ChatGLM 6B finetuning
1.0.0
Este proyecto se centra en el ajuste fino del modelo CHATGLM-6B-INT4 de diferentes maneras (congelar incrustación pt lora), y comparando el efecto de diferentes métodos de ajuste fino en el modelo grande, principalmente para la tarea de extracción de información, tarea de generación, tarea de clasificación, etc.
Y si ajusta otra versión de ChatGlm-6b (como PF16), debe actualizar la versión correspondiente a
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
en https://huggingface.co/thudm/chatglm-6b
Los parámetros del modelo original están congelados. Por ejemplo, solo la capa detrás del modelo puede ser entrenada.
Los parámetros del entrenamiento final son los siguientes:
Parámetros capacitables: 81920 || Todos los parámetros: 3.356b || %capacitable: 0.0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
Congele el modelo por completo y entrene solo la parte del modelo como una de las formas de inmediato.
Los parámetros del entrenamiento final son los siguientes:
Parámetros capacitables: 0.53b || Todos los parámetros: 3.356b || %capacitable: 15.9
be train layer: transformer.word_embeddings.weight
Puning P-Tuning-V2 Una mejora de inmediato suave, P-Tuning-V2 no es solo para la capa de incrustación, sino que se insertan tokens continuos en cada capa, lo que aumenta la cantidad de cambio e interacción.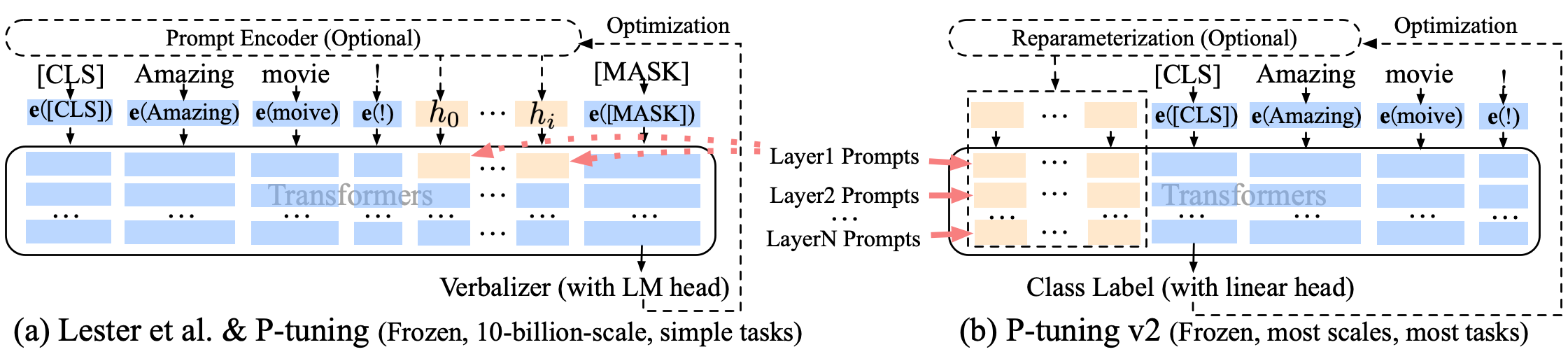
Los parámetros del entrenamiento final son los siguientes:
