ChatGLM 6B finetuning
1.0.0
Этот проект фокусируется на тонкой настройке модели ChatGLM-6B-Int4 по-разному (Freeze Enceding Pt Lora) и сравнение влияния различных методов тонкой настройки на большую модель, главным образом для задачи извлечения информации, задачи генерации, задачи классификации и т. Д.
И если вы прекрасно настраиваете другую версию Chatglm-6B (например, PF16), вам необходимо облегчить версию, соответствующую
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
в https://huggingface.co/thudm/chatglm-6b
Параметры исходной модели заморожены. Например, только слой позади модели может быть обучен.
Параметры окончательного обучения следующие:
Обучаемые параметры: 81920 || Все параметры: 3.356b || Тренируемый%: 0,0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
Полностью заморозите модель и обучайте только той части модели в качестве одного из мягких быстрых способов.
Параметры окончательного обучения следующие:
Обучаемые параметры: 0,53b || Все параметры: 3.356b || Тренируемый%: 15,9
be train layer: transformer.word_embeddings.weight
P-настройка P-TUNING-V2 Улучшение мягкого быстрого быстрого приглашения, P-TUNING-V2 предназначен не только для встраивания слоя, но и непрерывные токены вставляются в каждый слой, увеличивая количество изменений и взаимодействия.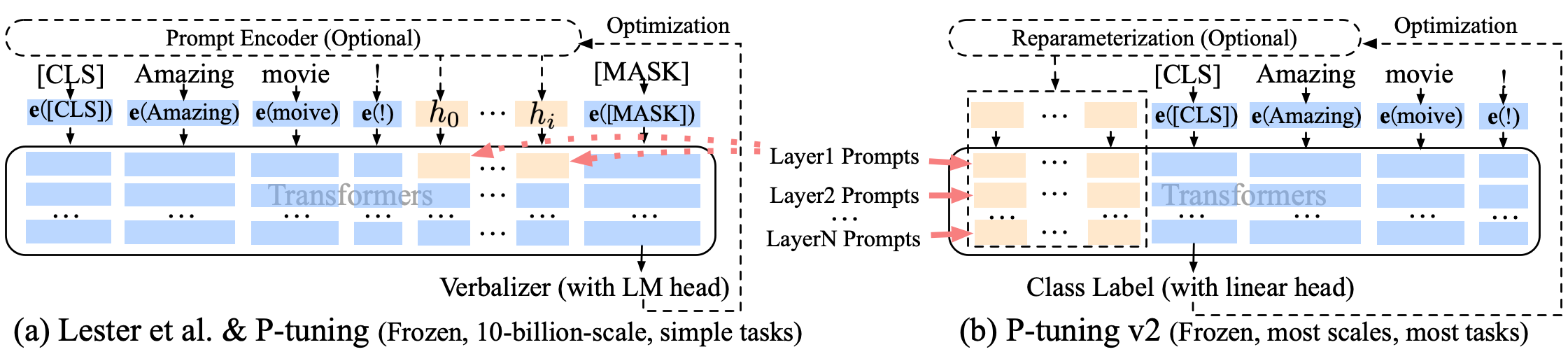
Параметры окончательного обучения следующие:
Тренируемые параметры: 0,957b || Все параметры: 4.312b || Тренируемый%: 22,18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
Лора позволяет нам косвенно обучать некоторых плотных слоев в нейронной сети, оптимизируя матрицы разложения ранга в изменении плотных слоев во время адаптации, сохраняя при этом замороженные предварительно обученные веса.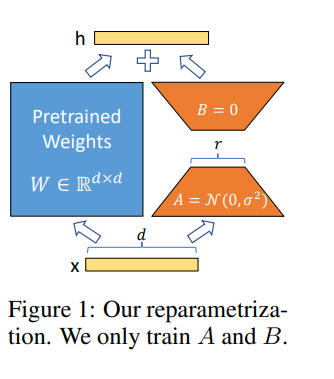
Прекрасная настройка модели в Google Colab Pro с A100-40G , поэтому вам нужно установить что-нибудь в Colab :
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
Заморозить потерю 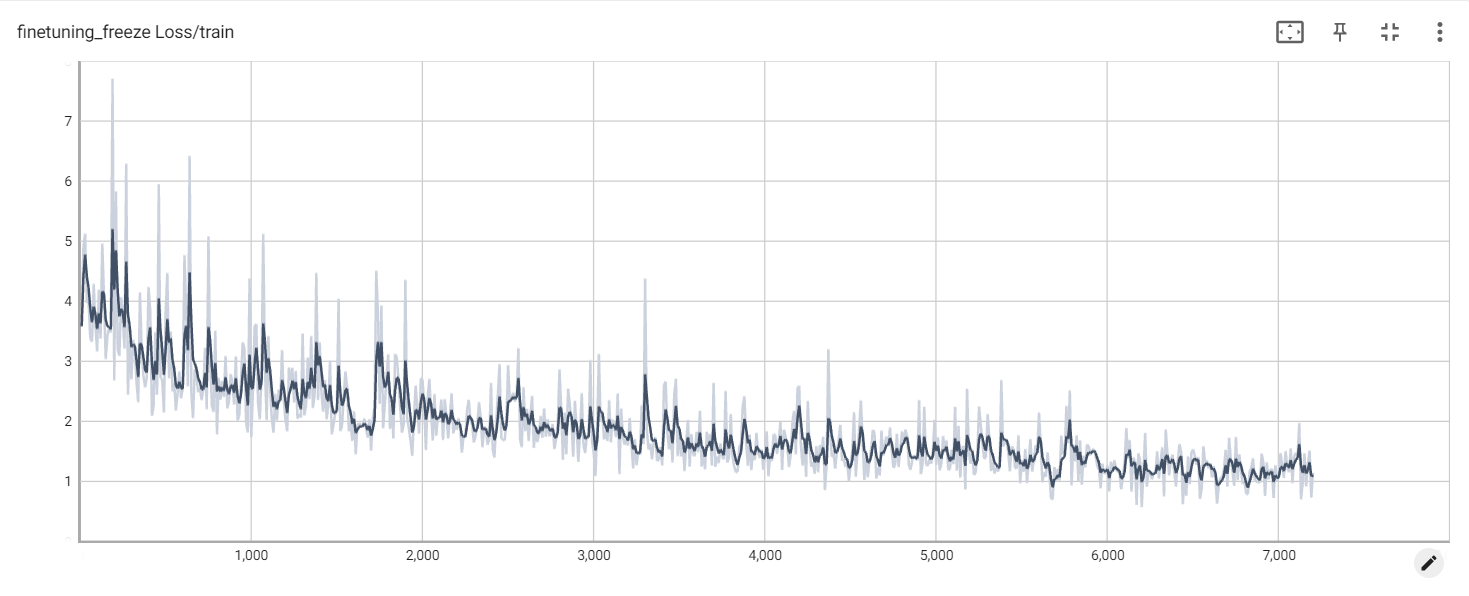
внедрение потери 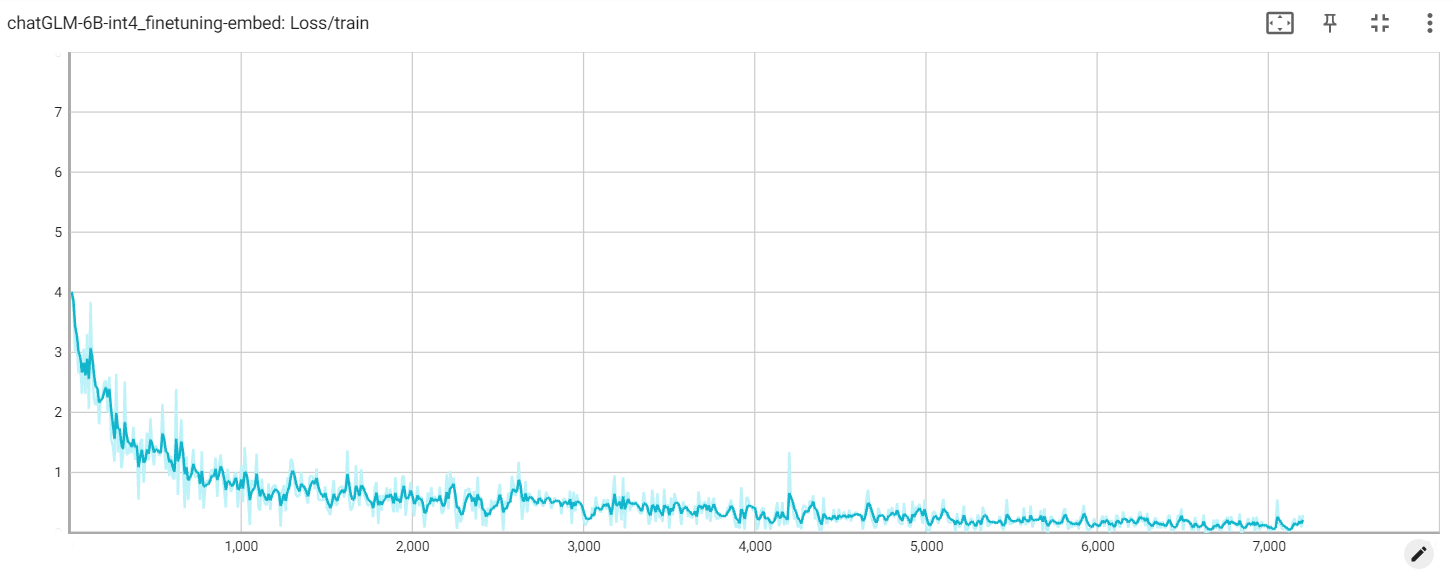
Потеря PT