ChatGLM 6B finetuning
1.0.0
该项目的重点是以不同的方式(冻结嵌入 pt lora)进行chatglm-6b-int4模型的微调,并比较不同的微调方法对大型模型的影响,主要用于信息提取任务,生成任务,分类任务等。
如果您对其他版本的chatglm-6b进行微调(例如PF16),则需要将与对应的版本提升
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
在https://huggingface.co/thudm/chatglm-6b中
原始模型的参数被冷冻。例如,只能训练模型背后的层。
最终培训的参数如下:
可训练的参数:81920 ||所有参数:3.356b ||可训练的%:0.0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
完全冻结模型,仅训练模型的浮装部分,这是一种软及时的方法之一。
最终培训的参数如下:
可训练的参数:0.53b ||所有参数:3.356b ||可训练的%:15.9
be train layer: transformer.word_embeddings.weight
p调音p-tuning-v2柔软的及时改进,p-tuning-v2不仅用于嵌入层,而且连续令牌插入了每个层中,从而增加了变化和相互作用的量。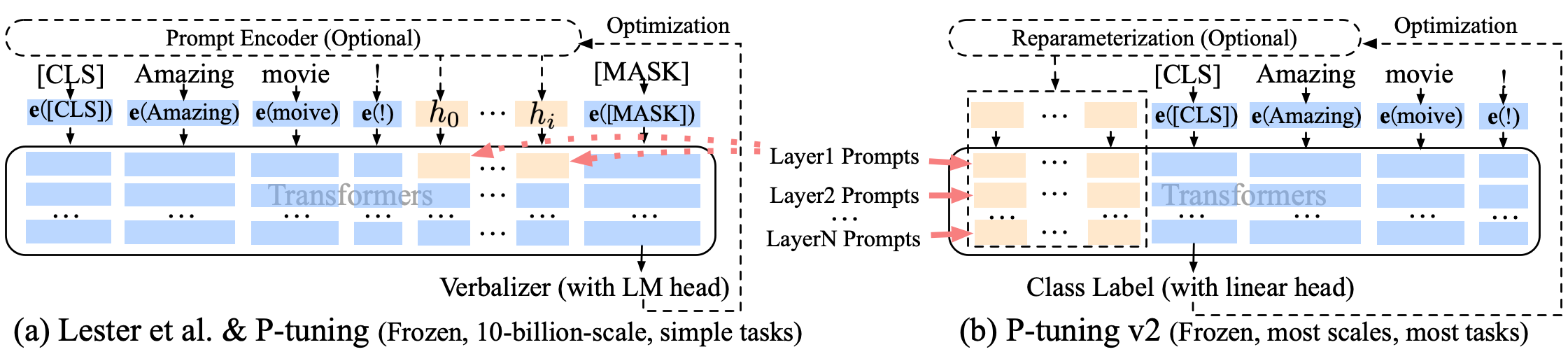
最终培训的参数如下:
可训练的参数:0.957b ||所有参数:4.312b ||可训练的%:22.18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
