ChatGLM Efficient Tuning
v0.1.5:
Feinabstimmung? Chatglm-6b-Modell mit PEFT.
Treten Sie unserem Wechat bei.
[Englisch | 中文]
Wenn Sie Fragen haben, beziehen Sie sich bitte auf unser Wiki.
Dieses Repo wird in Zukunft nicht aufrechterhalten . Bitte folgen Sie Lama-Factory, um die Sprachmodelle (einschließlich Chatglm2-6b) zu feuern.
[23/07/15] Jetzt entwickeln wir eine All-in-One-Web-Benutzeroberfläche für Schulungen, Bewertung und Inferenz. Versuchen Sie es mit train_web.py , um das Chatglm-6b-Modell in Ihrem Webbrowser zu optimieren. Vielen Dank an @kanadesiina und @Codemayq für ihre Bemühungen in der Entwicklung.
[23/07/09] Jetzt veröffentlichen wir Fastedit⚡? Bitte folgen Sie Fastedit, wenn Sie interessiert sind.
[23/06/25] Jetzt richten wir die Demo-API mit dem OpenAI-Format aus, in dem Sie das fein abgestimmte Modell in beliebige ChatGPT-basierte Anwendungen einfügen können.
[23/06/25] Jetzt unterstützen wir die Feinabstimmung des Chatglm2-6b-Modells mit unserem Framework!
[23/06/05] Jetzt unterstützen wir das 4-Bit-Lora-Training (auch bekannt als Qlora). Versuchen Sie --quantization_bit 4 Argument, um mit einem 4-Bit-quantisierten Modell zu arbeiten. (Experimentelle Merkmale)
[23/06/01] Wir haben ein Framework implementiert, das die effiziente Abstimmung von Lama- und Bloom -Modellen unterstützt. Bitte folgen Sie der Lama-Effizienz-Tunigung, wenn Sie interessiert sind.
[23/05/19] Jetzt unterstützen wir die Verwendung des Entwicklungssatzes, um das Modell während des Trainings zu bewerten. Versuchen Sie es --dev_ratio Argument, um die Größe des Entwicklungssatzes anzugeben.
[23/04/29] Jetzt unterstützen wir das Training Chatglm mit Verstärkungslernen mit menschlichem Feedback (RLHF) ! Wir geben mehrere Beispiele für die Ausführung von RLHF -Schulungen an. Weitere Informationen finden Sie im Beispiel für examples .
[23/04/20] Unser Repo hat innerhalb von 12 Tagen 100 Sterne erreicht! Glückwunsch!
[23/04/19] Jetzt unterstützen wir das Verschmelzen der Gewichte von fein abgestimmten Modellen, die von Lora ausgebildet wurden! Versuchen Sie --checkpoint_dir checkpoint1,checkpoint2 Argument für die kontinuierliche Feinabstimmung der Modelle.
[23/04/18] Jetzt unterstützen wir das Training der quantisierten Modelle mit drei Feinabstimmungsmethoden! Versuchen Sie es quantization_bit für das Training des Modells in 4/8 Bit.
[23/04/12] Jetzt unterstützen wir Schulungen von Kontrollpunkten ! Verwenden Sie --checkpoint_dir -Argument, um das Checkpoint-Modell zu angeben.
[23/04/11] Jetzt unterstützen wir das Training mit kombinierten Datensätzen ! Versuchen Sie es --dataset dataset1,dataset2 -Argument für das Training mit mehreren Datensätzen.
Weitere Informationen finden Sie in Data/Readme.md.
Einige Datensätze erfordern vor der Verwendung eine Bestätigung. Wir empfehlen daher, sich mit Ihrem Umarmungs -Gesichtskonto mit diesen Befehlen anzumelden.
pip install --upgrade huggingface_hub
huggingface-cli loginUnser Skript unterstützt jetzt die folgenden Feinabstimmungsmethoden:
Und mächtiger GPUs !
Weitere Informationen zum Format von Datensatzdateien finden Sie unter data/example_dataset . Sie können entweder eine einzelne .json -Datei oder ein Datensatzladeskript mit mehreren Dateien verwenden, um einen benutzerdefinierten Datensatz zu erstellen.
HINWEIS: Bitte aktualisieren Sie data/dataset_info.json um Ihren benutzerdefinierten Datensatz zu verwenden. Informationen zum Format dieser Datei finden Sie unter data/README.md .
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt Wenn Sie die quantisierte Lora (Qlora) auf der Windows-Plattform aktivieren möchten, müssen Sie eine vorgefertigte Version der bitsandbytes Library installieren, die CUDA 11.1 bis 12.1 unterstützt.
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.pyDerzeit unterstützt die Web -Benutzeroberfläche nur das Training auf einer einzigen GPU .
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16Weitere Informationen zu den Argumenten finden Sie in unserem Wiki.
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate Wenn Sie die Proben mit leeren Antworten vorhersagen möchten, füllen Sie bitte die response mit Dummy -Token, um sicherzustellen, dass die Probe nicht in der gesamten Vorverarbeitungsphase verworfen wird.
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint Besuchen Sie http://localhost:8000/docs für API -Dokumentation.
