ChatGLM 6B finetuning
1.0.0
Dieses Projekt konzentriert sich auf die Feinabstimmung des Chatglm-6b-int4-Modells auf unterschiedliche Weise (Freeze Embeding Pt Lora) und den Vergleich der Auswirkungen verschiedener Feinabstimmungsmethoden auf das große Modell, hauptsächlich für Informationsextraktionsaufgaben, Erzeugungsaufgabe, Klassifizierungsaufgabe usw.
Und wenn Sie eine andere Version von Chatglm-6b (wie PF16) bestrafen, müssen Sie die Version entsprechend entsprechen
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
In https://huggingface.co/thudm/chatglm-6b
Die Parameter des ursprünglichen Modells sind eingefroren. Beispielsweise kann nur die Schicht hinter dem Modell trainiert werden.
Die Parameter des endgültigen Trainings sind wie folgt:
Trainingbare Parameter: 81920 || Alle Parameter: 3.356b || Trainingbar%: 0,0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
Frieren Sie das Modell vollständig ein und trainieren Sie nur den Ebending -Teil des Modells als eine der sanften Auszeichnungen.
Die Parameter des endgültigen Trainings sind wie folgt:
Trainingbare Paramien: 0,53B || Alle Parameter: 3.356b || Trainingbares%: 15,9
