ChatGLM Efficient Tuning
v0.1.5:
ปรับแต่งโมเดล chatglm-6b กับ? peft
เข้าร่วม WeChat ของเรา
[ภาษาอังกฤษ | 中文]
หากคุณมีคำถามใด ๆ โปรดดูวิกิของเรา?.
repo นี้จะ ไม่ได้รับการดูแล ในอนาคต โปรดติดตาม Llama-Factory เพื่อปรับแต่งรูปแบบภาษา (รวมถึง chatglm2-6b)
[23/07/15] ตอนนี้เราพัฒนาเว็บ UI ทั้งหมดสำหรับการฝึกอบรมการประเมินผลและการอนุมาน ลองใช้โมเดล train_web.py เพื่อปรับแต่ง chatglm-6b ในเว็บเบราว์เซอร์ของคุณ ขอบคุณ @kanadesiina และ @codemayq สำหรับความพยายามในการพัฒนา
[23/07/09] ตอนนี้เราเปิดตัวFastEdit⚡? แพ็คเกจที่ใช้งานง่ายสำหรับการแก้ไขความรู้ที่เป็นข้อเท็จจริงเกี่ยวกับรูปแบบภาษาขนาดใหญ่อย่างมีประสิทธิภาพ โปรดติดตาม FastEdit หากคุณสนใจ
[23/06/25] ตอนนี้เราจัดตำแหน่ง Demo API กับรูปแบบของ OpenAI ที่คุณสามารถแทรกโมเดลที่ได้รับการปรับแต่งในแอปพลิเคชันที่ใช้ CHATGPT โดยพลการ
[23/06/25] ตอนนี้เราสนับสนุนการปรับแต่งรุ่น Chatglm2-6B ด้วยกรอบของเรา!
[23/06/05] ตอนนี้เราสนับสนุนการฝึกอบรม LORA 4 บิต (aka Qlora) ลอง-อาร์กิวเมนต์ --quantization_bit 4 เพื่อทำงานกับโมเดลเชิงปริมาณ 4 บิต (คุณสมบัติการทดลอง)
[23/06/01] เราใช้เฟรมเวิร์กที่รองรับการปรับแต่งที่มีประสิทธิภาพของรุ่น Llama และ Bloom โปรดติดตาม Llama-Efficient-Tuning หากคุณสนใจ
[23/05/19] ตอนนี้เราสนับสนุนการใช้ชุดพัฒนาเพื่อประเมินโมเดลขณะฝึกอบรม ลอง -อาร์กิวเมนต์ --dev_ratio เพื่อระบุขนาดของชุดการพัฒนา
[23/04/29] ตอนนี้เราสนับสนุนการฝึกอบรม chatglm ด้วย การเรียนรู้การเสริมแรงด้วยความคิดเห็นของมนุษย์ (RLHF) ! เราให้ตัวอย่างหลายตัวอย่างเพื่อเรียกใช้การฝึกอบรม RLHF โปรดดูที่โฟลเดอร์ examples สำหรับรายละเอียด
[23/04/20] repo ของเราประสบความสำเร็จ 100 ดาวภายใน 12 วัน! ยินดีด้วย!
[23/04/19] ตอนนี้เรารองรับ การรวมน้ำหนัก ของรุ่นปรับแต่งที่ได้รับการฝึกฝนโดย Lora! ลอง --checkpoint_dir checkpoint1,checkpoint2 อาร์กิวเมนต์สำหรับการปรับแต่งโมเดลอย่างต่อเนื่อง
[23/04/18] ตอนนี้เราสนับสนุนการฝึกอบรม แบบจำลองเชิงปริมาณ โดยใช้วิธีการปรับแต่งสามวิธี! ลองใช้อาร์กิวเมนต์ quantization_bit สำหรับการฝึกอบรมแบบจำลองใน 4/8 บิต
[23/04/12] ตอนนี้เราสนับสนุน การฝึกอบรมจากจุดตรวจ ! ใช้ --checkpoint_dir อาร์กิวเมนต์ checkpoint_dir เพื่อระบุรูปแบบจุดตรวจสอบเพื่อปรับแต่งจาก
[23/04/11] ตอนนี้เราสนับสนุนการฝึกอบรมด้วย ชุดข้อมูลรวมกัน ! ลอง --dataset dataset1,dataset2 อาร์กิวเมนต์สำหรับการฝึกอบรมด้วยชุดข้อมูลหลายชุด
โปรดดูข้อมูล/readme.md สำหรับรายละเอียด
ชุดข้อมูลบางชุดต้องมีการยืนยันก่อนที่จะใช้ดังนั้นเราขอแนะนำให้เข้าสู่ระบบด้วยบัญชี Hugging Face ของคุณโดยใช้คำสั่งเหล่านี้
pip install --upgrade huggingface_hub
huggingface-cli loginตอนนี้สคริปต์ของเรารองรับวิธีการปรับแต่งต่อไปนี้:
และ GPU ที่ทรงพลัง !
