ChatGLM Efficient Tuning
v0.1.5:
微調整?chatglm-6bモデルを備えたpeft。
WeChatに参加してください。
[英語| 中文]
ご質問がある場合は、Wikiを参照してください。
このレポは将来的には維持されません。言語モデル(chatglm2-6bを含む)を微調整するには、llama-factoryに従ってください。
[23/07/15]現在、トレーニング、評価、推論のためのオールインワンWeb UIを開発します。 Webブラウザーでtrain_web.pyを試してChatglm-6bモデルを微調整してください。 @kanadesiinaと@codemayqの開発に努力してくれてありがとう。
[23/07/09]これで、大規模な言語モデルの事実知識を効率的に編集するための使いやすいパッケージであるFastEdit⚡??興味がある場合はFastEditをフォローしてください。
[23/06/25]次に、Demo APIをOpenAIの形式に揃えます。ここでは、任意のChatGPTベースのアプリケーションに微調整されたモデルを挿入できます。
[23/06/25]ここで、FrameworkでChatGlm2-6Bモデルを微調整することをサポートしています!
[23/06/05]現在、4ビットLORAトレーニング(別名Qlora)をサポートしています。 --quantization_bit 4引数4ビット量子化モデルで動作します。 (実験機能)
[23/06/01]ラマモデルとブルームモデルの効率的なチューニングをサポートするフレームワークを実装しました。興味がある場合は、ラマ効率の高い調整をフォローしてください。
[23/05/19]現在、トレーニング中にモデルを評価するために開発セットを使用してサポートします。 --dev_ratio引数を試して、開発セットのサイズを指定してください。
[23/04/29]今、私たちは人間のフィードバック(RLHF)を使用した強化学習でChatGlmのトレーニングをサポートしています! RLHFトレーニングを実行するためのいくつかの例を提供しています。詳細については、 examplesフォルダーを参照してください。
[23/04/20]私たちのレポは12日以内に100個の星を達成しました!おめでとう!
[23/04/19]今、私たちはLORAが訓練した微調整されたモデルの重みをマージすることをサポートしています! modelsを継続的に微調整するための--checkpoint_dir checkpoint1,checkpoint2引数を試してください。
[23/04/18]現在、3つの微調整方法を使用して量子化されたモデルのトレーニングをサポートしています! 4/8ビットでモデルをトレーニングするためのquantization_bit引数を試してください。
[23/04/12]チェックポイントからのトレーニングをサポートします! --checkpoint_dir引数を使用して、微調整するチェックポイントモデルを指定します。
[23/04/11]今、私たちは組み合わせたデータセットでトレーニングをサポートしています! --dataset dataset1,dataset2複数のデータセットでトレーニングするためのDataset2引数を試してください。
詳細については、データ/readme.mdを参照してください。
一部のデータセットは、それらを使用する前に確認が必要なため、これらのコマンドを使用して抱きしめるフェイスアカウントでログインすることをお勧めします。
pip install --upgrade huggingface_hub
huggingface-cli login私たちのスクリプトは、次の微調整方法をサポートしています。
そして強力なGPU !
