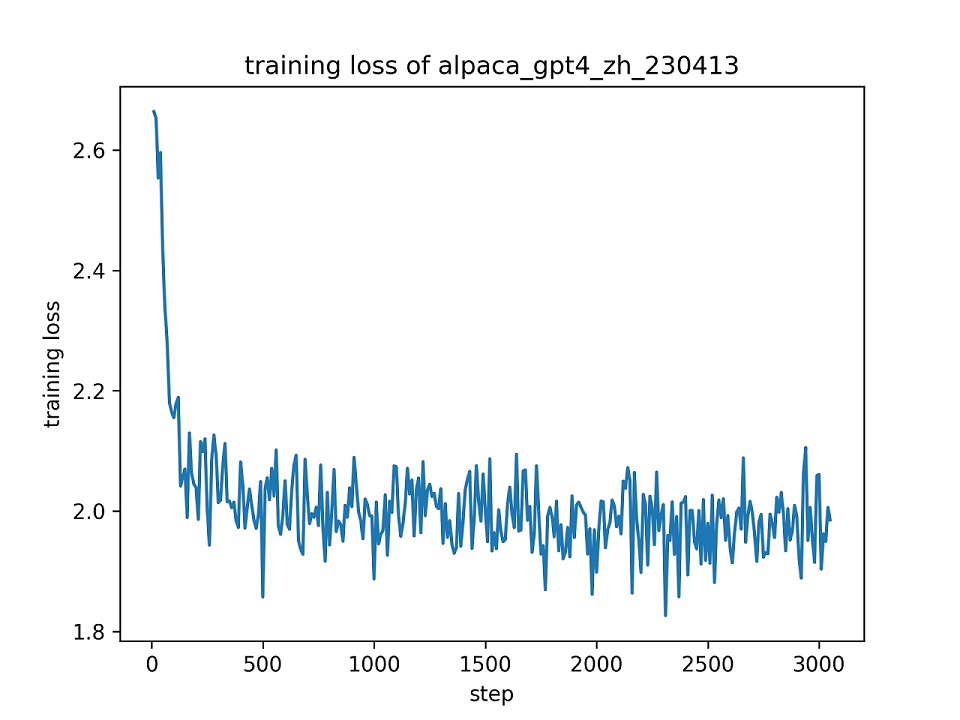
Мы используем весь набор данных alpaca_gpt4_zh , чтобы точно настроить модель ChatGLM с LORA (r = 8) для одной эпохи, используя гиперпараметры по умолчанию. Кривая потерь во время обучения представлена ниже.
Мы выбираем 100 экземпляров в наборе данных alpaca_gpt4_zh , чтобы оценить тонко настроенную модель ChatGLM и вычислять результаты Bleu и Rouge. Результаты представлены ниже.
| Счет | Оригинал | FZ (L = 2) | Pt (p = 16) | Лора (r = 8) |
|---|---|---|---|---|
| Bleu-4 | 15,75 | 16.85 | 16.06 | 17.01 ( +1.26 ) |
| Rouge-1 | 34,51 | 36.62 | 34,80 | 36,77 ( +2,26 ) |
| Rouge-2 | 15.11 | 17.04 | 15.32 | 16.83 ( +1,72 ) |
| Rouge-L | 26.18 | 28.17 | 26.35 | 28,86 ( +2,68 ) |
| Params (%) | / | 4,35% | 0,06% | 0,06% |
FZ: Freeze Tuning, Pt: P-Tuning V2 (мы используем
pre_seq_len=16для справедливого сравнения с Lora), параметры: процент пополам обучаемых параметров.
Этот репозиторий лицензирован по лицензии Apache-2.0. Пожалуйста, следуйте лицензии на модели, чтобы использовать модель ChatGLM-6B.
Если эта работа полезна, пожалуйста, цитируйтесь как:
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}Этот репотрансляция получает выгоду от Chatglm-6b, Chatglm-Tuning и Yuanzhoulvpi2017/Zero_nlp. Спасибо за их замечательные работы.


