ChatGLM 6B finetuning
1.0.0
Proyek ini berfokus pada fine tuning model chatglm-6b-int4 dengan cara yang berbeda (beku embeding pt lora), dan membandingkan efek metode penyetelan fine yang berbeda pada model besar, terutama untuk tugas ekstraksi informasi, tugas pembuatan, tugas klasifikasi, dll.
Dan jika Anda menyempurnakan versi chatglm-6b lainnya (seperti PF16), Anda perlu meningkatkan versi yang sesuai
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
di https://huggingface.co/thudm/chatglm-6b
Parameter model asli dibekukan. Misalnya, hanya lapisan di belakang model yang dapat dilatih.
Parameter pelatihan akhir adalah sebagai berikut :
Paramsable Params: 81920 || Semua Params: 3.356b || %yang dapat dilatih: 0,0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
Bekukan model sepenuhnya dan latih hanya bagian dari model sebagai salah satu cara cepat yang lembut.
Parameter pelatihan akhir adalah sebagai berikut :
Paramsable Params: 0,53b || Semua Params: 3.356b || %Dapat dilatih: 15.9
be train layer: transformer.word_embeddings.weight
Puning p-tuning-v2 Perbaikan prompt lunak, p-tuning-V2 tidak hanya untuk lapisan penyematan, tetapi token terus menerus dimasukkan ke dalam setiap lapisan, meningkatkan jumlah perubahan dan interaksi.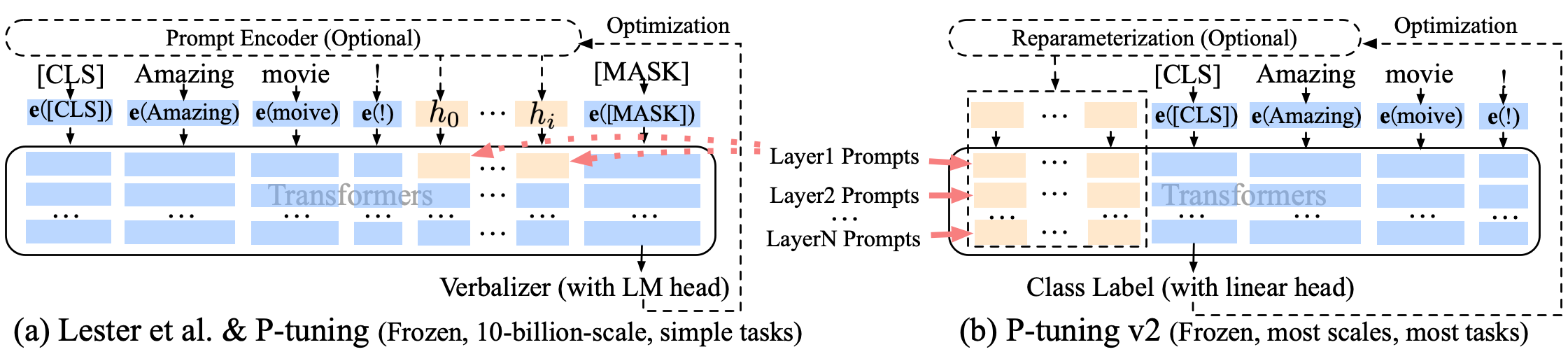
Parameter pelatihan akhir adalah sebagai berikut :
Paramsable Params: 0.957b || Semua Params: 4.312b || %yang dapat dilatih: 22.18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
Lora memungkinkan kita untuk melatih beberapa lapisan padat dalam jaringan saraf secara tidak langsung dengan mengoptimalkan matriks dekomposisi peringkat dari perubahan lapisan padat selama adaptasi sebagai gantinya, sambil menjaga bobot pra-terlatih membeku.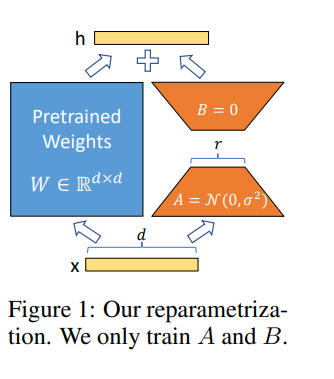
Menyempurnakan model di Google Colab Pro dengan A100-40G , jadi Anda perlu menginstal sesuatu di Colab :
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
Kerugian beku 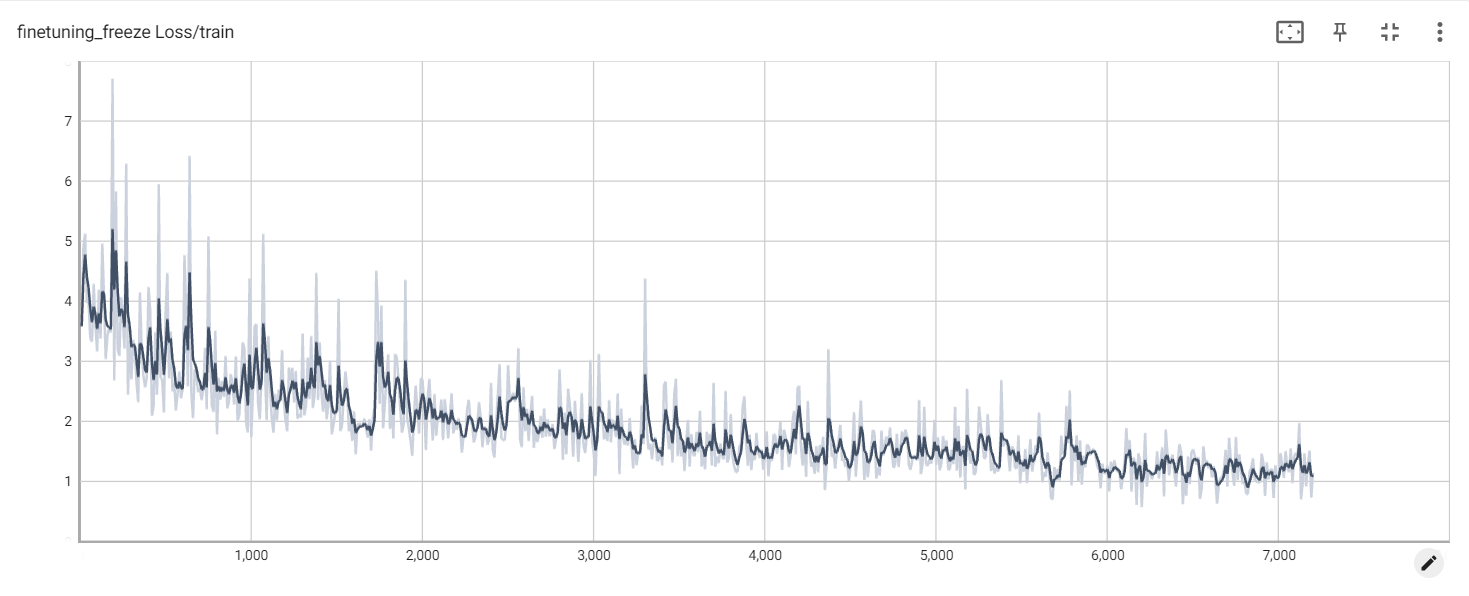
Kehilangan yang menanamkan 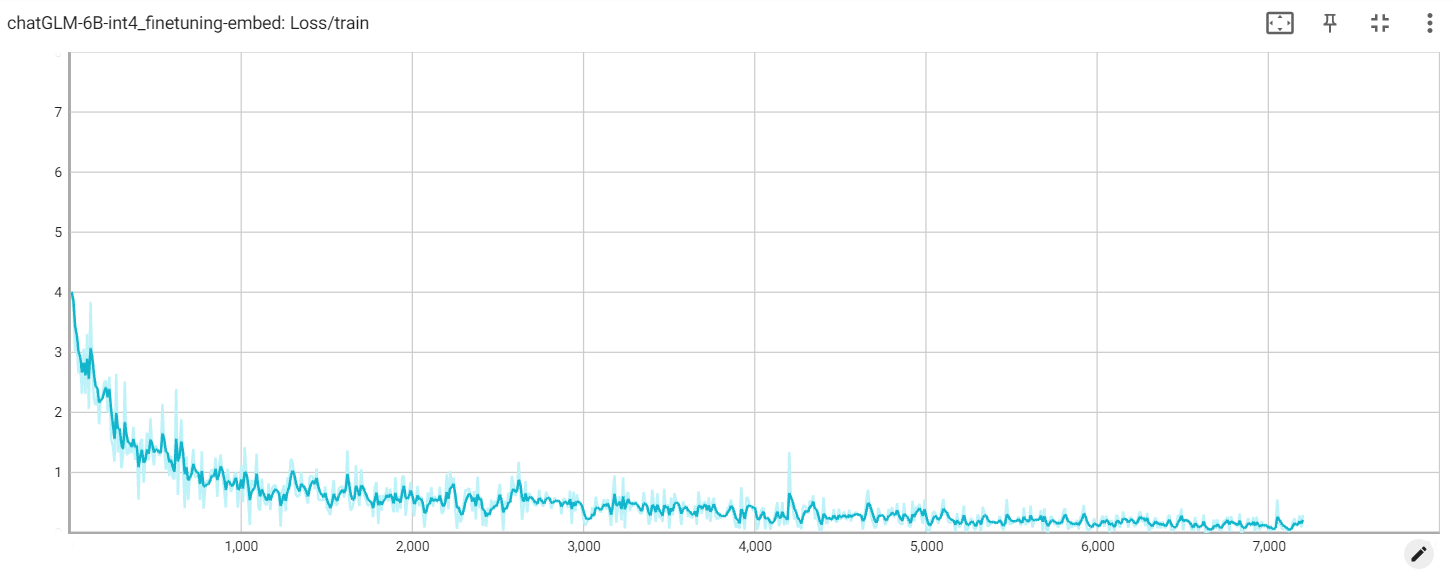
Kehilangan PT