ChatGLM 6B finetuning
1.0.0
Este projeto se concentra no ajuste fino do modelo ChatGlm-6b-Int4 de maneiras diferentes (congelamento incorporando pt lora) e comparando o efeito de diferentes métodos de ajuste fino no modelo grande, principalmente para tarefa de extração de informações, tarefa de geração, tarefa de classificação etc.
E se você afinar outra versão do chatglm-6b (como o PF16), precisará aprimorar a versão correspondente a
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
em https://huggingface.co/thudm/chatglm-6b
Os parâmetros do modelo original estão congelados. Por exemplo, apenas a camada por trás do modelo pode ser treinada.
Os parâmetros do treinamento final são os seguintes:
Params treináveis: 81920 || Todos os parâmetros: 3.356b || Treinable%: 0,0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
Congele completamente o modelo e treine apenas a parte de Ebedding do modelo como uma das maneiras suaves.
Os parâmetros do treinamento final são os seguintes:
Params treináveis: 0,53b || Todos os parâmetros: 3.356b || Treinable%: 15.9
be train layer: transformer.word_embeddings.weight
Puning p tunning-v2 Uma melhoria de prompt suave, p-tuning-v2 não é apenas para a camada de incorporação, mas os tokens contínuos são inseridos em cada camada, aumentando a quantidade de mudança e interação.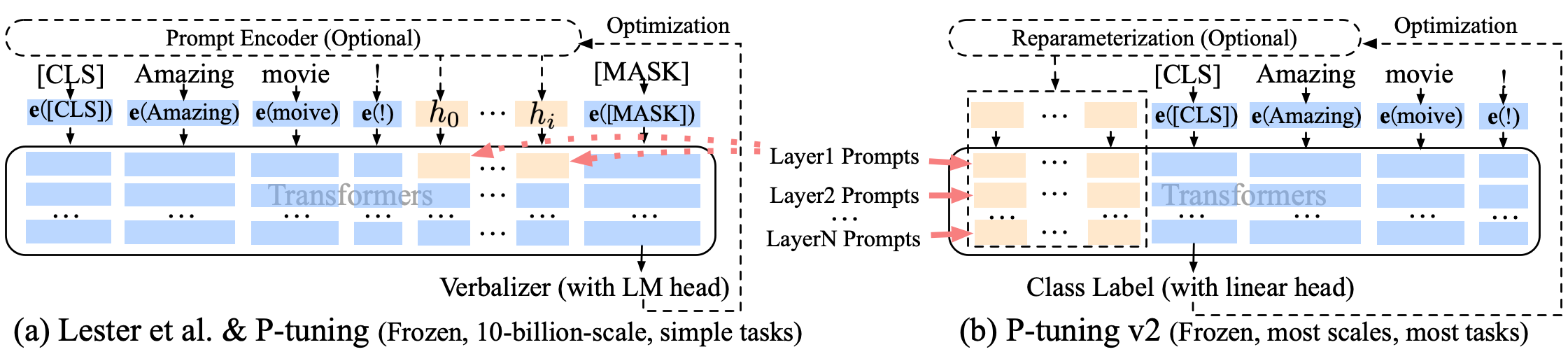
Os parâmetros do treinamento final são os seguintes:
