ChatGLM Efficient Tuning
v0.1.5:
Modelo de ajuste fino? Chatglm-6b com? Peft.
Junte -se ao nosso WeChat.
[Inglês | 中文]
Se você tiver alguma dúvida, consulte o nosso wiki?.
Este repositório não será mantido no futuro. Siga a fábrica da llama para ajustar os modelos de idiomas (incluindo o chatglm2-6b).
[23/07/15] Agora, desenvolvemos uma interface da web totalmente in-one para treinamento, avaliação e inferência. Experimente o Modelo train_web.py para Tune ChatGlm-6b no seu navegador da Web. Obrigado @kanadesiina e @codemayq por seus esforços no desenvolvimento.
[23/07/09] Agora, lançamos o jejum?, Um pacote fácil de usar para editar o conhecimento factual de grandes modelos de linguagem com eficiência. Siga o jejum se estiver interessado.
[23/06/25] Agora alinhamos a API Demo com o formato do OpenAI, onde você pode inserir o modelo ajustado em aplicativos arbitrários baseados em ChatGPT.
[23/06/25] Agora, apoiamos o ajuste fino do modelo Chatglm2-6b com nossa estrutura!
[23/06/05] Agora, apoiamos o treinamento Lora de 4 bits (também conhecido como qlora). Tente --quantization_bit 4 Argumento para trabalhar com modelo quantizado de 4 bits. (recurso experimental)
[23/06/01] Implementamos uma estrutura que suporta o ajuste eficiente dos modelos LLAMA e BLOOM. Por favor, siga o ajuste eficiente de llama se estiver interessado.
[23/05/19] Agora, apoiamos o uso do conjunto de desenvolvimento para avaliar o modelo durante o treinamento. Argumento de tentativa --dev_ratio para especificar o tamanho do conjunto de desenvolvimento.
[23/04/29] Agora, apoiamos o treinamento do treinamento com o aprendizado de reforço com feedback humano (RLHF) ! Fornecemos vários exemplos para executar o treinamento RLHF, consulte a pasta examples para obter detalhes.
[23/04/20] Nosso repo alcançou 100 estrelas em 12 dias! Parabéns!
[23/04/19] Agora, apoiamos a fusão dos pesos de modelos de ajuste fino treinados pela Lora! Experimente --checkpoint_dir checkpoint1,checkpoint2 Argumento para ajustar continuamente os modelos.
[23/04/18] Agora, apoiamos o treinamento dos modelos quantizados usando três métodos de ajuste fino! Experimente o argumento quantization_bit para treinar o modelo em 4/8 bits.
[23/04/12] Agora apoiamos o treinamento dos pontos de verificação ! Use-Argumento --checkpoint_dir para especificar o modelo do ponto de verificação para ajustar.
[23/04/11] Agora apoiamos o treinamento com conjuntos de dados combinados ! Tente --dataset dataset1,dataset2 para treinamento com vários conjuntos de dados.
Consulte o Data/Readme.md para obter detalhes.
Alguns conjuntos de dados exigem confirmação antes de usá -los, por isso recomendamos fazer login com sua conta de rosto abraçando usando esses comandos.
pip install --upgrade huggingface_hub
huggingface-cli loginNosso script agora suporta os seguintes métodos de ajuste fino:
E GPUs poderosas !
Consulte o data/example_dataset para verificar os detalhes sobre o formato dos arquivos do conjunto de dados. Você pode usar um único arquivo .json ou um script de carregamento de conjunto de dados com vários arquivos para criar um conjunto de dados personalizado.
NOTA: Atualize data/dataset_info.json para usar seu conjunto de dados personalizado. Sobre o formato deste arquivo, consulte data/README.md .
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt Se você deseja ativar o Lora (QLORA) Quantized na plataforma Windows, você deverá instalar uma versão pré-construída da bitsandbytes Library, que suporta CUDA 11.1 a 12.1.
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.pyAtualmente, a interface da web suporta apenas o treinamento em uma única GPU .
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16Consulte nosso wiki sobre os detalhes dos argumentos.
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate Se você deseja prever as amostras com respostas vazias, preencha a coluna de response com tokens dummy para garantir que a amostra não seja descartada durante toda a fase de pré -processamento.
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint Visite http://localhost:8000/docs para documentação da API.