データセットファイルの形式に関する詳細を確認するにはdata/example_datasetを参照してください。単一の.jsonファイルまたは複数のファイルを使用したデータセットロードスクリプトを使用して、カスタムデータセットを作成できます。
注: data/dataset_info.jsonを更新して、カスタムデータセットを使用してください。このファイルの形式については、 data/README.mdを参照してください。
git lfs install
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
conda create -n chatglm_etuning python=3.10
conda activate chatglm_etuning
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt Windowsプラットフォームで量子化されたLORA(Qlora)を有効にする場合は、CUDA 11.1から12.1をサポートするbitsandbytesライブラリの事前に構築されたバージョンをインストールする必要があります。
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whlCUDA_VISIBLE_DEVICES=0 python src/train_web.py現在、Web UIは単一のGPUでのトレーニングのみをサポートしています。
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--output_dir path_to_sft_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 5e-5
--num_train_epochs 3.0
--plot_loss
--fp16議論の詳細については、Wikiを参照してください。
accelerate config # configure the environment
accelerate launch src/train_bash.py # arguments (same as above)CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage rm
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset comparison_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--output_dir path_to_rm_checkpoint
--per_device_train_batch_size 4
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_loss
--fp16CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage ppo
--model_name_or_path path_to_your_chatglm_model
--do_train
--dataset alpaca_gpt4_en
--finetuning_type lora
--resume_lora_training False
--checkpoint_dir path_to_sft_checkpoint
--reward_model path_to_rm_checkpoint
--output_dir path_to_ppo_checkpoint
--per_device_train_batch_size 2
--gradient_accumulation_steps 4
--lr_scheduler_type cosine
--logging_steps 10
--save_steps 1000
--learning_rate 1e-5
--num_train_epochs 1.0
--plot_lossCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_eval
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_eval_result
--per_device_eval_batch_size 8
--max_samples 50
--predict_with_generateCUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage sft
--model_name_or_path path_to_your_chatglm_model
--do_predict
--dataset alpaca_gpt4_en
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_predict_result
--per_device_eval_batch_size 8
--max_samples 100
--predict_with_generate空の応答でサンプルを予測する場合は、 response列をダミートークンで親切に記入して、前処理フェーズ全体でサンプルが破棄されないようにしてください。