洛拉(Lora)允许我们通过优化适应过程中密集层变化的等级分解矩阵来间接训练神经网络中的一些密集层,同时保持预先训练的权重冻结。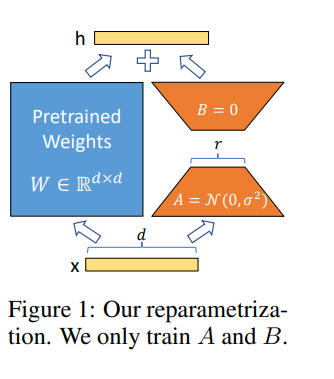
通过A100-40G在Google Colab Pro中进行微调模型,因此您需要在COLAB中安装某种方法:
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
冻结损失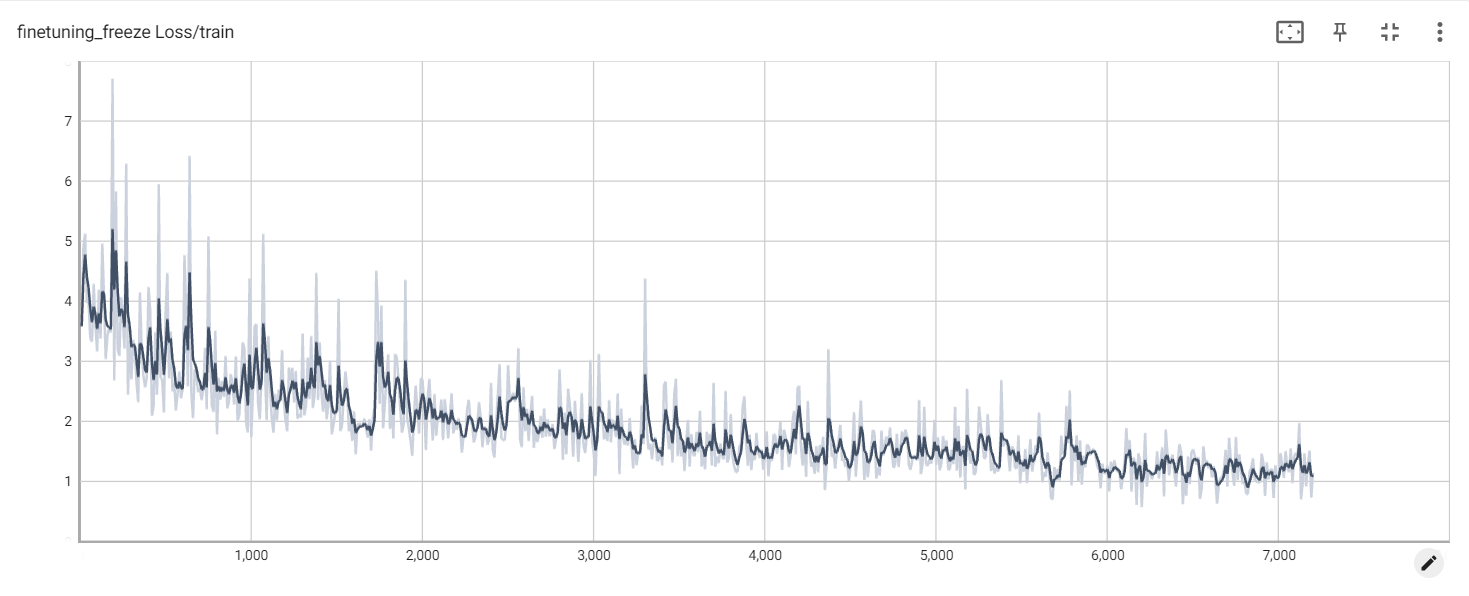
嵌入损失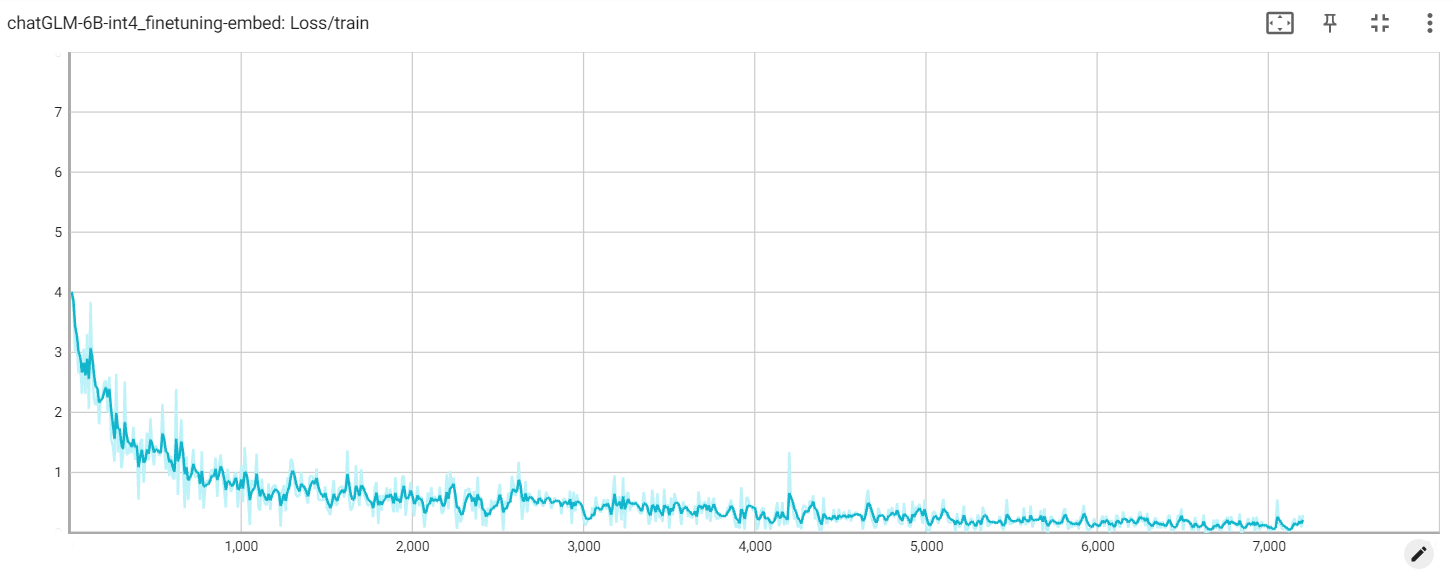
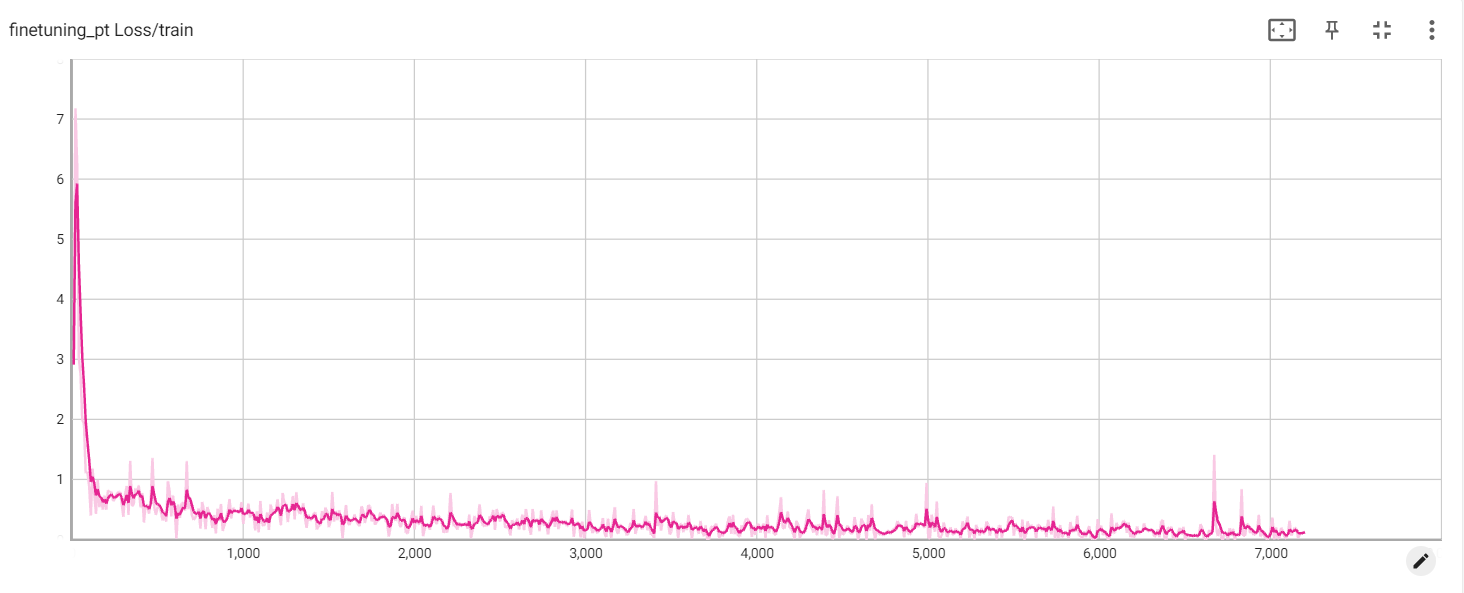
PT损失