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| Método de ajuste fino | Tamanho do lote | Modo | GRAMA | Velocidade |
|---|---|---|---|---|
| Lora (r = 8) | 16 | FP16 | 28 GB | 8ex/s |
| Lora (r = 8) | 8 | FP16 | 24 GB | 8ex/s |
| Lora (r = 8) | 4 | FP16 | 20 GB | 8ex/s |
| Lora (r = 8) | 4 | Int8 | 10 GB | 8ex/s |
| Lora (r = 8) | 4 | Int4 | 8 GB | 8ex/s |
| Tuneamento p (p = 16) | 4 | FP16 | 20 GB | 8ex/s |
| Tuneamento p (p = 16) | 4 | Int8 | 16 GB | 8ex/s |
| Tuneamento p (p = 16) | 4 | Int4 | 12 GB | 8ex/s |
| Congelamento (l = 3) | 4 | FP16 | 24 GB | 8ex/s |
| Método RM | Tamanho do lote | Modo | GRAMA | Velocidade |
|---|---|---|---|---|
| Lora (r = 8) + rm | 4 | FP16 | 22 GB | - |
| Lora (r = 8) + rm | 1 | Int8 | 11 GB | - |
| Método RLHF | Tamanho do lote | Modo | GRAMA | Velocidade |
|---|---|---|---|---|
| Lora (r = 8) + PPO | 4 | FP16 | 23 GB | - |
| Lora (r = 8) + PPO | 1 | Int8 | 12 GB | - |
Nota:
ré a classificação Lora,pé o número de tokens de prefixo,lé o número de camadas treináveis,ex/sé os exemplos por segundo no treinamento. Ogradient_accumulation_stepsestá definido como1. Todos são avaliados em uma única GPU Tesla V100 (32G), são valores aproximados e podem variar em diferentes GPUs.
Utilizamos todo o conjunto de dados alpaca_gpt4_zh para ajustar o modelo ChatGlm com Lora (r = 8) para uma época, usando os hiper-parâmetros padrão. A curva de perda durante o treinamento é apresentada abaixo.
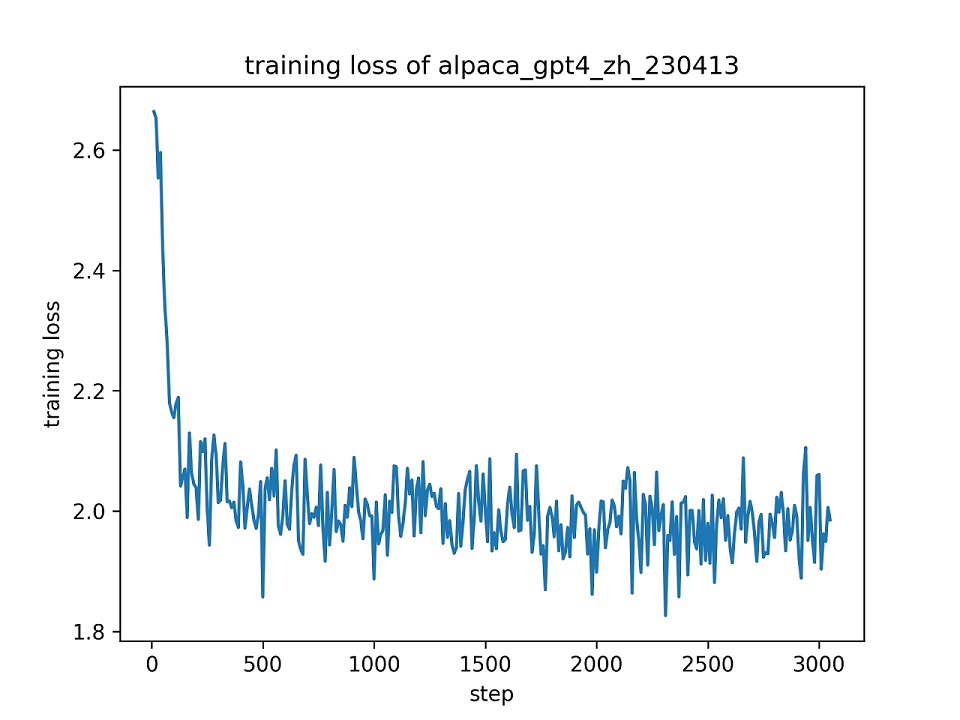
Selecionamos 100 instâncias no conjunto de dados alpaca_gpt4_zh para avaliar o modelo ChatGLM ajustado e calcular as pontuações BLEU e ROUGE. Os resultados são apresentados abaixo.
| Pontuação | Original | Fz (l = 2) | Pt (p = 16) | Lora (r = 8) |
|---|---|---|---|---|
| Bleu-4 | 15.75 | 16.85 | 16.06 | 17.01 ( +1,26 ) |
| Rouge-1 | 34.51 | 36.62 | 34.80 | 36.77 ( +2.26 ) |
| Rouge-2 | 15.11 | 17.04 | 15.32 | 16.83 ( +1,72 ) |
| Rouge-l | 26.18 | 28.17 | 26.35 | 28.86 ( +2,68 ) |
| Params (%) | / | 4,35% | 0,06% | 0,06% |
FZ: ajuste congelado, pt: pt-tuning v2 (usamos
pre_seq_len=16para comparação justa com lora), params: a porcentagem de parâmetros treináveis.
Este repositório é licenciado sob a licença Apache-2.0. Siga a licença do modelo para usar o modelo ChatGlm-6b.
Se este trabalho for útil, cite como:
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}Este repo se beneficia do ChatGLM-6B, ChatGlm-Tuning e Yuanzhoulvpi2017/zero_nlp. Obrigado por seus trabalhos maravilhosos.