โปรดดู data/example_dataset สำหรับการตรวจสอบรายละเอียดเกี่ยวกับรูปแบบของไฟล์ชุดข้อมูล คุณสามารถใช้ไฟล์ .json เดียวหรือสคริปต์การโหลดชุดข้อมูลที่มีหลายไฟล์เพื่อสร้างชุดข้อมูลที่กำหนดเอง
หมายเหตุ: โปรดอัปเดต data/dataset_info.json เพื่อใช้ชุดข้อมูลที่กำหนดเองของคุณ เกี่ยวกับรูปแบบของไฟล์นี้โปรดดู data/README.md
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt หากคุณต้องการเปิดใช้งาน Lora (Qlora) เชิงปริมาณบนแพลตฟอร์ม Windows คุณจะต้องติดตั้งไลบรารี bitsandbytes รุ่นที่สร้างไว้ล่วงหน้าซึ่งรองรับ CUDA 11.1 ถึง 12.1
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.pyปัจจุบัน Web UI รองรับการฝึกอบรมใน GPU เดียว เท่านั้น
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16โปรดดูวิกิของเราเกี่ยวกับรายละเอียดของข้อโต้แย้ง
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate หากคุณต้องการทำนายตัวอย่างที่มีการตอบกลับที่ว่างเปล่าโปรดกรอกคอลัมน์ response ด้วย โทเค็นจำลอง เพื่อให้แน่ใจว่าตัวอย่างจะไม่ถูกทิ้งตลอดระยะการประมวลผลล่วงหน้า
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint เยี่ยมชม http://localhost:8000/docs สำหรับเอกสาร API
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| วิธีการปรับแต่ง | ขนาดแบทช์ | โหมด | กรัม | ความเร็ว |
|---|---|---|---|---|
| lora (r = 8) | 16 | FP16 | 28GB | 8EX/S |
| lora (r = 8) | 8 | FP16 | 24GB | 8EX/S |
| lora (r = 8) | 4 | FP16 | 20GB | 8EX/S |
| lora (r = 8) | 4 | int8 | 10GB | 8EX/S |
| lora (r = 8) | 4 | INT4 | 8GB | 8EX/S |
| P-tuning (P = 16) | 4 | FP16 | 20GB | 8EX/S |
| P-tuning (P = 16) | 4 | int8 | 16GB | 8EX/S |
| P-tuning (P = 16) | 4 | INT4 | 12GB | 8EX/S |
| แช่แข็ง (l = 3) | 4 | FP16 | 24GB | 8EX/S |
| วิธี RM | ขนาดแบทช์ | โหมด | กรัม | ความเร็ว |
|---|---|---|---|---|
| lora (r = 8) + rm | 4 | FP16 | 22GB | - |
