ChatGLM Efficient Tuning
v0.1.5:
صقل جيد؟ نموذج chatglm-6b مع؟ peft.
انضم إلى WeChat لدينا.
[الإنجليزية | 中文]
إذا كان لديك أي أسئلة ، يرجى الرجوع إلى ويكي؟
لن يتم الحفاظ على هذا الريبو في المستقبل. يرجى متابعة Llama-Factory لضبط نماذج اللغة (بما في ذلك ChatGLM2-6B).
[23/07/15] الآن نقوم بتطوير واجهة مستخدم ويب الكل في واحد للتدريب والتقييم والاستدلال. جرب train_web.py لضبط طراز ChatGlm-6B في متصفح الويب الخاص بك. شكر kanadesiina و codemayq لجهودهم في التنمية.
[23/07/09] الآن نقوم بإطلاق حزمة FastEdit⚡؟ ، حزمة سهلة الاستخدام لتحرير المعرفة الواقعية لنماذج اللغة الكبيرة بكفاءة. يرجى متابعة FastEdit إذا كنت مهتمًا.
[23/06/25] الآن نقوم بمحاذاة واجهة برمجة التطبيقات التجريبية مع تنسيق Openai حيث يمكنك إدراج النموذج الذي تم ضبطه في التطبيقات المستندة إلى ChatGPT التعسفي.
[23/06/25] الآن نحن ندعم صياغة نموذج ChatGLM2-6B مع إطار عملنا!
[23/06/05] الآن نحن ندعم تدريب Lora 4-Bit (المعروف أيضًا باسم Qlora). حاول- --quantization_bit 4 وسيطة للعمل مع نموذج كمي 4 بت. (الميزة التجريبية)
[23/06/01] قمنا بتنفيذ إطار عمل يدعم الضبط الفعال لنماذج LAMA و Bloom. يرجى اتباع صقل لاما فعال إذا كنت مهتمًا.
[23/05/19] الآن نحن ندعم استخدام مجموعة التطوير لتقييم النموذج أثناء التدريب. جرب -وسيطة --dev_ratio لتحديد حجم مجموعة التطوير.
[23/04/29] الآن نحن ندعم تدريب ChatGlm مع التعلم التعزيز مع التعليقات البشرية (RLHF) ! نحن نقدم العديد من الأمثلة لتشغيل تدريب RLHF ، يرجى الرجوع إلى مجلد examples للحصول على التفاصيل.
[23/04/20] حقق ريبو لدينا 100 نجمة في غضون 12 يومًا! مبروك!
[23/04/19] الآن نحن ندعم دمج أوزان النماذج التي تم ضبطها بواسطة Lora! TREE --checkpoint_dir checkpoint1,checkpoint2 للضبط باستمرار على النماذج.
[23/04/18] الآن نحن ندعم تدريب النماذج الكمية باستخدام ثلاث طرق صقل! جرب وسيطة quantization_bit لتدريب النموذج في 4/8 بت.
[23/04/12] الآن نحن ندعم التدريب من نقاط التفتيش ! use --checkpoint_dir وسيطة لتحديد نموذج نقطة التفتيش للضبط من.
[23/04/11] الآن نحن ندعم التدريب مع مجموعات البيانات المشتركة ! جرب --dataset dataset1,dataset2 للتدريب مع مجموعات بيانات متعددة.
يرجى الرجوع إلى البيانات/README.MD للحصول على التفاصيل.
تتطلب بعض مجموعات البيانات تأكيدًا قبل استخدامها ، لذلك نوصي بتسجيل الدخول باستخدام حساب Face الخاص بك باستخدام هذه الأوامر.
pip install --upgrade huggingface_hub
huggingface-cli loginيدعم البرنامج النصي الآن أساليب الضبط الدقيقة التالية:
ووحدة معالجة الرسومات القوية !
يرجى الرجوع إلى data/example_dataset للتحقق من تفاصيل حول تنسيق ملفات مجموعة البيانات. يمكنك إما استخدام ملف .json واحد أو برنامج تحميل مجموعة بيانات مع ملفات متعددة لإنشاء مجموعة بيانات مخصصة.
ملاحظة: يرجى تحديث data/dataset_info.json لاستخدام مجموعة البيانات المخصصة. حول تنسيق هذا الملف ، يرجى الرجوع إلى data/README.md .
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt إذا كنت ترغب في تمكين Lora (Qlora) الكمي على منصة Windows ، فسيتم مطالبتك بتثبيت نسخة مصممة مسبقًا من مكتبة bitsandbytes ، والتي تدعم CUDA 11.1 إلى 12.1.
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.pyحاليًا يدعم واجهة المستخدم على الويب التدريب فقط على وحدة معالجة الرسومات الواحدة .
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16يرجى الرجوع إلى ويكي حول تفاصيل الحجج.
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate إذا كنت ترغب في التنبؤ بالعينات ذات الاستجابات الفارغة ، فيرجى تفضل ملء عمود response برموز وهمية لضمان عدم تجاهل العينة خلال مرحلة المعالجة المسبقة.
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint تفضل بزيارة http://localhost:8000/docs لوثائق API.
