ChatGLM 6B finetuning
1.0.0
โครงการนี้มุ่งเน้นไปที่การปรับแต่งอย่างละเอียดของโมเดล chatglm-6b-int4 ในรูปแบบที่แตกต่างกัน (Freeze Embeding pt lora) และเปรียบเทียบผลของวิธีการปรับแต่งที่แตกต่างกันในโมเดลขนาดใหญ่ส่วนใหญ่สำหรับงานสกัดข้อมูลงานสร้างงานการจำแนก
และถ้าคุณปรับจูนรุ่นอื่น ๆ ของ Chatglm-6b (เช่น PF16) คุณต้องปรับรุ่นที่สอดคล้องกับ
configuration_chatglm.py
quantization.py
modeling_chatglm.py
tokenization_chatglm.py
test_modeling_chatglm.py
tokenization_chatglm.py
ใน https://huggingface.co/thudm/chatglm-6b
พารามิเตอร์ของโมเดลดั้งเดิมถูกแช่แข็ง ตัวอย่างเช่นมีเพียงเลเยอร์ที่อยู่ด้านหลังโมเดลเท่านั้น
พารามิเตอร์ของการฝึกอบรมขั้นสุดท้ายมีดังนี้:
params ที่ฝึกได้: 81920 || พารามิเตอร์ทั้งหมด: 3.356b || ฝึกอบรมได้%: 0.0024
be train layer: transformer.layers.23.input_layernorm.weight
be train layer: transformer.layers.23.input_layernorm.bias
be train layer: transformer.layers.23.post_attention_layernorm.weight
be train layer: transformer.layers.23.post_attention_layernorm.bias
be train layer: transformer.layers.24.input_layernorm.weight
be train layer: transformer.layers.24.input_layernorm.bias
be train layer: transformer.layers.24.post_attention_layernorm.weight
