ChatGLM 6B finetuning
1.0.0
이 프로젝트는 다양한 방식으로 ChatGlm-6b-Int4 모델의 미세 조정에 중점을두고 (Freeze Embeding PT LORA), 주로 정보 추출 작업, 생성 작업, 분류 작업 등을위한 대형 모델에 대한 다양한 미세 조정 방법의 효과를 비교합니다.
그리고 다른 버전의 ChatGLM-6B (PF16과 같은)를 미세 조정하는 경우 해당 버전을 업데이트해야합니다.
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
https://huggingface.co/thudm/chatglm-6b에서
원래 모델의 매개 변수는 동결됩니다. 예를 들어, 모델 뒤의 레이어 만 훈련 할 수 있습니다.
최종 훈련의 매개 변수는 다음과 같습니다.
훈련 가능한 매개 변수 : 81920 || 모든 매개 변수 : 3.356b || 훈련 가능%: 0.0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
모델을 완전히 동결하고 모델의 ebedding 부분 만 소프트 프롬프트 방법 중 하나로 훈련하십시오.
최종 훈련의 매개 변수는 다음과 같습니다.
훈련 가능한 매개 변수 : 0.53B || 모든 매개 변수 : 3.356b || 훈련 가능%: 15.9
be train layer: transformer.word_embeddings.weight
p 튜닝 p- 튜닝 -V2 소프트 프롬프트 개선, p- 튜닝 -V2는 임베딩 층을위한 것이 아니라 각 층에 연속 토큰이 삽입되어 변화의 양과 상호 작용을 증가시킵니다.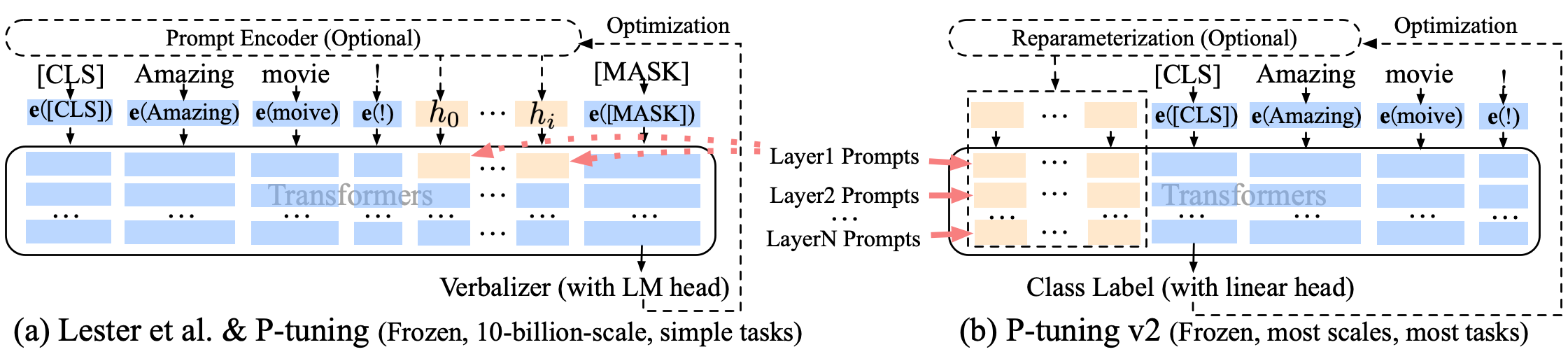
최종 훈련의 매개 변수는 다음과 같습니다.
훈련 가능한 매개 변수 : 0.957b || 모든 매개 변수 : 4.312b || 훈련 가능%: 22.18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
LORA는 적응 중 대신 밀집된 층의 변화의 순위 분해 매트릭스를 최적화하여 사전 훈련 된 가중치를 동결시키는 동시에 신경망에서 간접적으로 조밀 한 레이어를 훈련시킬 수 있습니다.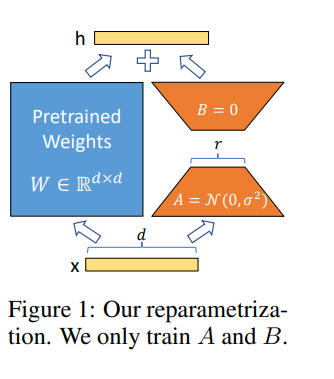
A100-40G 로 Google Colab Pro 의 모델을 미세 조정하므로 Colab 에서 Somethings를 설치해야합니다.
