ChatGLM Efficient Tuning
v0.1.5:
미세 조정? chatglm-6b 모델과 함께.
WeChat에 가입하십시오.
[영어 | 中文]
궁금한 점이 있으면 Wiki를 참조하십시오.
이 저장소는 미래에 유지되지 않을 것입니다 . 언어 모델 (ChatGLM2-6B 포함)을 미세 조정하려면 Llama-Factory를 따르십시오.
[23/07/15] 이제 우리는 교육, 평가 및 추론을위한 올인원 웹 UI를 개발합니다. train_web.py 사용하여 웹 브라우저에서 ChatGLM-6B 모델을 미세 조정하십시오. 개발에 대한 노력에 대해 @kanadesiina와 @codemayq에게 감사드립니다.
[23/07/09] 이제 우리는 대형 언어 모델에 대한 사실 지식을 효율적으로 편집하기위한 사용하기 쉬운 패키지 인 FastedIt⚡?를 출시합니다. 관심이 있으시면 금식을 따르십시오.
[23/06/25] 이제 우리는 Demo API를 OpenAI의 형식과 정렬하여 임의의 chatgpt 기반 응용 프로그램에 미세 조정 된 모델을 삽입 할 수 있습니다.
[23/06/25] 이제 우리는 프레임 워크를 통해 ChatGLM2-6B 모델을 미세 조정하는 것을 지원합니다!
[23/06/05] 이제 우리는 4 비트 로라 훈련 (일명 Qlora)을 지원합니다. 시도 --quantization_bit 4 인수는 4 비트 양자화 모델로 작동합니다. (실험 기능)
[23/06/01] 우리는 LLAMA 및 블룸 모델의 효율적인 튜닝을 지원하는 프레임 워크를 구현했습니다. 관심이 있으시면 llama-efficients 튜닝을 따르십시오.
[23/05/19] 이제 우리는 훈련 중에 모델을 평가하기 위해 개발 세트를 사용하여 지원합니다. 개발 세트의 크기를 지정하려면 --dev_ratio 인수를 시도하십시오.
[23/04/29] 이제 우리는 인간 피드백 (RLHF)을 사용한 강화 학습 으로 ChatGLM을 교육합니다! RLHF 교육을 실행하기위한 몇 가지 예를 제공합니다. 자세한 내용은 examples 폴더를 참조하십시오.
[23/04/20] 우리의 리포는 12 일 이내에 100 개의 별을 달성했습니다! 축하해요!
[23/04/19] 이제 우리는 Lora가 훈련 한 미세 조정 된 모델의 무게를 병합하는 것을 지원합니다! 시도 --checkpoint_dir checkpoint1,checkpoint2 인수는 모델을 지속적으로 미세 조정하기위한 인수를 시도하십시오.
[23/04/18] 이제 우리는 세 가지 미세 조정 방법을 사용하여 양자화 된 모델 훈련을 지원합니다! 4/8 비트로 모델을 훈련시키기위한 quantization_bit 인수를 시도하십시오.
[23/04/12] 이제 우리는 체크 포인트의 교육을 지원합니다! --checkpoint_dir 인수를 사용하여 체크 포인트 모델을 지정하여 미세 조정하십시오.
[23/04/11] 이제 우리는 결합 된 데이터 세트 로 교육을 지원합니다! 시도 --dataset dataset1,dataset2 인수 여러 데이터 세트로 훈련을 받으십시오.
자세한 내용은 data/readme.md를 참조하십시오.
일부 데이터 세트는 사용하기 전에 확인이 필요하므로 이러한 명령을 사용하여 Hugging Face 계정으로 로그인하는 것이 좋습니다.
pip install --upgrade huggingface_hub
huggingface-cli login우리의 스크립트는 이제 다음과 같은 미세 조정 방법을 지원합니다.
그리고 강력한 GPU !
데이터 세트 파일 형식에 대한 세부 정보를 확인하려면 data/example_dataset 참조하십시오. 여러 파일이있는 단일 .json 파일 또는 데이터 세트로드 스크립트를 사용하여 사용자 정의 데이터 세트를 만들 수 있습니다.
참고 : 사용자 정의 데이터 세트를 사용하려면 data/dataset_info.json 을 업데이트하십시오. 이 파일의 형식은 data/README.md 를 참조하십시오.
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt Windows 플랫폼에서 양자화 된 LORA (QLORA)를 활성화하려면 CUDA 11.1 ~ 12.1을 지원하는 사전 구축 된 bitsandbytes Library 버전을 설치해야합니다.
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.py현재 웹 UI는 단일 GPU 에 대한 교육 만 지원합니다.
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16논쟁의 세부 사항에 대해 Wiki를 참조하십시오.
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate 빈 응답이있는 샘플을 예측하려면, 전처리 단계에서 샘플을 폐기하지 않도록 더미 토큰 으로 response 열을 친절하게 채우십시오.
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint API 문서는 http://localhost:8000/docs 방문하십시오.