be train layer: transformer.layers.24.post_attention_layernorm.bias
be train layer: transformer.layers.25.input_layernorm.weight
be train layer: transformer.layers.25.input_layernorm.bias
be train layer: transformer.layers.25.post_attention_layernorm.weight
be train layer: transformer.layers.25.post_attention_layernorm.bias
be train layer: transformer.layers.26.input_layernorm.weight
be train layer: transformer.layers.26.input_layernorm.bias
be train layer: transformer.layers.26.post_attention_layernorm.weight
be train layer: transformer.layers.26.post_attention_layernorm.bias
be train layer: transformer.layers.27.input_layernorm.weight
be train layer: transformer.layers.27.input_layernorm.bias
be train layer: transformer.layers.27.post_attention_layernorm.weight
be train layer: transformer.layers.27.post_attention_layernorm.bias
ตรึงโมเดลทั้งหมดและฝึกเฉพาะส่วน ebedding ของโมเดลเป็นหนึ่งในวิธีที่นุ่มนวล
พารามิเตอร์ของการฝึกอบรมขั้นสุดท้ายมีดังนี้:
params ที่ฝึกอบรมได้: 0.53b || พารามิเตอร์ทั้งหมด: 3.356b || ฝึกอบรมได้%: 15.9
be train layer: transformer.word_embeddings.weight
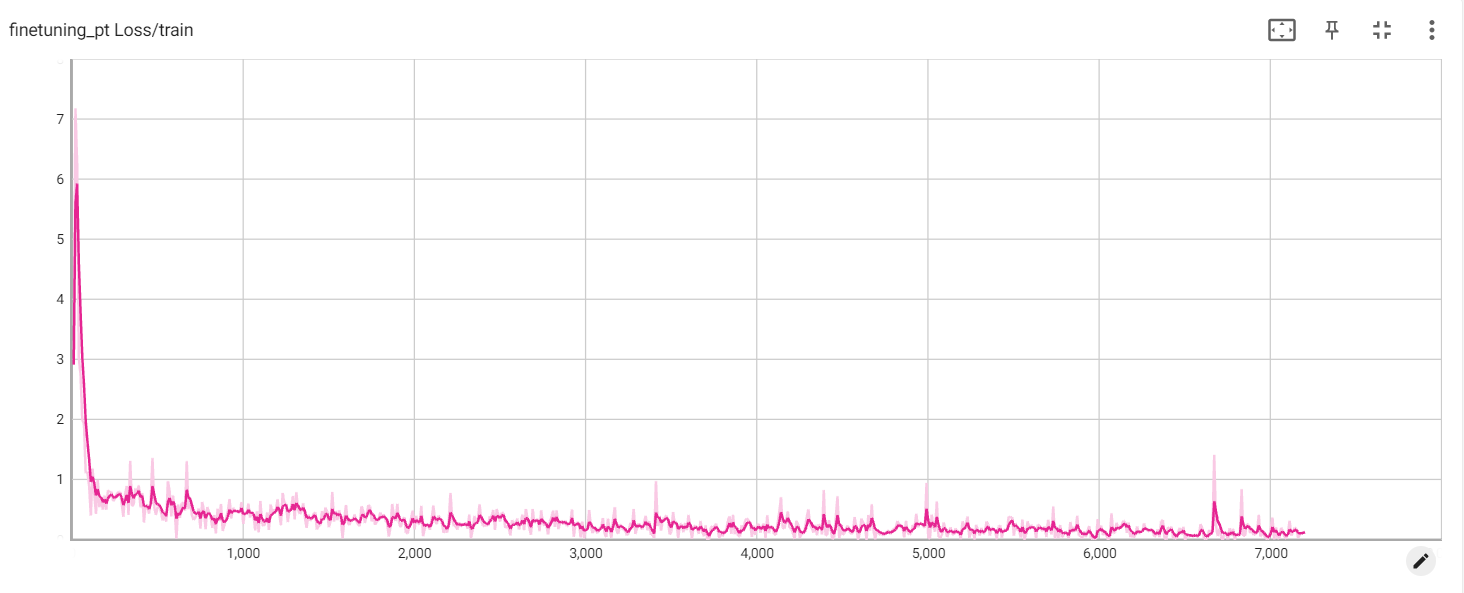
