ChatGLM 6B finetuning
1.0.0
يركز هذا المشروع على الضبط الدقيق لنموذج chatglm-6b-int4 بطرق مختلفة (تجميد تضمين pt lora) ، ومقارنة تأثير طرق ضبط دقة مختلفة على النموذج الكبير ، بشكل أساسي لمهمة استخراج المعلومات ، ومهمة التوليد ، ومهمة التصنيف ، وما إلى ذلك.
وإذا قمت بضبط إصدار آخر من chatglm-6b (مثل PF16) ، فأنت بحاجة إلى رفع الإصدار المقابل
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
في https://huggingface.co/thudm/Chatglm-6b
يتم تجميد معلمات النموذج الأصلي. على سبيل المثال ، يمكن تدريب الطبقة وراء النموذج فقط.
معلمات التدريب النهائي هي كما يلي :
المعاملات القابلة للتدريب: 81920 || جميع المعلمات: 3.356b || ٪ Trainable: 0.0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
قم بتجميد النموذج بالكامل وقم بتدريب جزء eBedding فقط من النموذج باعتباره أحد الطرق المطالبة الناعمة.
معلمات التدريب النهائي هي كما يلي :
المعاملات القابلة للتدريب: 0.53b || جميع المعلمات: 3.356b || ٪ Trainable: 15.9