Parámetros capacitables: 0.957b || Todos los parámetros: 4.312b || %capacitable: 22.18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
Lora nos permite entrenar algunas capas densas en una red neuronal indirectamente optimizando las matrices de descomposición de rango del cambio de las capas densas durante la adaptación, al tiempo que mantiene los pesos previamente entrenados congelados.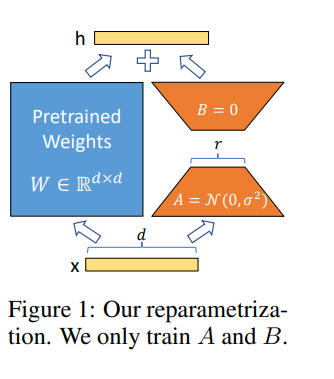
Ajustar el modelo en Google Colab Pro con A100-40G , por lo que debe instalar algo en Colab :
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
Pérdida de congelación 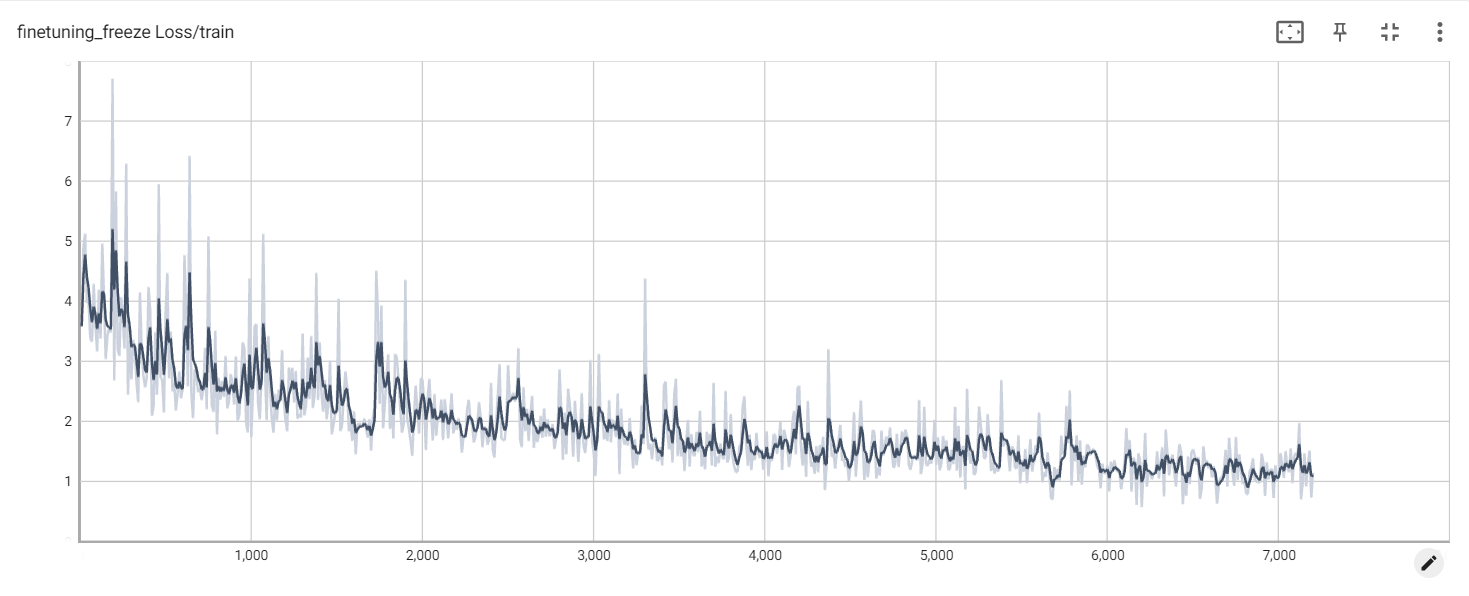
incrustación de pérdida 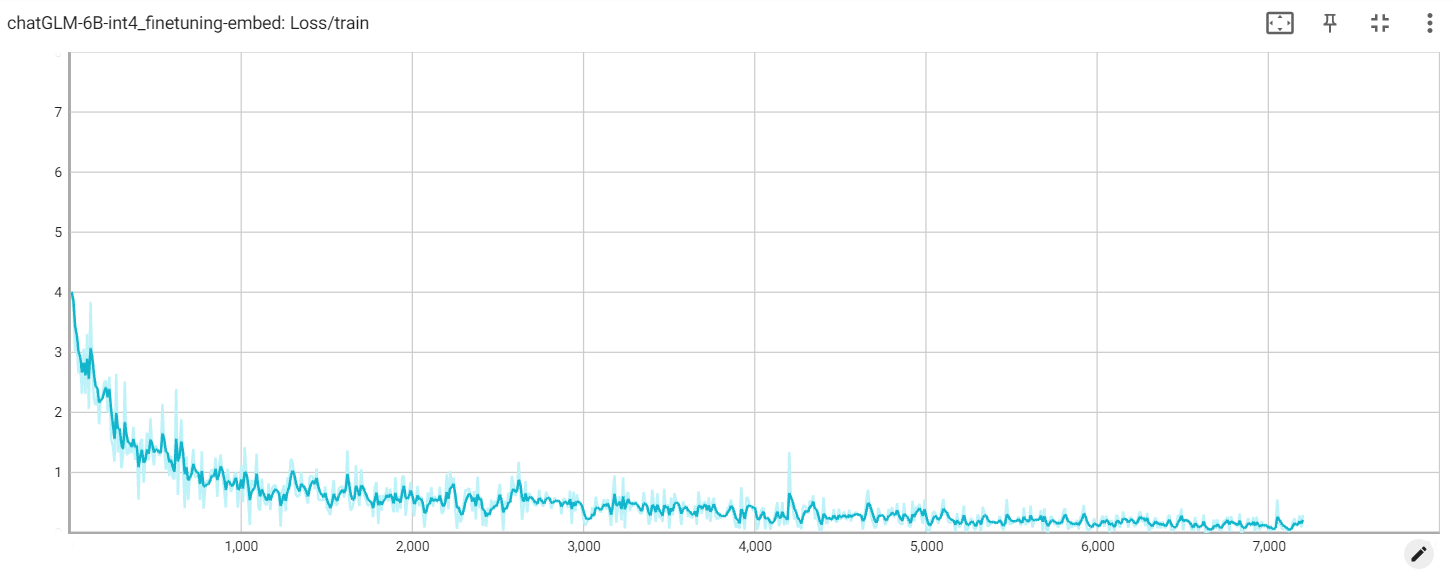
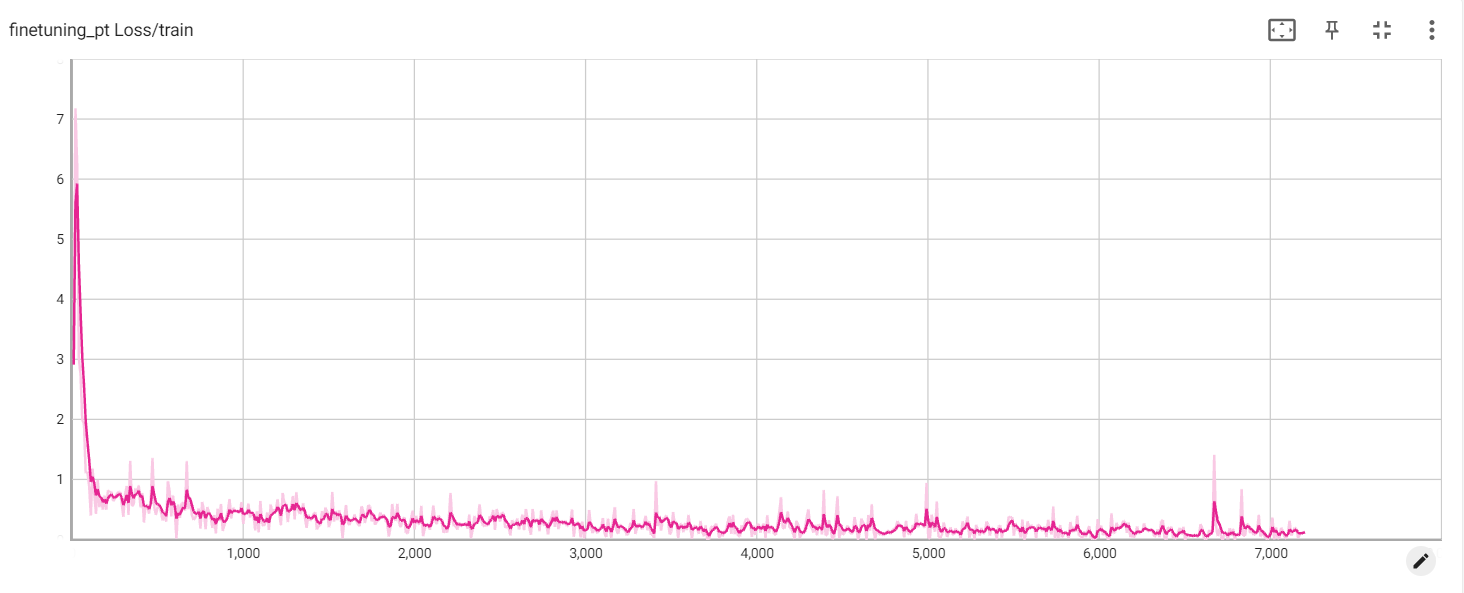
Pérdida de PT