python src/api_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint APIドキュメントについては、 http://localhost:8000/docsにアクセスしてください。
python src/cli_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/web_demo.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpointpython src/export_model.py
--model_name_or_path path_to_your_chatglm_model
--finetuning_type lora
--checkpoint_dir path_to_checkpoint
--output_dir path_to_export| 微調整方法 | バッチサイズ | モード | グラム | スピード |
|---|---|---|---|---|
| ロラ(r = 8) | 16 | FP16 | 28GB | 8ex/s |
| ロラ(r = 8) | 8 | FP16 | 24GB | 8ex/s |
| ロラ(r = 8) | 4 | FP16 | 20GB | 8ex/s |
| ロラ(r = 8) | 4 | INT8 | 10GB | 8ex/s |
| ロラ(r = 8) | 4 | INT4 | 8GB | 8ex/s |
| p-tuning(p = 16) | 4 | FP16 | 20GB | 8ex/s |
| p-tuning(p = 16) | 4 | INT8 | 16ギガバイト | 8ex/s |
| p-tuning(p = 16) | 4 | INT4 | 12GB | 8ex/s |
| フリーズ(L = 3) | 4 | FP16 | 24GB | 8ex/s |
| RMメソッド | バッチサイズ | モード | グラム | スピード |
|---|---|---|---|---|
| ロラ(r = 8) + rm | 4 | FP16 | 22GB | - |
| ロラ(r = 8) + rm | 1 | INT8 | 11GB | - |
| RLHFメソッド | バッチサイズ | モード | グラム | スピード |
|---|---|---|---|---|
| lora(r = 8) + ppo | 4 | FP16 | 23GB | - |
| lora(r = 8) + ppo | 1 | INT8 | 12GB | - |
注:
rはロラランク、pはプレフィックストークンの数、lはトレーニング可能な層の数、ex/sトレーニングの1秒あたりの例です。gradient_accumulation_stepsは1に設定されています。すべてが単一のTesla V100(32G)GPUで評価され、近似値であり、GPUが異なる場合があります。
alpaca_gpt4_zhデータセット全体を使用して、デフォルトのハイパーパラメーターを使用して、1つのエポックに対してChatGlmモデル(r = 8)を使用してChatGlmモデル(r = 8)を微調整します。トレーニング中の損失曲線を以下に示します。
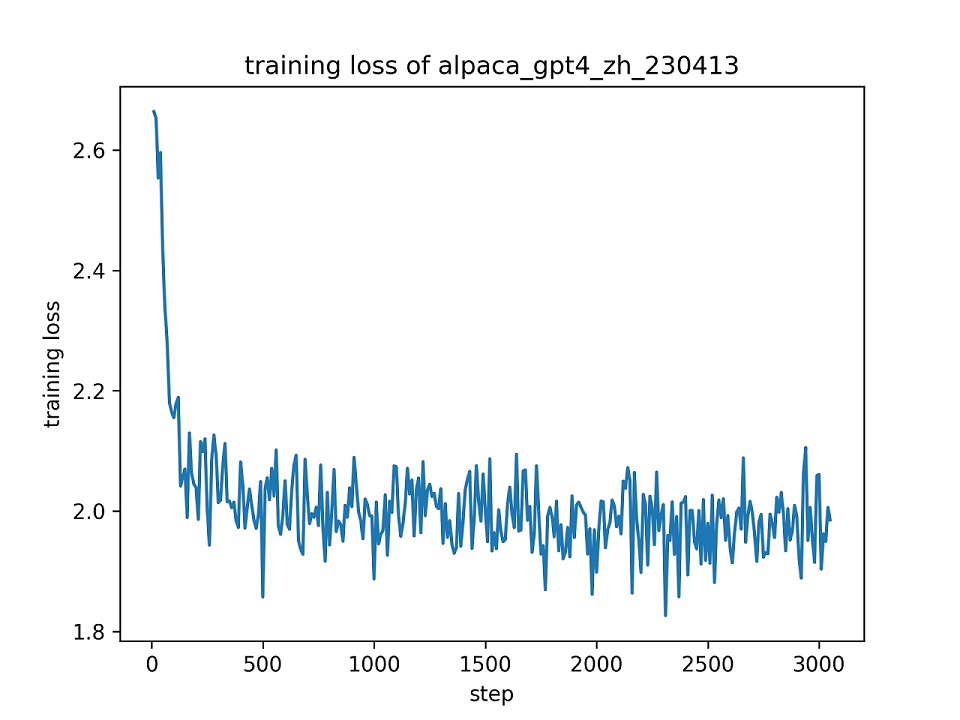
alpaca_gpt4_zhデータセットで100個のインスタンスを選択して、微調整されたChatGlmモデルを評価し、BLEUとRougeのスコアを計算します。結果を以下に示します。
| スコア | オリジナル | FZ(L = 2) | PT(P = 16) | ロラ(r = 8) |
|---|---|---|---|---|
| BLEU-4 | 15.75 | 16.85 | 16.06 | 17.01( +1.26 ) |
| Rouge-1 | 34.51 | 36.62 | 34.80 | 36.77( +2.26 ) |
| ルージュ-2 | 15.11 | 17.04 | 15.32 | 16.83( +1.72 ) |
| ルージュ-l | 26.18 | 28.17 | 26.35 | 28.86( +2.68 ) |
| パラマ(%) | / | 4.35% | 0.06% | 0.06% |
FZ:フリーズチューニング、PT:P-Tuning V2(LORAとの公正な比較には
pre_seq_len=16使用)、パラメーター:トレーニング可能なパラメーターのパーセント。
このリポジトリは、Apache-2.0ライセンスの下でライセンスされています。 ChatGlm-6Bモデルを使用するには、モデルライセンスに従ってください。
この作業が役立つ場合は、次のように引用してください。
@Misc { chatglm-efficient-tuning ,
title = { ChatGLM Efficient Tuning } ,
author = { hiyouga } ,
howpublished = { url{https://github.com/hiyouga/ChatGLM-Efficient-Tuning} } ,
year = { 2023 }
}このレポは、chatglm-6b、chatglm-tuning、yuanzhoulvpi2017/zero_nlpの恩恵を受けます。彼らの素晴らしい作品をありがとう。


