ChatGLM 6B finetuning
1.0.0
Ce projet se concentre sur le réglage fin du modèle ChatGLM-6B-INT4 de différentes manières (gel embeding pt lora), et comparant l'effet de différentes méthodes de réglage fin sur le grand modèle, principalement pour la tâche d'extraction de l'information, la tâche de génération, la tâche de classification, etc.
Et si vous réglez une autre version de ChatGlM-6B (comme PF16), vous devez mettre en place la version correspondant à
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
dans https://huggingface.co/thudm/chatglm-6b
Les paramètres du modèle d'origine sont gelés. Par exemple, seule la couche derrière le modèle peut être formée.
Les paramètres de la formation finale sont les suivants:
Paramètres formables: 81920 || Tous les paramètres: 3.356b || Trainable%: 0,0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
Gèlez entièrement le modèle et entraînez uniquement la partie d'écoulement du modèle comme l'une des manières douces.
Les paramètres de la formation finale sont les suivants:
Paramètres formables: 0,53b || Tous les paramètres: 3.356b || Trainable%: 15.9
be train layer: transformer.word_embeddings.weight
P régalage P-TUNING-V2 Une amélioration invite douce, P-Tuning-V2 n'est pas seulement pour la couche d'incorporation, mais les jetons continus sont insérés dans chaque couche, augmentant la quantité de changement et d'interaction.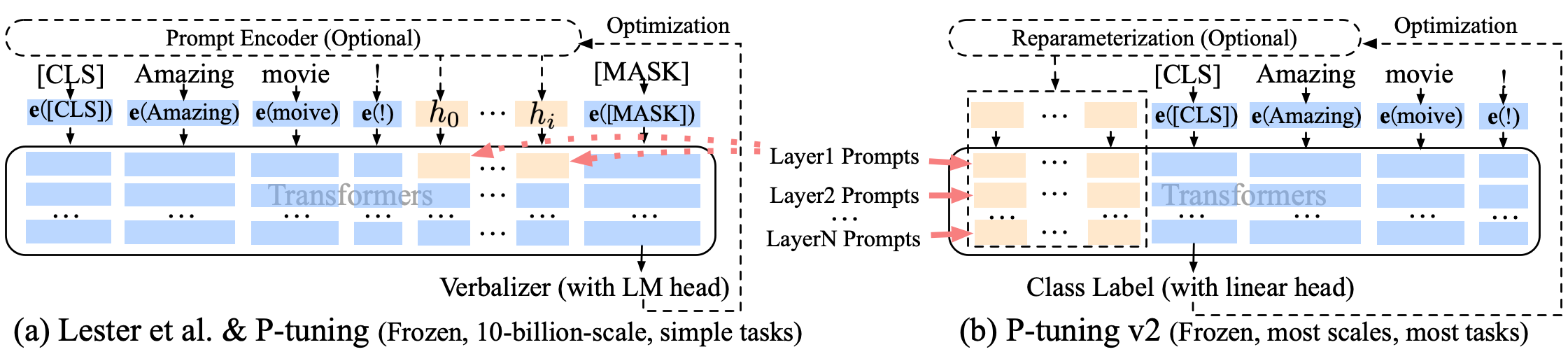
Les paramètres de la formation finale sont les suivants:
