ChatGLM Efficient Tuning
v0.1.5:
Modélisation de tun fini? ChatGlm-6b avec? Peft.
Rejoignez notre WeChat.
[Anglais | 中文]
Si vous avez des questions, veuillez vous référer à notre wiki ?.
Ce repo ne sera pas maintenu à l'avenir. Veuillez suivre la factoire lama pour affiner les modèles de langue (y compris chatGLM2-6B).
[23/07/15] Maintenant, nous développons une interface utilisateur Web tout-en-un pour la formation, l'évaluation et l'inférence. Essayez train_web.py pour affiner le modèle chatGLM-6B dans votre navigateur Web. Merci à @kanadesiina et @codemayq pour leurs efforts dans le développement.
[23/07/09] Maintenant, nous libérons FastEdit⚡ ?, Un package facile à utiliser pour modifier efficacement les connaissances factuelles des modèles de grande langue. Veuillez suivre FastEdit si vous êtes intéressé.
[23/06/25] Nous alignons maintenant l'API de démonstration avec le format de l'OpenAI où vous pouvez insérer le modèle affiné dans des applications arbitraires basées sur ChatGPT.
[23/06/25] Maintenant, nous prenons en charge le modèle FACT LE MODÈLE CHATGLM2-6B avec notre framework!
[23/06/05] Nous soutenons maintenant la formation 4 bits LORA (aka Qlora). Try --quantization_bit 4 Argument pour travailler avec un modèle quantifié 4 bits. (fonctionnalité expérimentale)
[23/06/01] Nous avons implémenté un cadre prenant en charge le réglage efficace des modèles LLAMA et Bloom. Veuillez suivre les réglages économes en lama si vous êtes intéressé.
[23/05/19] Maintenant, nous soutenons l'utilisation de l'ensemble de développement pour évaluer le modèle pendant la formation. Essayez --dev_ratio Argument pour spécifier la taille de l'ensemble de développement.
[23/04/29] Maintenant, nous soutenons la formation ChatGLM avec l'apprentissage du renforcement avec des commentaires humains (RLHF) ! Nous fournissons plusieurs exemples pour exécuter la formation RLHF, veuillez consulter le dossier examples pour plus de détails.
[23/04/20] Notre repo a atteint 100 étoiles dans les 12 jours! Félicitations!
[23/04/19] Maintenant, nous soutenons la fusion des poids de modèles affinés formés par Lora! Essayez --checkpoint_dir checkpoint1,checkpoint2 Argument pour régler continuellement les modèles.
[23/04/18] Maintenant, nous soutenons la formation des modèles quantifiés en utilisant trois méthodes de réglage fin! Essayez l'argument quantization_bit pour la formation du modèle en 4/8 bits.
[23/04/12] Maintenant, nous soutenons la formation des points de contrôle ! Utilisez l'argument --checkpoint_dir pour spécifier le modèle de point de contrôle pour affiner.
[23/04/11] Nous soutenons maintenant la formation avec des ensembles de données combinés ! Essayez --dataset dataset1,dataset2 Argument pour la formation avec plusieurs ensembles de données.
Veuillez vous référer à Data / Readme.md pour plus de détails.
Certains ensembles de données nécessitent une confirmation avant de les utiliser, nous vous recommandons donc de vous connecter avec votre compte Face Hugging en utilisant ces commandes.
pip install --upgrade huggingface_hub
huggingface-cli loginNotre script prend désormais en charge les méthodes de réglage fin suivantes:
Et puissants GPU !
Veuillez vous référer à data/example_dataset pour vérifier les détails du format des fichiers de jeu de données. Vous pouvez utiliser un seul fichier .json ou un script de chargement de données avec plusieurs fichiers pour créer un ensemble de données personnalisé.
Remarque: veuillez mettre à jour data/dataset_info.json pour utiliser votre ensemble de données personnalisé. À propos du format de ce fichier, veuillez vous référer à data/README.md .
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt Si vous souhaitez activer la Lora (Qlora) quantifiée sur la plate-forme Windows, vous devrez installer une version prédéfinie de la bibliothèque bitsandbytes , qui prend en charge CUDA 11.1 à 12.1.
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.pyActuellement, l'interface utilisateur Web ne prend en charge que la formation sur un seul GPU .
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16Veuillez vous référer à notre wiki sur les détails des arguments.
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate Si vous souhaitez prédire les échantillons avec des réponses vides, veuillez remplir la colonne response avec des jetons factices pour vous assurer que l'échantillon ne sera pas jeté tout au long de la phase de prétraitement.
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint Visitez http://localhost:8000/docs pour la documentation de l'API.