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| طريقة ضبطها | حجم الدُفعة | وضع | غرام | سرعة |
|---|---|---|---|---|
| لورا (ص = 8) | 16 | FP16 | 28 جيجابايت | 8ex/s |
| لورا (ص = 8) | 8 | FP16 | 24 جيجابايت | 8ex/s |
| لورا (ص = 8) | 4 | FP16 | 20 جيجابايت | 8ex/s |
| لورا (ص = 8) | 4 | int8 | 10 جيجابايت | 8ex/s |
| لورا (ص = 8) | 4 | int4 | 8 جيجا بايت | 8ex/s |
| P-Tuning (P = 16) | 4 | FP16 | 20 جيجابايت | 8ex/s |
| P-Tuning (P = 16) | 4 | int8 | 16 جيجابايت | 8ex/s |
| P-Tuning (P = 16) | 4 | int4 | 12 جيجابايت | 8ex/s |
| تجميد (L = 3) | 4 | FP16 | 24 جيجابايت | 8ex/s |
| طريقة RM | حجم الدُفعة | وضع | غرام | سرعة |
|---|---|---|---|---|
| لورا (ص = 8) + RM | 4 | FP16 | 22 جيجا بايت | - |
| لورا (ص = 8) + RM | 1 | int8 | 11 جيجا بايت | - |
| طريقة RLHF | حجم الدُفعة | وضع | غرام | سرعة |
|---|---|---|---|---|
| لورا (ص = 8) + PPO | 4 | FP16 | 23 جيجابايت | - |
| لورا (ص = 8) + PPO | 1 | int8 | 12 جيجابايت | - |
ملاحظة:
rهي رتبة Lora ،pهو عدد الرموز المميزة للبادئة ،lهو عدد الطبقات القابلة للدرار ،ex/sهي الأمثلة في الثانية في التدريب. يتم تعيينgradient_accumulation_stepsعلى1. يتم تقييم جميعها على وحدة معالجة الرسومات Tesla V100 (32G) ، وهي قيم تقريبًا وقد تختلف في وحدات معالجة الرسومات المختلفة.
نحن نستخدم مجموعة بيانات alpaca_gpt4_zh بالكامل لضبط نموذج ChatGlm مع Lora (r = 8) لعصر واحد ، باستخدام المقاييس المفرطة الافتراضية. يتم تقديم منحنى الخسارة أثناء التدريب أدناه.
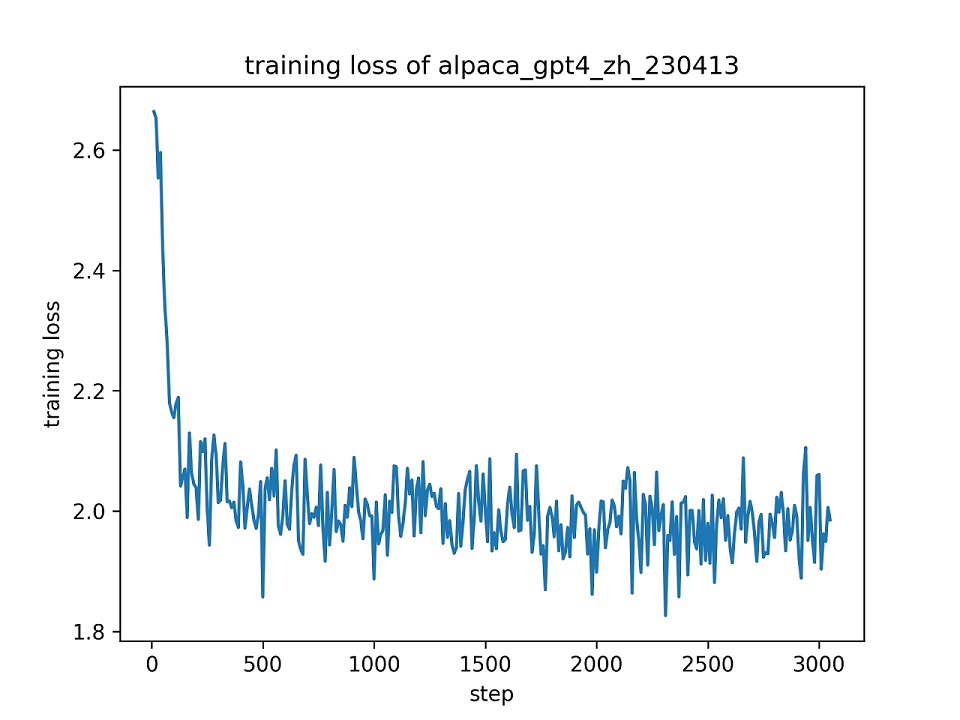
نختار 100 مثيلات في مجموعة بيانات alpaca_gpt4_zh لتقييم نموذج ChatGlm الذي تم ضبطه وحساب درجات Bleu و Rouge. وترد النتائج أدناه.
| نتيجة | إبداعي | FZ (L = 2) | PT (P = 16) | لورا (ص = 8) |
|---|---|---|---|---|
| Bleu-4 | 15.75 | 16.85 | 16.06 | 17.01 ( +1.26 ) |
| روج -1 | 34.51 | 36.62 | 34.80 | 36.77 ( +2.26 ) |
| Rouge-2 | 15.11 | 17.04 | 15.32 | 16.83 ( +1.72 ) |
| روج ل | 26.18 | 28.17 | 26.35 | 28.86 ( +2.68 ) |
| params (٪) | / | 4.35 ٪ | 0.06 ٪ | 0.06 ٪ |
FZ: TREEZE TUNING ، PT: P-Tuning V2 (نستخدم
pre_seq_len=16للمقارنة العادلة مع LORA) ، params: النسبة المئوية للمعلمات القابلة للتدريب.
تم ترخيص هذا المستودع بموجب ترخيص Apache-2.0. يرجى اتباع ترخيص الطراز لاستخدام نموذج chatglm-6b.
إذا كان هذا العمل مفيدًا ، فيرجى الإشارة إلى:
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}يستفيد هذا الريبو من ChatGlm-6B و ChatGlm Tuning و YuanzhoulVPI2017/Zero_nlp. شكرا لأعمالهم الرائعة.


