ChatGLM 6B finetuning
1.0.0
このプロジェクトは、ChatGlm-6B-INT4モデルのさまざまな方法(Freeze Embeding Pt lora)の微調整に焦点を当て、主に情報抽出タスク、生成タスク、分類タスクなどの大きなモデルに対するさまざまな微調整方法の効果を比較します。
また、chatglm-6bの他のバージョン(PF16など)を微調整する場合は、に対応するバージョンをアップテートする必要があります。
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
https://huggingface.co/thudm/chatglm-6bで
元のモデルのパラメーターは凍結されています。たとえば、モデルの背後にあるレイヤーのみをトレーニングできます。
最終トレーニングのパラメーターは次のとおりです。
訓練可能なパラマグル:81920 ||すべてのパラメージ:3.356b ||トレーニング可能な%:0.0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
モデルを完全にフリーズし、ソフトプロンプトの1つとしてモデルのエディング部分のみをトレーニングします。
最終トレーニングのパラメーターは次のとおりです。
トレーニング可能なパラマグル:0.53b ||すべてのパラメージ:3.356b ||トレーニング可能な%:15.9
be train layer: transformer.word_embeddings.weight
Pチューニング-V2ソフトプロンプトの改善、P-Tuning-V2は埋め込み層だけでなく、各層に連続トークンが挿入され、変化と相互作用の量が増加します。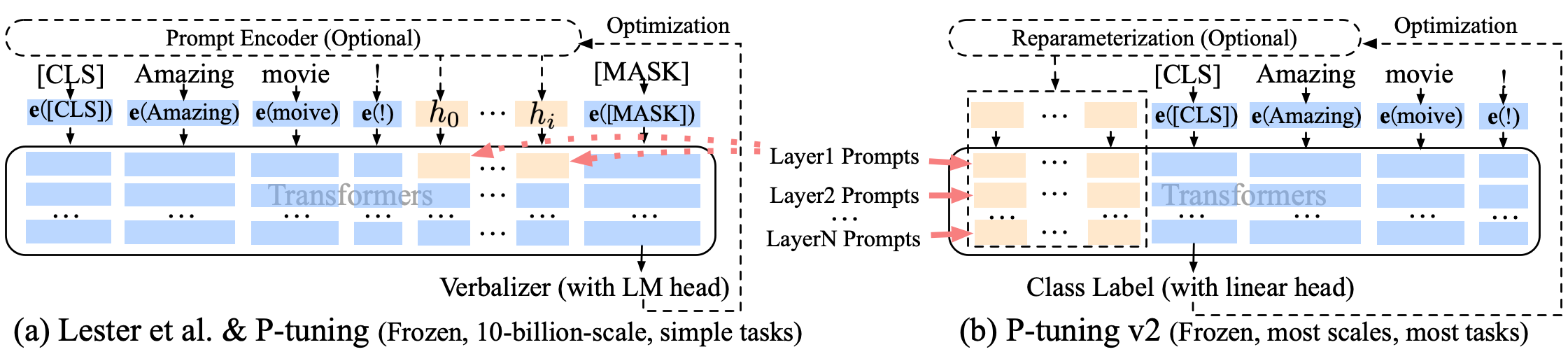
最終トレーニングのパラメーターは次のとおりです。
トレーニング可能なパラマグル:0.957b ||すべてのパラメージ:4.312b ||トレーニング可能な%:22.18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