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| Méthode d'adaptation | Taille de lot | Mode | GRAMME | Vitesse |
|---|---|---|---|---|
| Lora (r = 8) | 16 | FP16 | 28 Go | 8ex / s |
| Lora (r = 8) | 8 | FP16 | 24 Go | 8ex / s |
| Lora (r = 8) | 4 | FP16 | 20 Go | 8ex / s |
| Lora (r = 8) | 4 | Int8 | 10 Go | 8ex / s |
| Lora (r = 8) | 4 | Int4 | 8 Go | 8ex / s |
| P-Tuning (P = 16) | 4 | FP16 | 20 Go | 8ex / s |
| P-Tuning (P = 16) | 4 | Int8 | 16 GB | 8ex / s |
| P-Tuning (P = 16) | 4 | Int4 | 12 Go | 8ex / s |
| Gel (l = 3) | 4 | FP16 | 24 Go | 8ex / s |
| Méthode RM | Taille de lot | Mode | GRAMME | Vitesse |
|---|---|---|---|---|
| Lora (r = 8) + rm | 4 | FP16 | 22 Go | - |
| Lora (r = 8) + rm | 1 | Int8 | 11 Go | - |
| Méthode RLHF | Taille de lot | Mode | GRAMME | Vitesse |
|---|---|---|---|---|
| Lora (r = 8) + ppo | 4 | FP16 | 23 Go | - |
| Lora (r = 8) + ppo | 1 | Int8 | 12 Go | - |
Remarque:
rest le rang LORA,pest le nombre de jetons de préfixe,lest le nombre de couches entraînables,ex/sest les exemples par seconde à la formation. Legradient_accumulation_stepsest défini sur1. Tous sont évalués sur un seul GPU Tesla V100 (32G), ils sont des valeurs approximés et peuvent varier en différents GPU.
Nous utilisons l'ensemble de l'ensemble de données alpaca_gpt4_zh pour affiner le modèle chatGLM avec LORA (R = 8) pour une époque, en utilisant les hyper-paramètres par défaut. La courbe de perte pendant la formation est présentée ci-dessous.
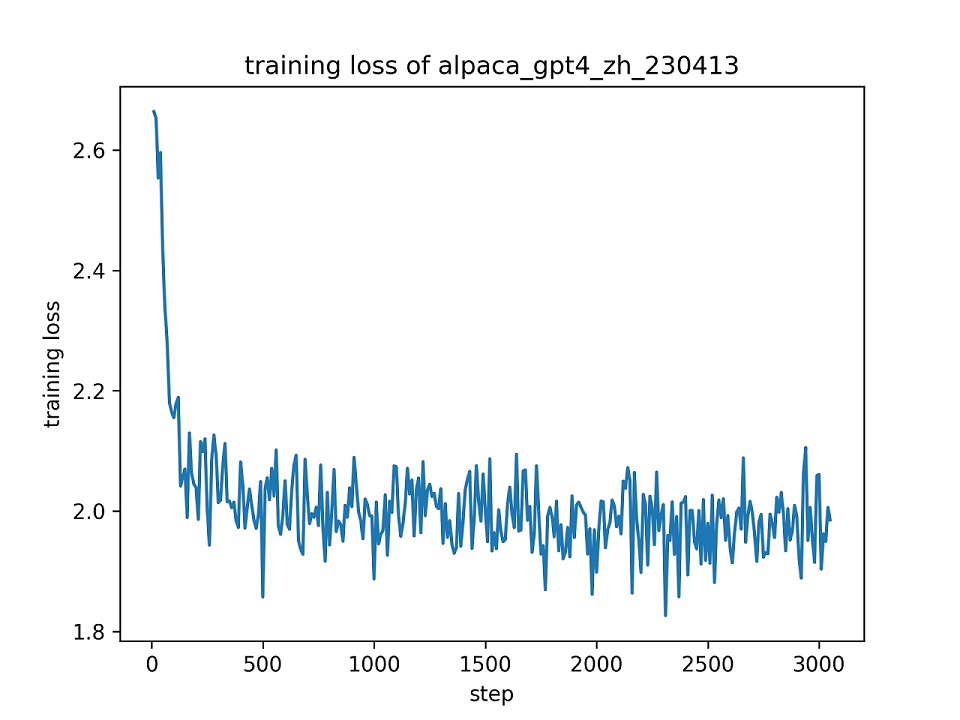
Nous sélectionnons 100 instances dans l'ensemble de données alpaca_gpt4_zh pour évaluer le modèle ChatGLM affiné et calculant les scores BLEU et ROUGE. Les résultats sont présentés ci-dessous.
| Score | Original | Fz (l = 2) | Pt (p = 16) | Lora (r = 8) |
|---|---|---|---|---|
| Bleu-4 | 15.75 | 16.85 | 16.06 | 17.01 ( +1.26 ) |
| Rouge-1 | 34.51 | 36,62 | 34.80 | 36.77 ( +2.26 ) |
| Rouge-2 | 15.11 | 17.04 | 15.32 | 16,83 ( +1,72 ) |
| Rouge-l | 26.18 | 28.17 | 26.35 | 28.86 ( +2,68 ) |
| Params (%) | / / | 4,35% | 0,06% | 0,06% |
FZ: Freeze Tuning, PT: P-Tuning v2 (nous utilisons
pre_seq_len=16pour une comparaison équitable avec LORA), params: le pourcentage des paramètres formables.
Ce référentiel est sous licence sous la licence Apache-2.0. Veuillez suivre la licence du modèle pour utiliser le modèle ChatGLM-6B.
Si ce travail est utile, veuillez citer comme:
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}Ce repo bénéficie du chatglm-6b, du chatglm-tun et de yuanzhoulvpi2017 / zero_nlp. Merci pour leurs merveilleuses œuvres.