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
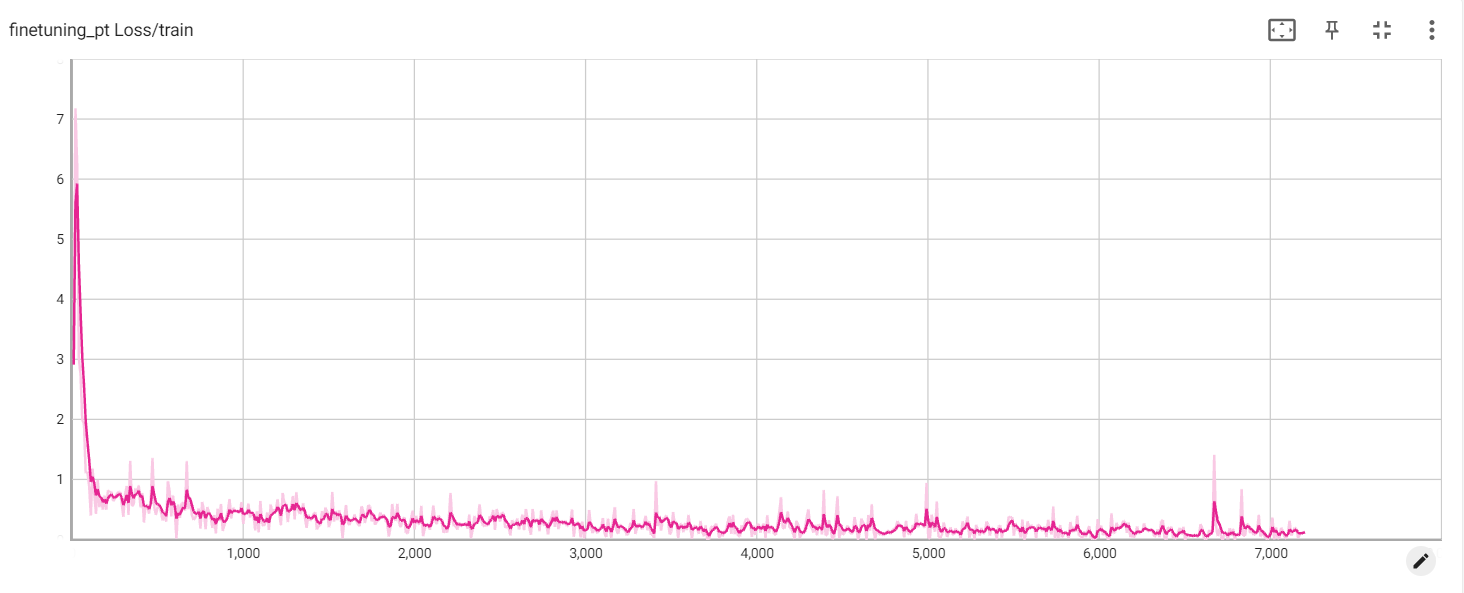