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| 미세 조정 방법 | 배치 크기 | 방법 | 그램 | 속도 |
|---|---|---|---|---|
| 로라 (R = 8) | 16 | FP16 | 28GB | 8ex/s |
| 로라 (R = 8) | 8 | FP16 | 24GB | 8ex/s |
| 로라 (R = 8) | 4 | FP16 | 20GB | 8ex/s |
| 로라 (R = 8) | 4 | int8 | 10GB | 8ex/s |
| 로라 (R = 8) | 4 | int4 | 8GB | 8ex/s |
| p- 튜닝 (p = 16) | 4 | FP16 | 20GB | 8ex/s |
| p- 튜닝 (p = 16) | 4 | int8 | 16GB | 8ex/s |
| p- 튜닝 (p = 16) | 4 | int4 | 12GB | 8ex/s |
| 동결 (l = 3) | 4 | FP16 | 24GB | 8ex/s |
| RM 메소드 | 배치 크기 | 방법 | 그램 | 속도 |
|---|---|---|---|---|
| 로라 (r = 8) + rm | 4 | FP16 | 22GB | - |
| 로라 (r = 8) + rm | 1 | int8 | 11GB | - |
| RLHF 방법 | 배치 크기 | 방법 | 그램 | 속도 |
|---|---|---|---|---|
| 로라 (r = 8) + PPO | 4 | FP16 | 23GB | - |
| 로라 (r = 8) + PPO | 1 | int8 | 12GB | - |
참고 :
r은 LORA 순위,p접두사 토큰의 수입니다.l훈련 가능한 층의 수입니다.ex/s훈련시 초당 예입니다.gradient_accumulation_steps는1으로 설정됩니다. 모두 단일 Tesla V100 (32g) GPU에서 평가되며 근사 값이며 GPU에 따라 다를 수 있습니다.
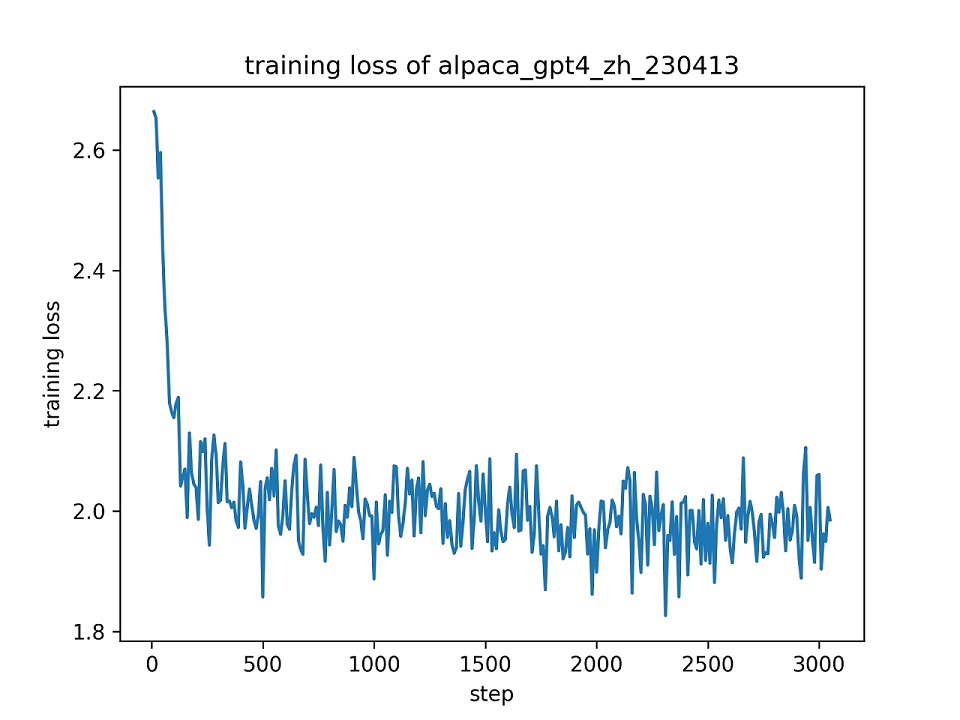
우리는 전체 alpaca_gpt4_zh 데이터 세트를 사용하여 기본 하이퍼 파라미터를 사용하여 하나의 epoch의 lora (r = 8)로 ChatGlm 모델을 미세 조정합니다. 훈련 중 손실 곡선은 다음과 같습니다.
미세 조정 된 ChatGLM 모델을 평가하고 BLEU 및 ROUGE 점수를 계산하기 위해 alpaca_gpt4_zh 데이터 세트에서 100 개의 인스턴스를 선택합니다. 결과는 아래에 나와 있습니다.
| 점수 | 원래의 | FZ (L = 2) | PT (P = 16) | 로라 (R = 8) |
|---|---|---|---|---|
| 블루 -4 | 15.75 | 16.85 | 16.06 | 17.01 ( +1.26 ) |
| 루즈 -1 | 34.51 | 36.62 | 34.80 | 36.77 ( +2.26 ) |
| 루즈 -2 | 15.11 | 17.04 | 15.32 | 16.83 ( +1.72 ) |
| 루즈 -L | 26.18 | 28.17 | 26.35 | 28.86 ( +2.68 ) |
| 매개 변수 (%) | / | 4.35% | 0.06% | 0.06% |
FZ : Freeze Tuning, PT : P-Tuning V2 (LORA와의 공정한 비교에는
pre_seq_len=16사용합니다), 매개 변수 : 훈련 가능한 매개 변수의 백분율.
이 저장소는 Apache-2.0 라이센스에 따라 라이센스가 부여됩니다. Model 라이센스를 따라 ChatGLM-6B 모델을 사용하십시오.
이 작업이 도움이된다면 다음과 같이 인용하십시오.
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}이 repo는 ChatGLM-6B, ChatGLM-Tuning 및 Yuanzhoulvpi2017/Zero_nlp의 혜택을받습니다. 그들의 멋진 작품에 감사드립니다.