Loraは、事前に訓練された重量を凍結しながら、代わりに適応中の密な層の変化のランク分解マトリックスを最適化することにより、間接的にニューラルネットワークでいくつかの密な層を訓練することができます。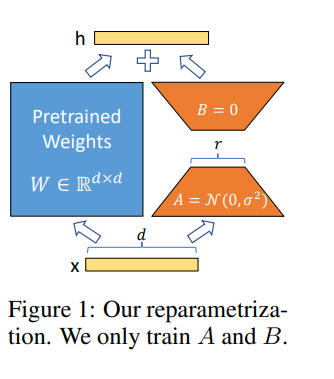
A100-40GでGoogle Colab Proでモデルを微調整するので、 Colabに何かをインストールする必要があります。
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
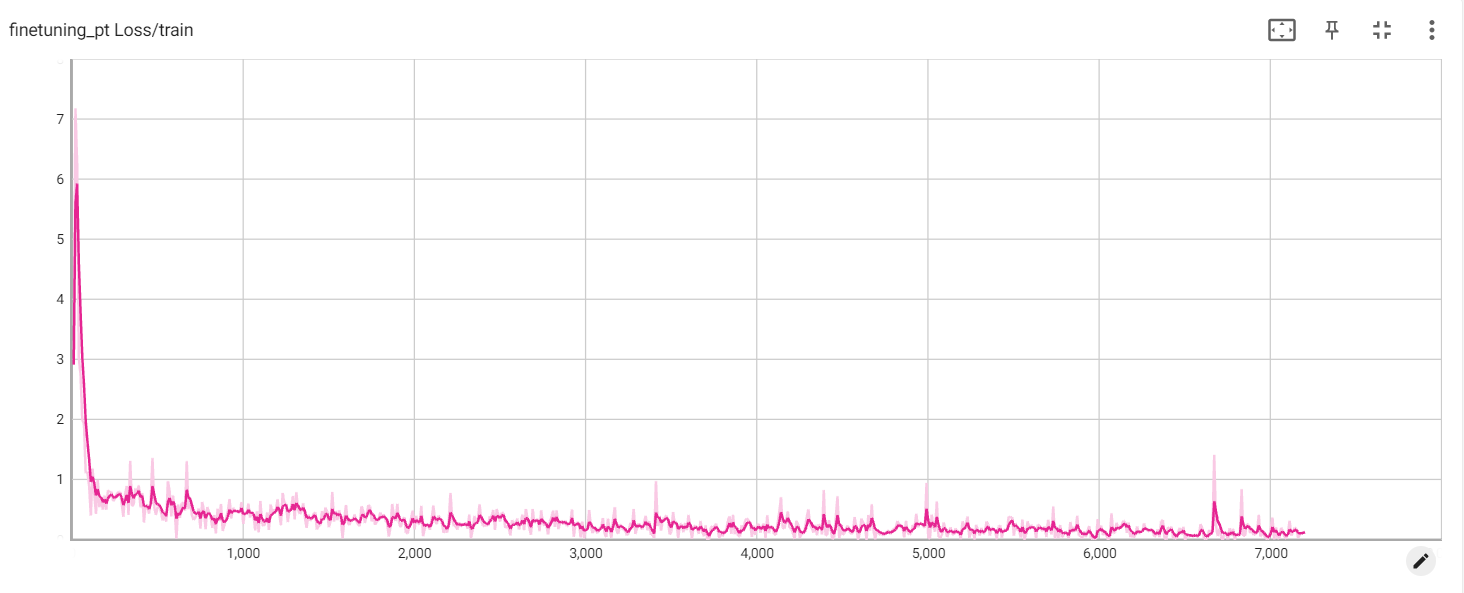
凍結損失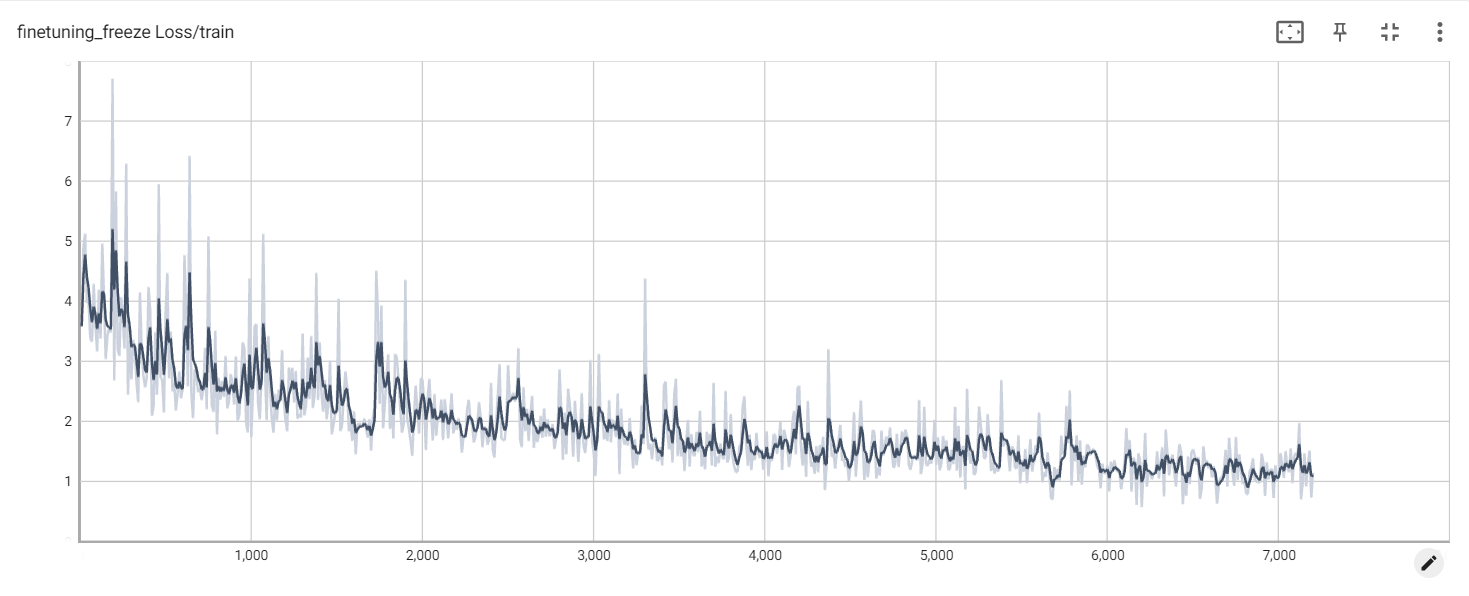
埋め込み損失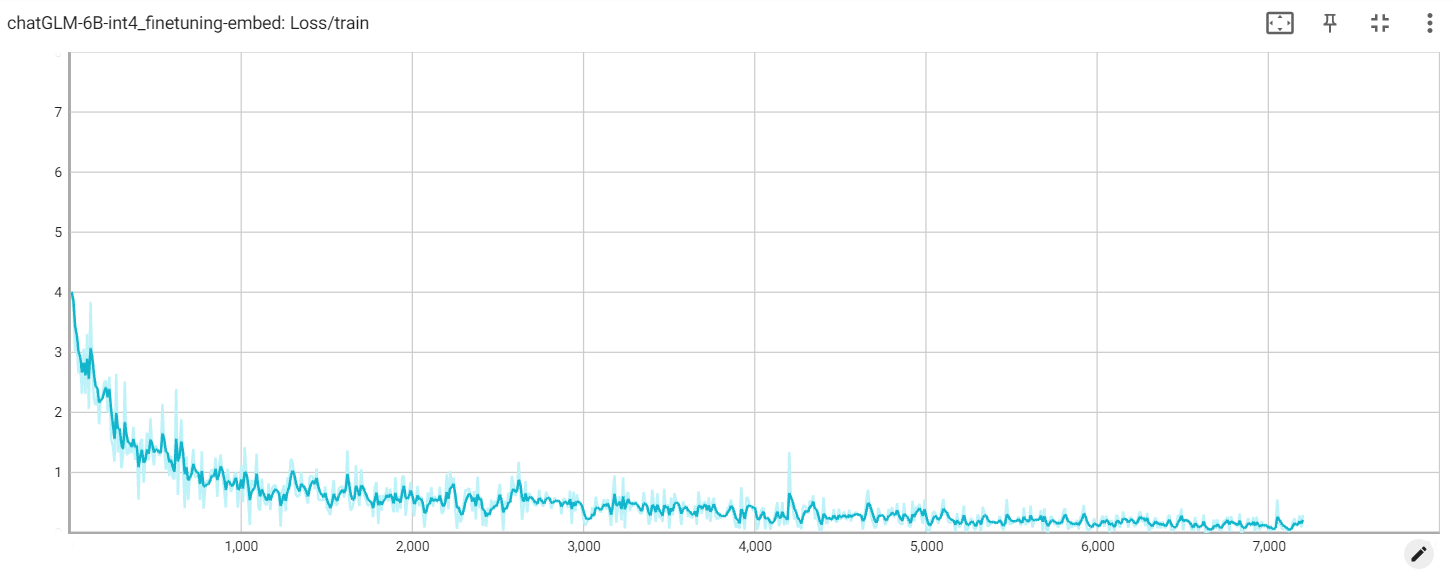
PT損失