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| Fein-Tune-Methode | Chargengröße | Modus | GRAMM | Geschwindigkeit |
|---|---|---|---|---|
| Lora (r = 8) | 16 | FP16 | 28 GB | 8ex/s |
| Lora (r = 8) | 8 | FP16 | 24 GB | 8ex/s |
| Lora (r = 8) | 4 | FP16 | 20 GB | 8ex/s |
| Lora (r = 8) | 4 | Int8 | 10 GB | 8ex/s |
| Lora (r = 8) | 4 | Int4 | 8 GB | 8ex/s |
| P-Tuning (p = 16) | 4 | FP16 | 20 GB | 8ex/s |
| P-Tuning (p = 16) | 4 | Int8 | 16 GB | 8ex/s |
| P-Tuning (p = 16) | 4 | Int4 | 12 GB | 8ex/s |
| Einfrieren (l = 3) | 4 | FP16 | 24 GB | 8ex/s |
| RM -Methode | Chargengröße | Modus | GRAMM | Geschwindigkeit |
|---|---|---|---|---|
| Lora (r = 8) + rm | 4 | FP16 | 22GB | - - |
| Lora (r = 8) + rm | 1 | Int8 | 11 GB | - - |
| RLHF -Methode | Chargengröße | Modus | GRAMM | Geschwindigkeit |
|---|---|---|---|---|
| Lora (r = 8) + PPO | 4 | FP16 | 23 GB | - - |
| Lora (r = 8) + PPO | 1 | Int8 | 12 GB | - - |
Hinweis:
rist der Lora -Rang,pist die Anzahl der Präfix -Token,list die Anzahl der trainierbaren Schichten,ex/ssind die Beispiele pro Sekunde beim Training. Diegradient_accumulation_stepsist auf1gesetzt. Alle werden an einer einzelnen Tesla V100 (32G) -GPU bewertet, sie sind approximierte Werte und können in verschiedenen GPUs variieren.
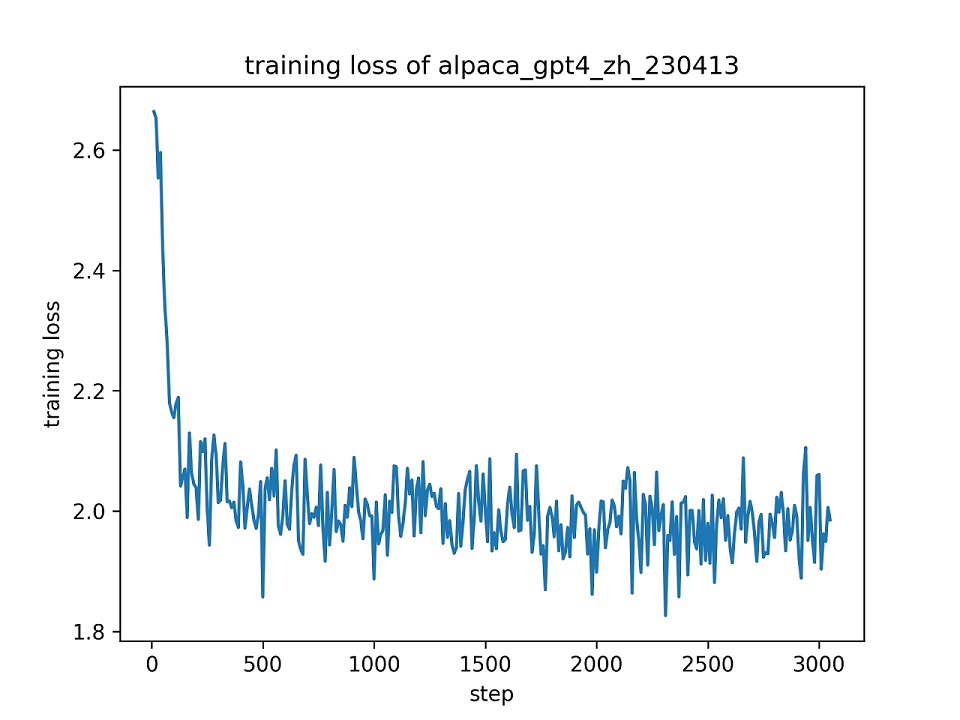
Wir verwenden den gesamten Datensatz alpaca_gpt4_zh , um das Chatglm-Modell mit LORA (r = 8) für eine Epoche mit den Standard-Hyperparametern zu fannen. Die Verlustkurve während des Trainings wird unten dargestellt.
Wir wählen 100 Instanzen im Datensatz alpaca_gpt4_zh , um das feine Chatglm-Modell zu bewerten und die BLEU- und Rouge-Scores zu berechnen. Die Ergebnisse sind nachstehend dargestellt.
| Punktzahl | Original | FZ (L = 2) | Pt (p = 16) | Lora (r = 8) |
|---|---|---|---|---|
| Bleu-4 | 15.75 | 16.85 | 16.06 | 17.01 ( +1,26 ) |
| Rouge-1 | 34,51 | 36.62 | 34,80 | 36.77 ( +2,26 ) |
| Rouge-2 | 15.11 | 17.04 | 15.32 | 16.83 ( +1,72 ) |
| Rouge-l | 26.18 | 28.17 | 26.35 | 28.86 ( +2,68 ) |
| Parameter (%) | / | 4,35% | 0,06% | 0,06% |
FZ: Freeze-Tuning, PT: P-Tuning V2 (Wir verwenden
pre_seq_len=16für einen fairen Vergleich mit Lora), Parames: Der Prozentsatz der trainierbaren Parameter.
Dieses Repository ist unter der Lizenz Apache-2.0 lizenziert. Bitte befolgen Sie die Modelllizenz, um das Chatglm-6b-Modell zu verwenden.
Wenn diese Arbeit hilfreich ist, zitieren Sie bitte:
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}Dieses Repo profitiert von Chatglm-6b, Chatglm-Tuning und Yuanzhoulvpi2017/null_nlp. Danke für ihre wundervollen Werke.