Params treináveis: 0,957b || Todos os parâmetros: 4.312b || Treinable%: 22.18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
A Lora nos permite treinar algumas camadas densas em uma rede neural indiretamente, otimizando as matrizes de decomposição de classificação das mudanças de densas camadas durante a adaptação, mantendo os pesos pré-treinados congelados.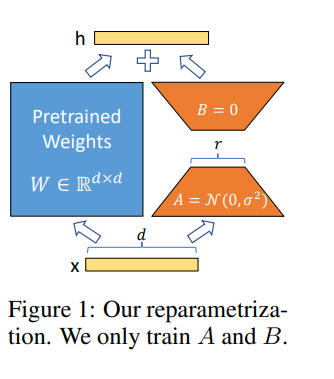
Ajuste fino do modelo no Google Colab Pro com A100-40G , então você precisa instalar algumas coisas em Colab :
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
Perda de congelamento 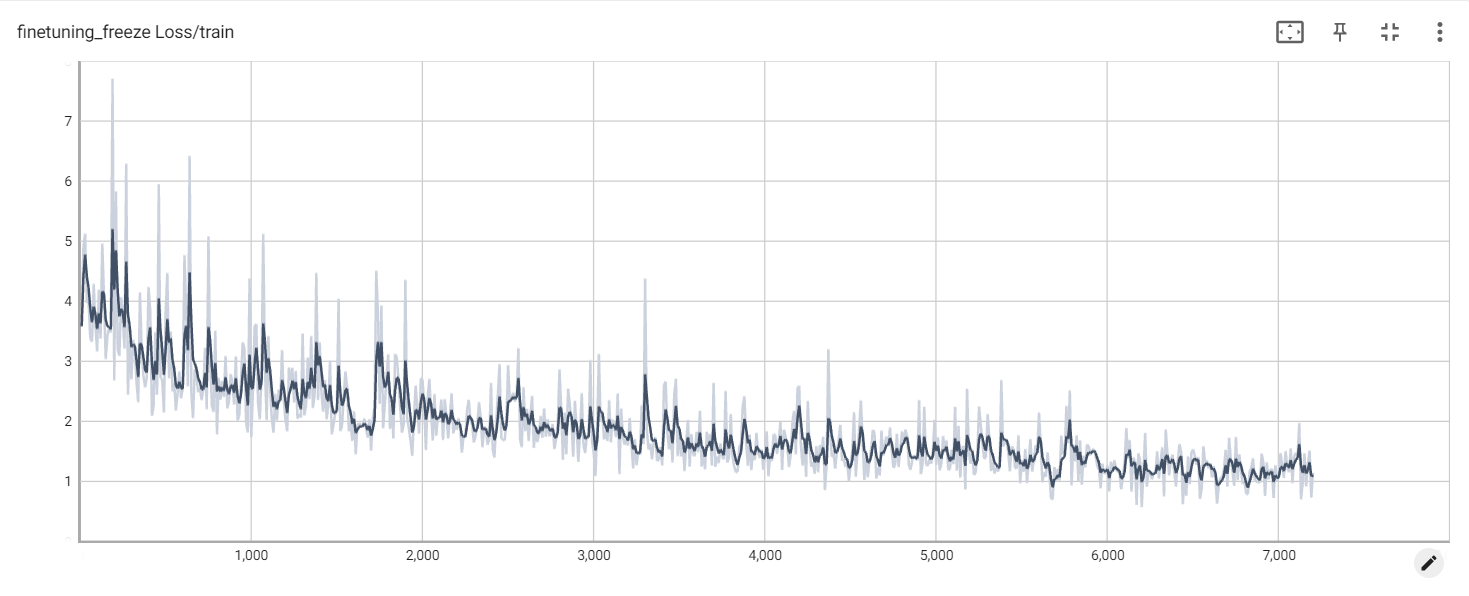
Incorporar perda 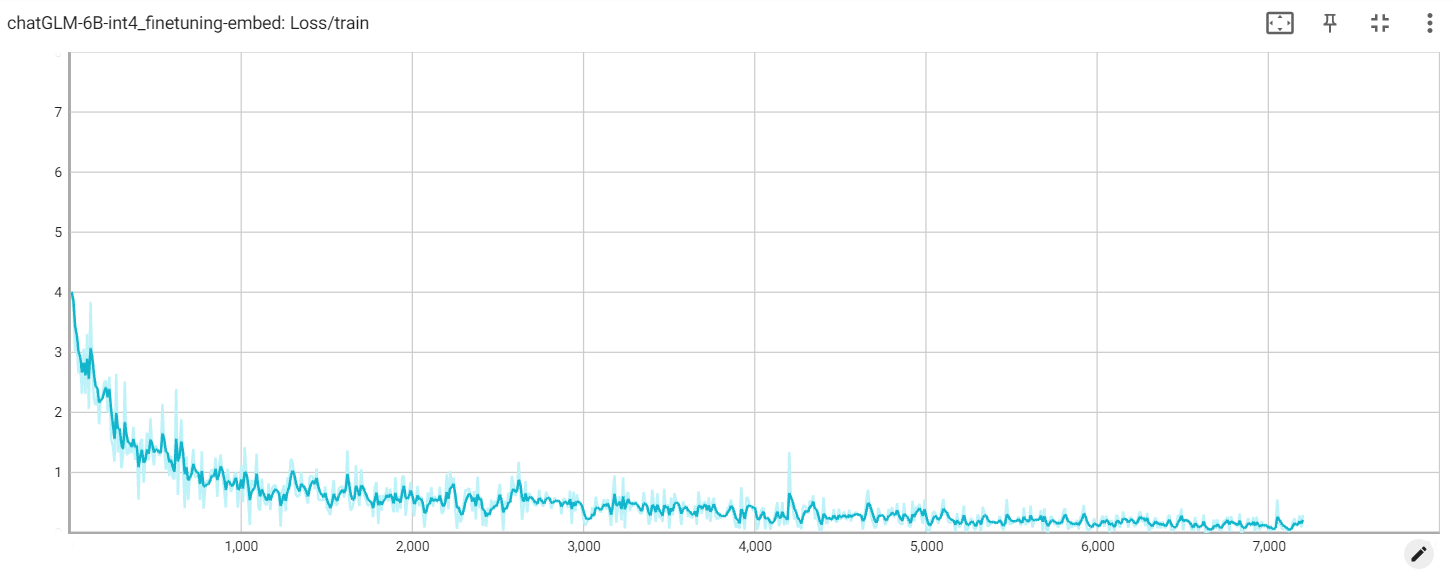
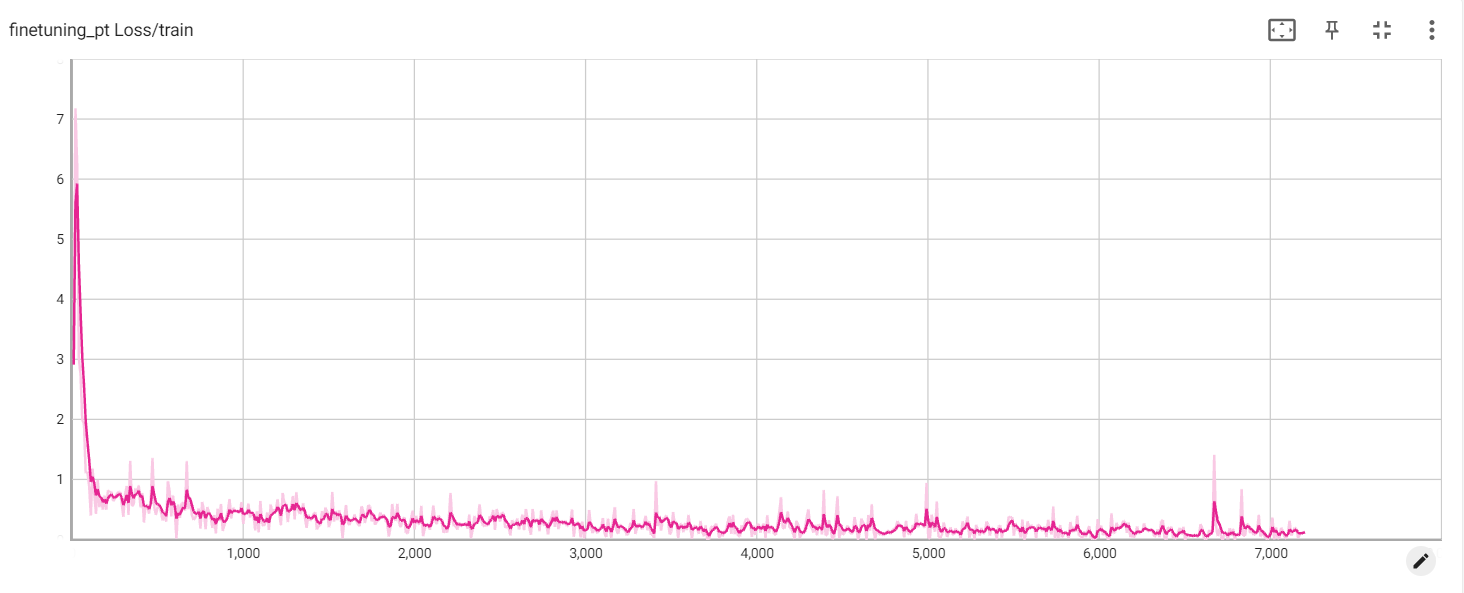
Perda de Pt