be train layer: transformer.word_embeddings.weight
P-Tuning P-Tuning-V2 Eine weiche Einlaufverbesserung, P-Tuning-V2 ist nicht nur für die Einbettungsschicht, sondern auch kontinuierliche Token in jede Schicht eingeführt, wodurch die Änderung und Wechselwirkung erhöht wird.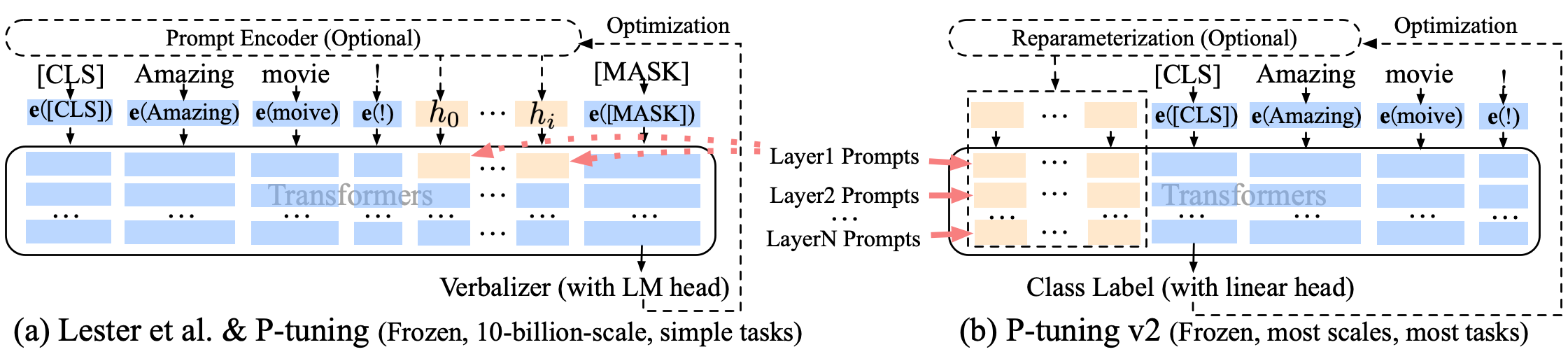
Die Parameter des endgültigen Trainings sind wie folgt:
Trainingbare Parameter: 0,957b || Alle Parameter: 4.312B || Trainingbar%: 22,18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
Lora ermöglicht es uns, einige dichte Schichten in einem neuronalen Netzwerk indirekt zu schulen, indem wir die Rang-Zersetzungsmatrizen der Änderung der dichten Schichten während der Anpassung stattdessen optimieren und gleichzeitig die vorgeschriebenen Gewichte gefroren halten.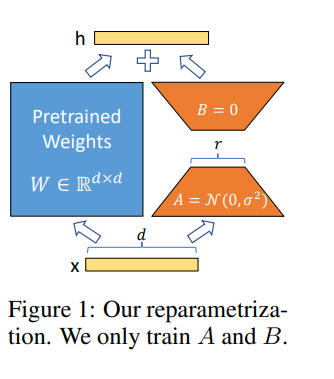
Feinstimmen Sie das Modell in Google Colab Pro mit A100-40G , sodass Sie etwas in Colab installieren müssen:
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
Gefrierverlust 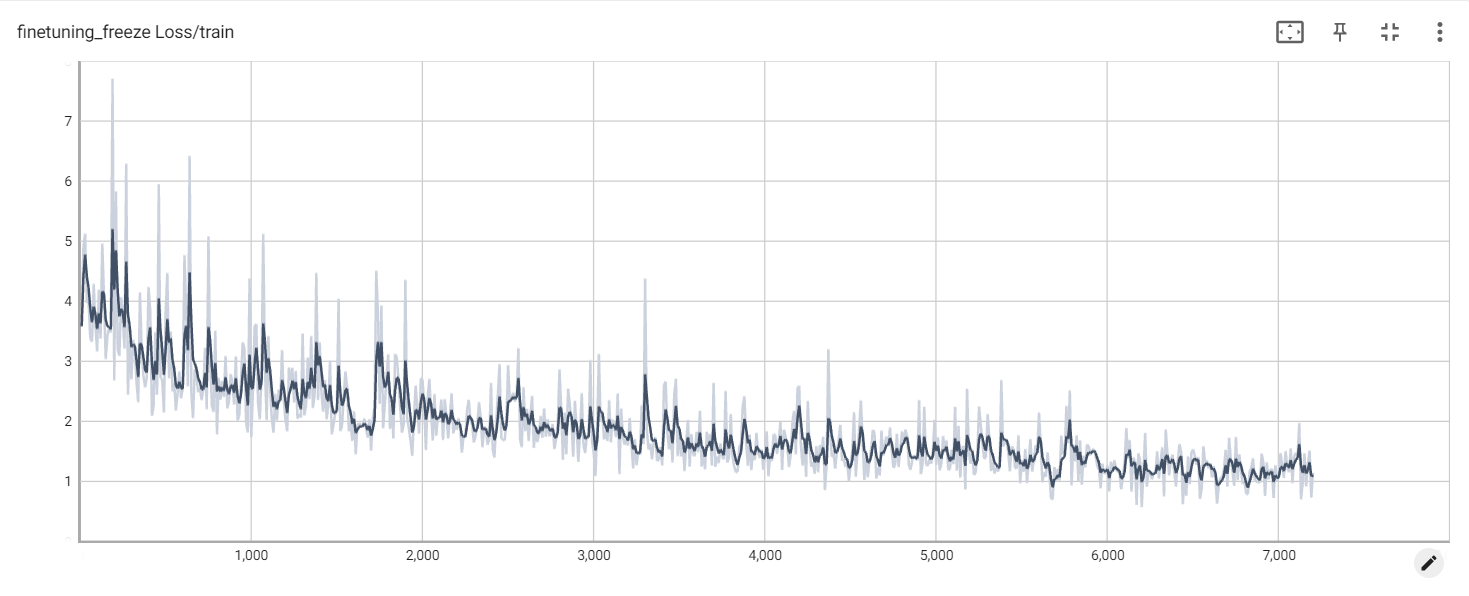
Verlust einbetten 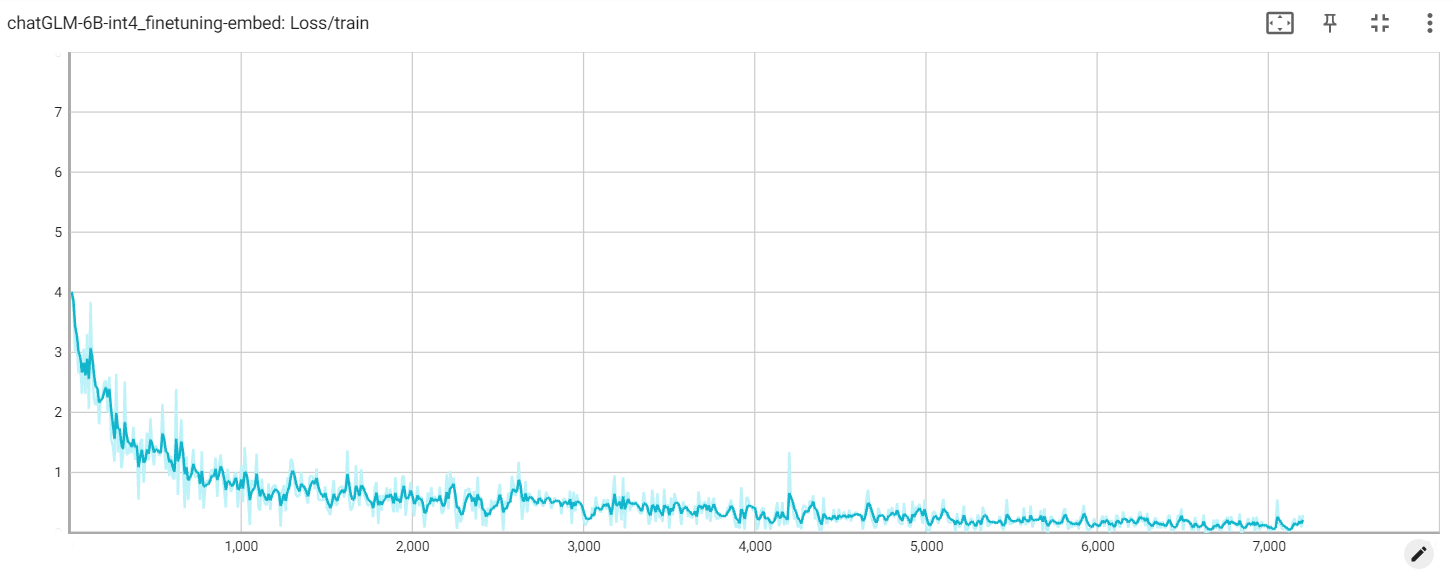
Pt -Verlust