be train layer: transformer.word_embeddings.weight
P ضبط p-tuning-V2 تحسن موجه ناعم ، فإن p-tuning-V2 ليس فقط لطبقة التضمين ، ولكن يتم إدخال الرموز المتواصلة في كل طبقة ، مما يزيد من مقدار التغيير والتفاعل.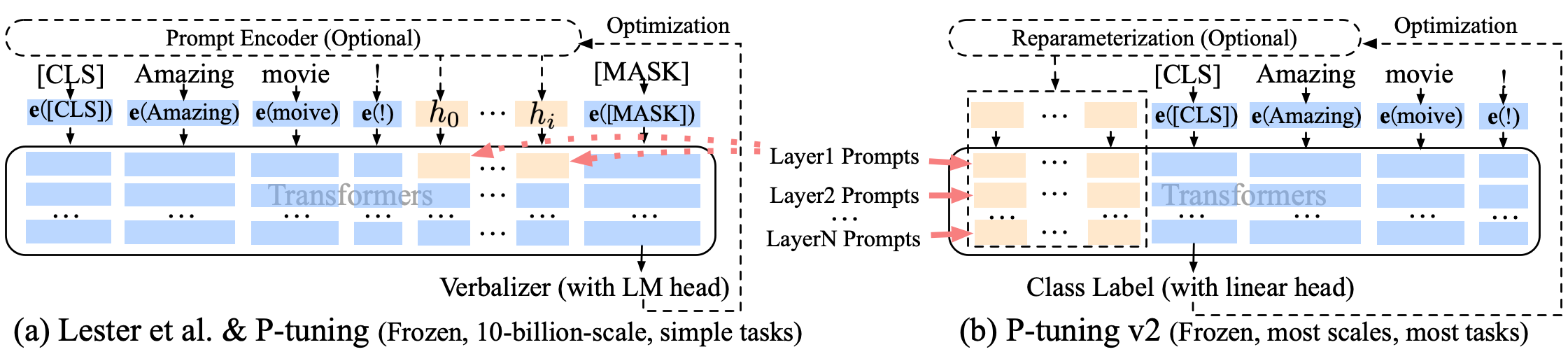
معلمات التدريب النهائي هي كما يلي :
المعاملات القابلة للتدريب: 0.957B || جميع المعلمات: 4.312b || ٪ Trainable: 22.18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
تسمح لنا Lora بتدريب بعض الطبقات الكثيفة في شبكة عصبية بشكل غير مباشر عن طريق تحسين مصفوفات التحلل في الترتيب لتغيير الطبقات الكثيفة أثناء التكيف بدلاً من ذلك ، مع الحفاظ على الأوزان المدربة مسبقًا.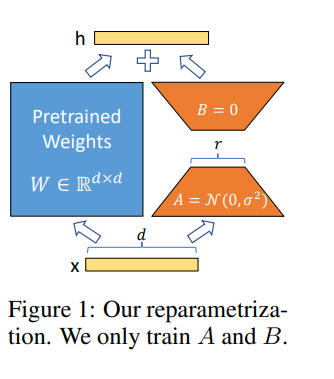
ضبط النموذج في Google Colab Pro مع A100-40G ، لذلك تحتاج إلى تثبيت Somethings في كولاب :
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
تجميد الخسارة 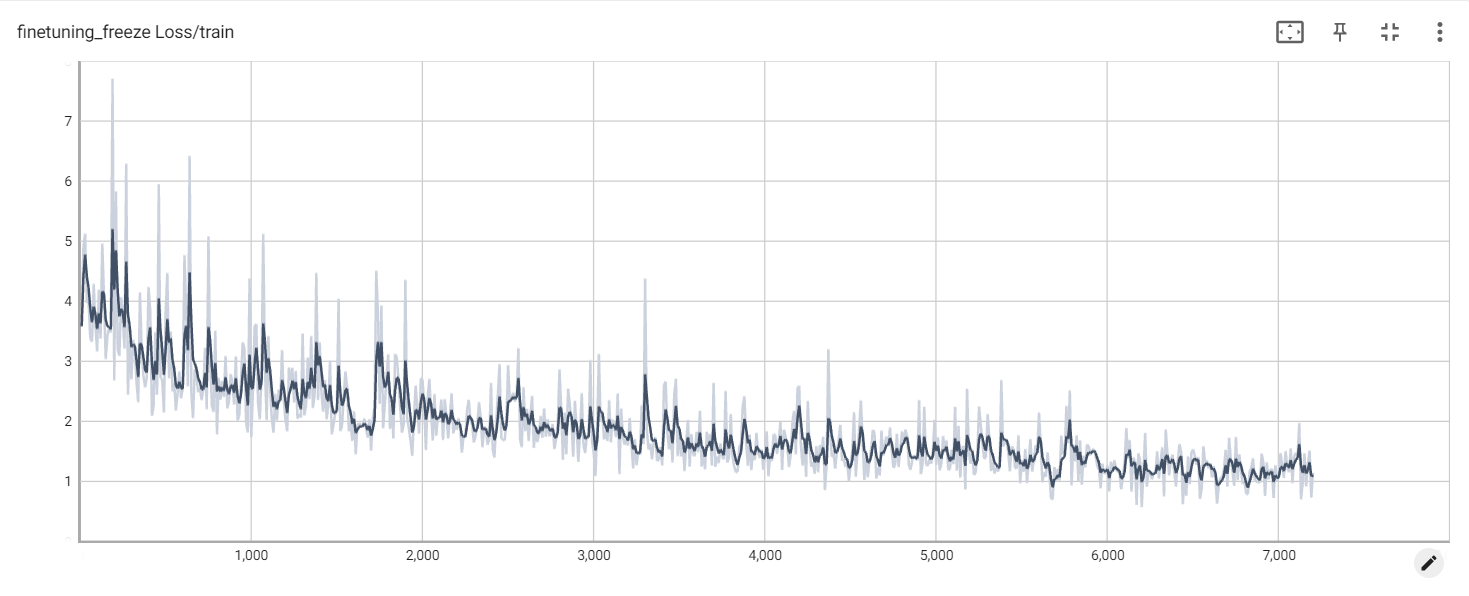
التضمين فقدان 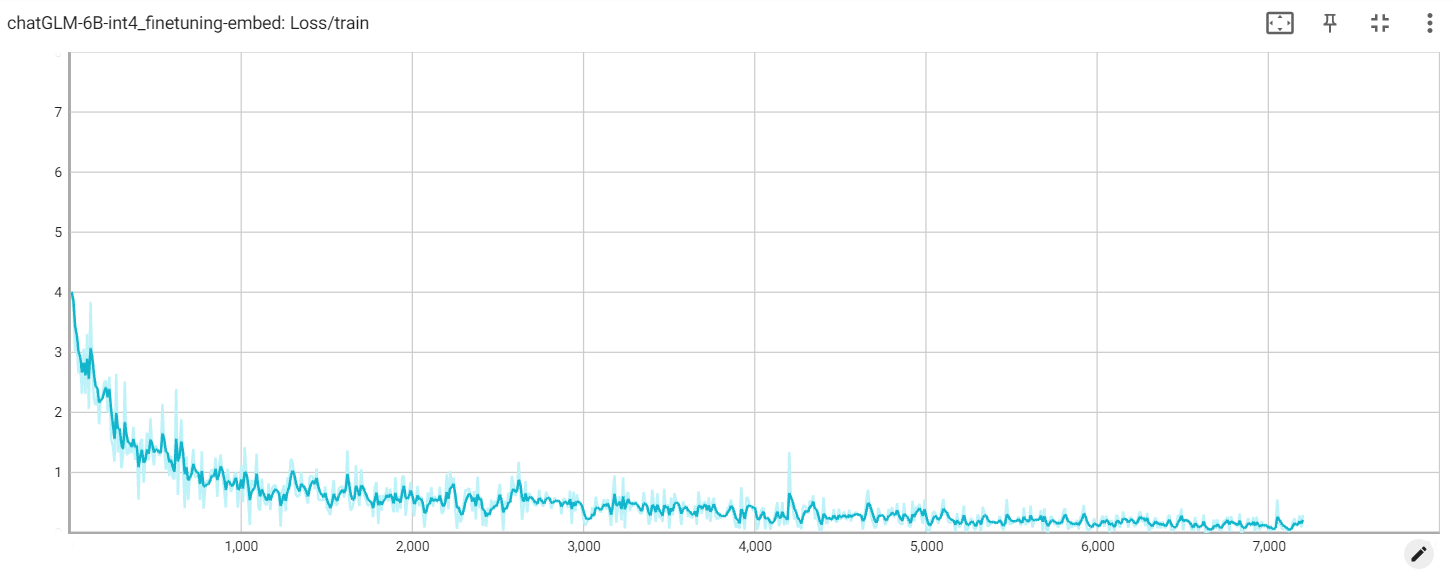
خسارة حزب العمال