| lora (r = 8) + rm | 1 | int8 | 11GB | - |
| วิธี RLHF | ขนาดแบทช์ | โหมด | กรัม | ความเร็ว |
|---|---|---|---|---|
| lora (r = 8) + ppo | 4 | FP16 | 23GB | - |
| lora (r = 8) + ppo | 1 | int8 | 12GB | - |
หมายเหตุ:
rคืออันดับ lora,pคือจำนวนโทเค็นคำนำหน้า,lคือจำนวนเลเยอร์ที่สามารถฝึกอบรมได้ex/sเป็นตัวอย่างต่อวินาทีในการฝึกอบรมgradient_accumulation_stepsถูกตั้งค่าเป็น1ทั้งหมดได้รับการประเมินใน GPU Tesla V100 (32G) เดียวซึ่งเป็นค่าประมาณและอาจแตกต่างกันไปใน GPU ที่แตกต่างกัน
เราใช้ชุดข้อมูล alpaca_gpt4_zh ทั้งหมดเพื่อปรับแต่งโมเดล chatglm ด้วย lora (r = 8) สำหรับหนึ่งยุคโดยใช้พารามิเตอร์ไฮเปอร์เริ่มต้น เส้นโค้งการสูญเสียในระหว่างการฝึกอบรมแสดงไว้ด้านล่าง
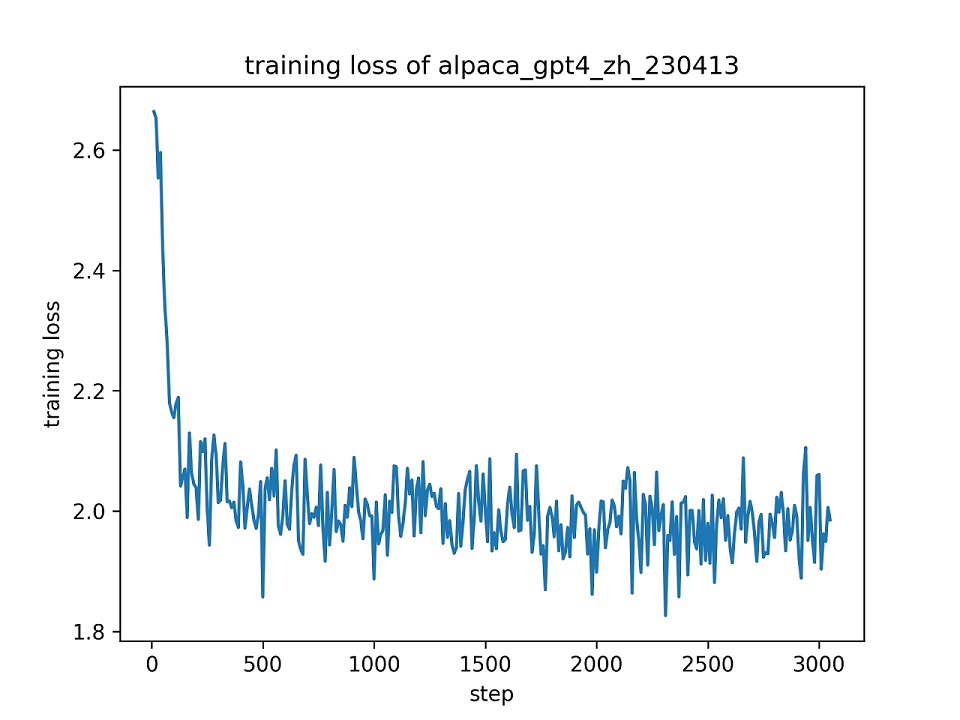
เราเลือก 100 อินสแตนซ์ในชุดข้อมูล alpaca_gpt4_zh เพื่อประเมินโมเดล Chatglm ที่ปรับแต่งอย่างละเอียดและคำนวณคะแนน Bleu และ Rouge ผลลัพธ์จะถูกนำเสนอด้านล่าง
| คะแนน | ต้นฉบับ | fz (l = 2) | pt (p = 16) | lora (r = 8) |
|---|---|---|---|---|
| bleu-4 | 15.75 | 16.85 | 16.06 | 17.01 ( +1.26 ) |
| rouge-1 | 34.51 | 36.62 | 34.80 | 36.77 ( +2.26 ) |
| Rouge-2 | 15.11 | 17.04 | 15.32 | 16.83 ( +1.72 ) |
| rouge-l | 26.18 | 28.17 | 26.35 | 28.86 ( +2.68 ) |
| params (%) | - | 4.35% | 0.06% | 0.06% |
FZ: Freeze Tuning, PT: P-tuning V2 (เราใช้
pre_seq_len=16สำหรับการเปรียบเทียบที่เป็นธรรมกับ Lora), params: เปอร์เซ็นต์ของพารามิเตอร์การฝึกอบรม
ที่เก็บนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต Apache-2.0 โปรดติดตามใบอนุญาตรุ่นเพื่อใช้รุ่น Chatglm-6B
หากงานนี้มีประโยชน์โปรดอ้างอิงเป็น:
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}repo นี้ได้รับประโยชน์จาก chatglm-6b, chatglm-tuning และ yuanzhoulvpi2017/zero_nlp ขอบคุณสำหรับผลงานที่ยอดเยี่ยมของพวกเขา