동결 손실 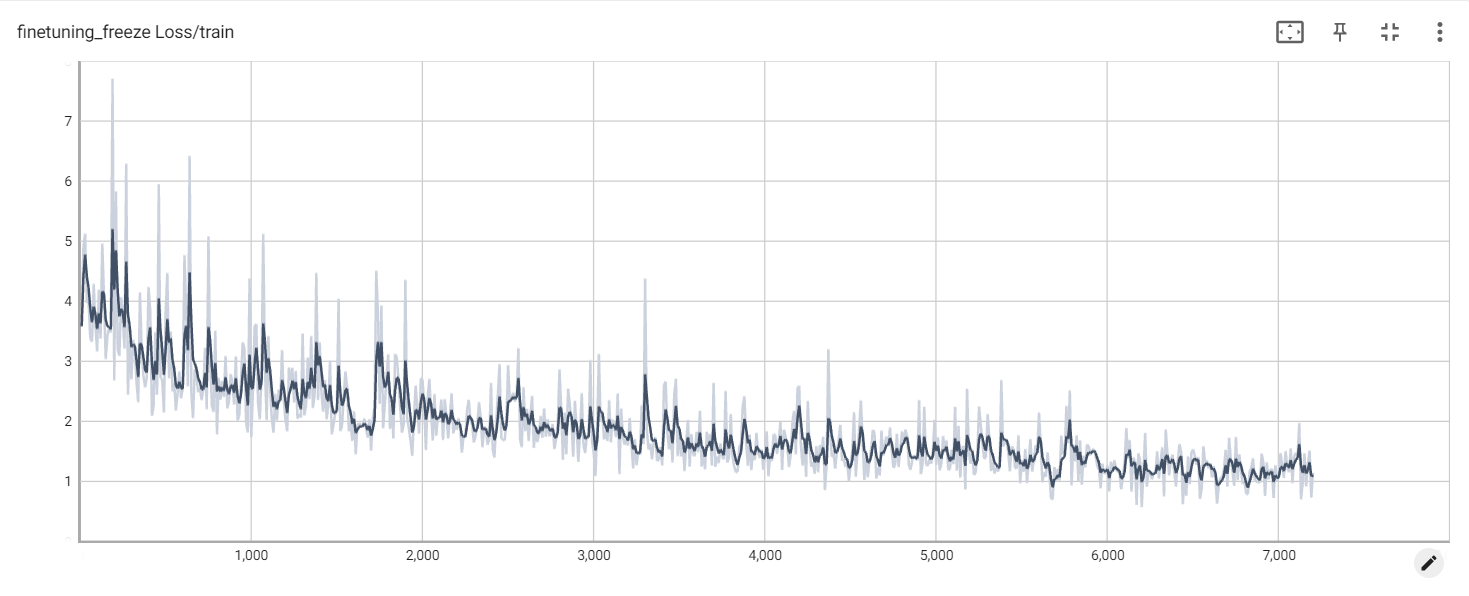
임베딩 손실 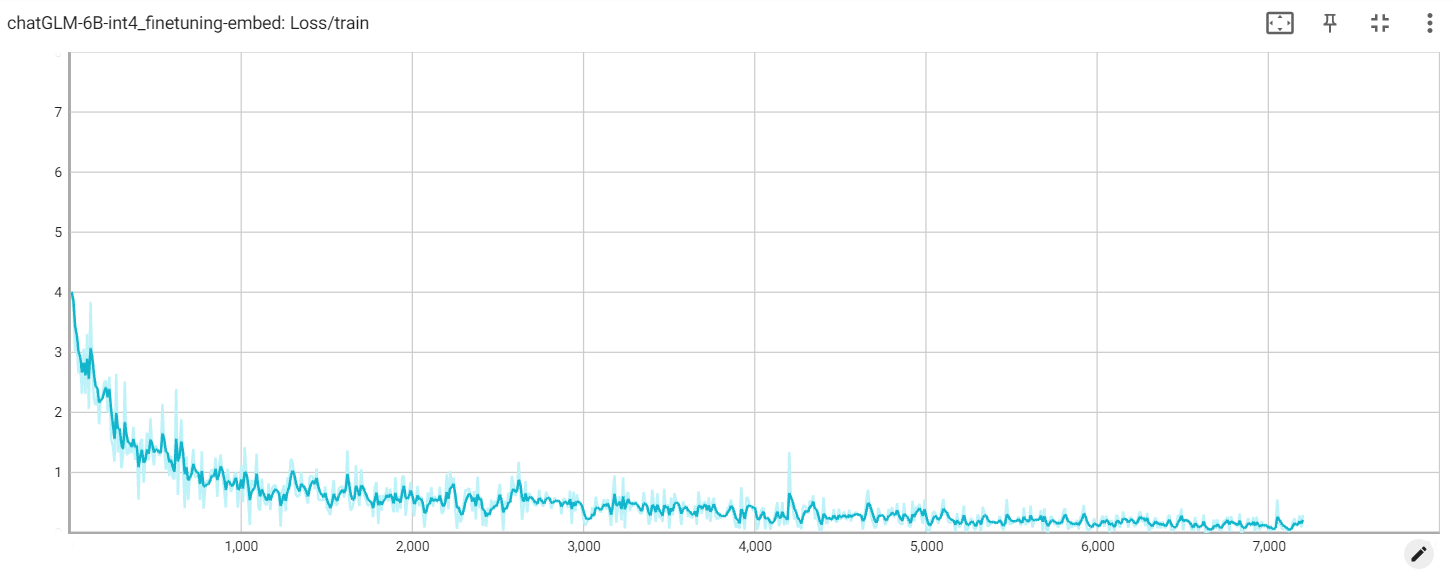
PT 손실