Paramètres formables: 0,957b || Tous les paramètres: 4.312b || Trainable%: 22.18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
Lora nous permet de former indirectement certaines couches denses dans un réseau neuronal en optimisant les matrices de décomposition de rang des changements de couches denses lors de l'adaptation à la place, tout en gardant les poids prélevés congelés.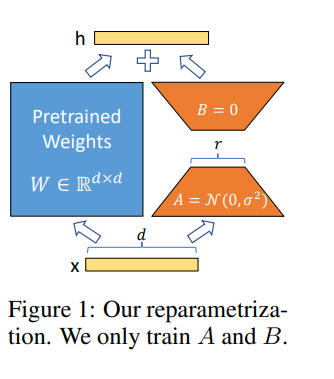
Fonctionment du modèle dans Google Colab Pro avec A100-40G , vous devez donc installer quelque chose à Colab :
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
Perte 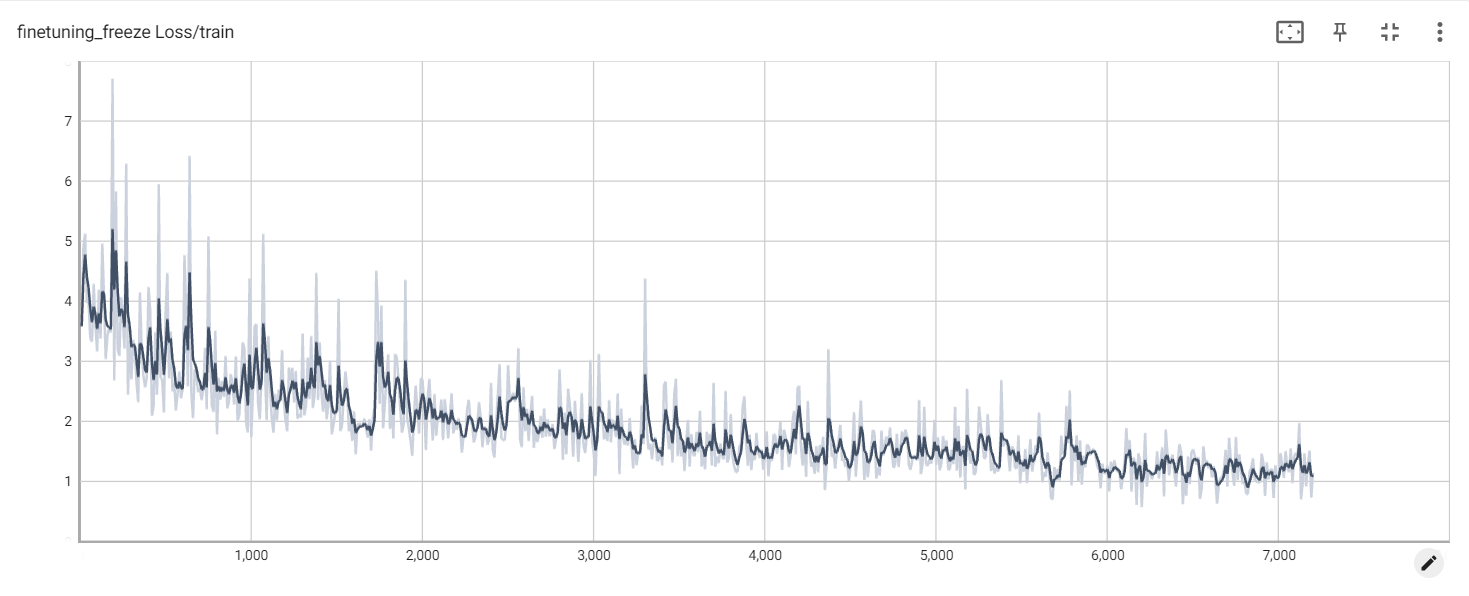
perte d'intégration 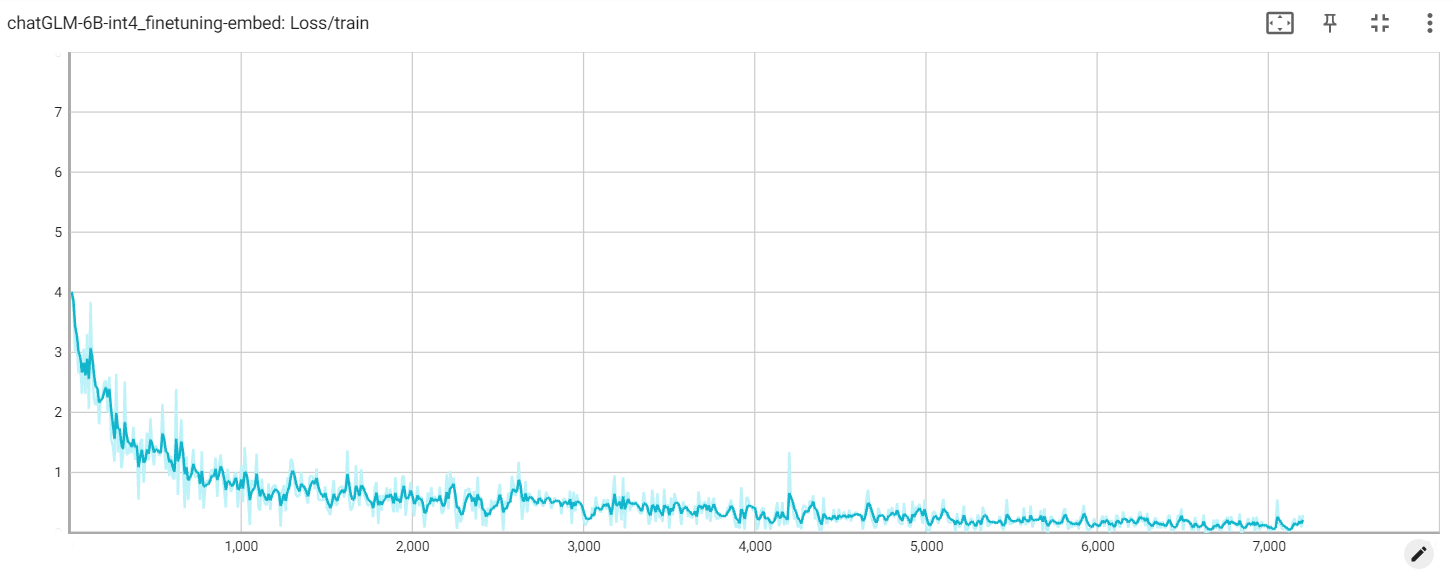
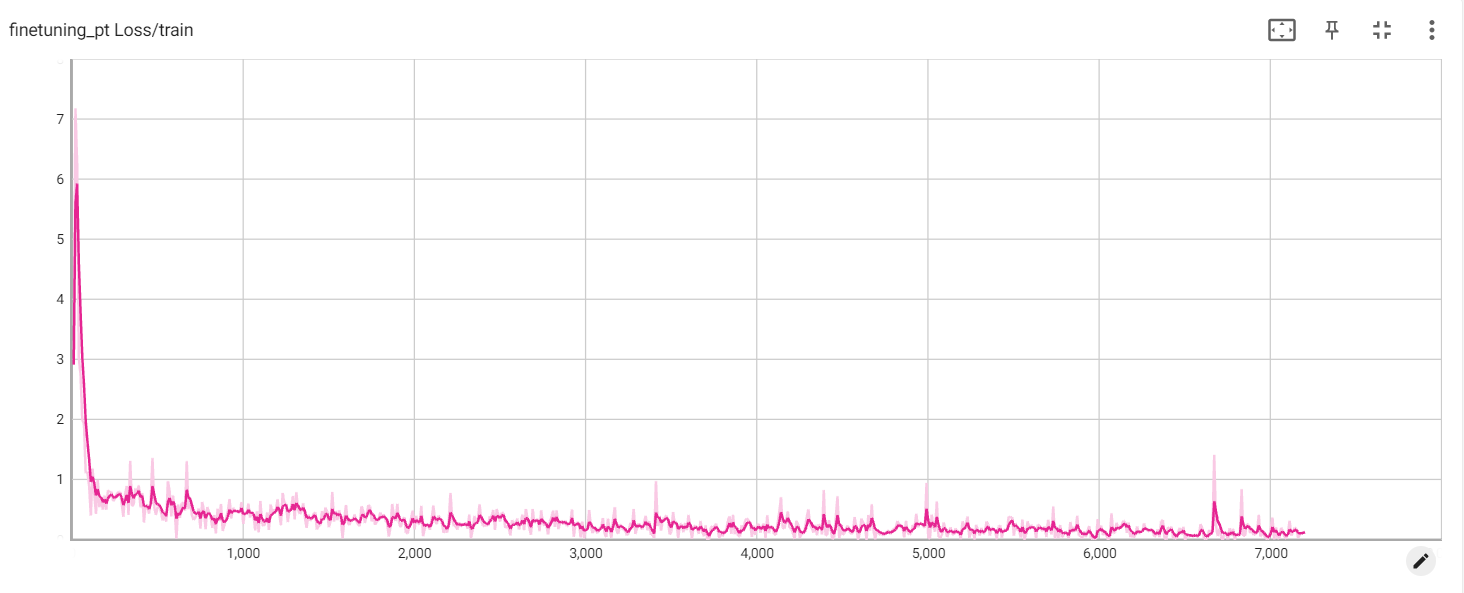
Perte de pt