การปรับจูน P-tuning-V2 การปรับปรุงที่นุ่มนวล P-tuning-V2 ไม่เพียง แต่สำหรับเลเยอร์การฝังเท่านั้น แต่โทเค็นต่อเนื่องจะถูกแทรกเข้าไปในแต่ละชั้นเพิ่มปริมาณการเปลี่ยนแปลงและการโต้ตอบ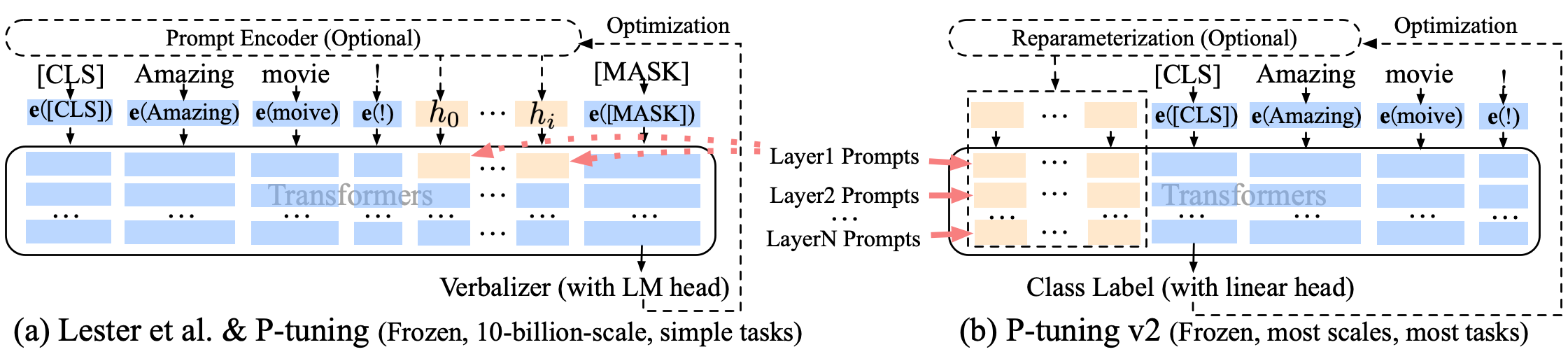
พารามิเตอร์ของการฝึกอบรมขั้นสุดท้ายมีดังนี้:
params ที่ฝึกได้: 0.957b || พารามิเตอร์ทั้งหมด: 4.312b || ฝึกอบรมได้%: 22.18
transformer.prefix_encoder.embedding.weight
transformer.prefix_encoder.trans.0.weight
transformer.prefix_encoder.trans.0.bias
transformer.prefix_encoder.trans.2.weight
transformer.prefix_encoder.trans.2.bias
LORA ช่วยให้เราสามารถฝึกอบรมเลเยอร์หนาแน่นในเครือข่ายประสาททางอ้อมโดยการเพิ่มประสิทธิภาพเมทริกซ์การสลายตัวของอันดับของการเปลี่ยนแปลงของชั้นหนาแน่นในระหว่างการปรับตัวแทนในขณะที่รักษาน้ำหนักที่ได้รับการฝึกอบรมไว้ล่วงหน้า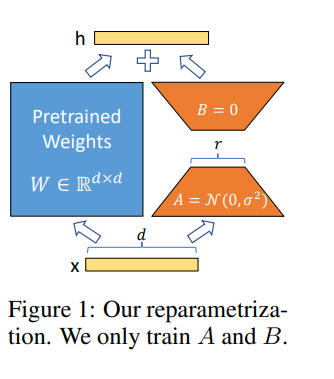 -
-
ปรับจูนโมเดลใน Google Colab Pro ด้วย A100-40G ดังนั้นคุณต้องส่งการติดตั้งใน Colab :
!pip install --upgrade tensorboard
!pip install --upgrade protobuf
!pip install transformers
!pip install sentencepiece
!pip install deepspeed
!pip install mpi4py
!pip install cpm_kernels
!pip install icetk
!pip install peft
!pip install tensorboard
!pip install tqdm
การสูญเสียการแช่แข็ง 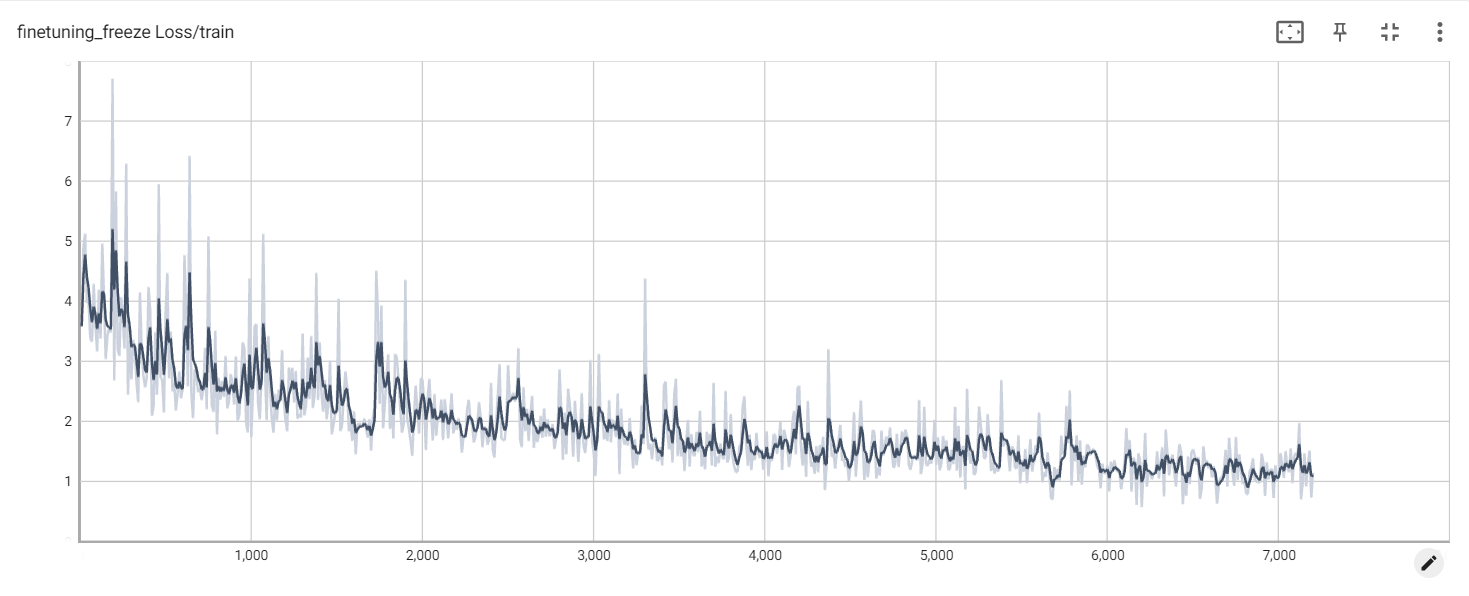
การฝังขาดทุน 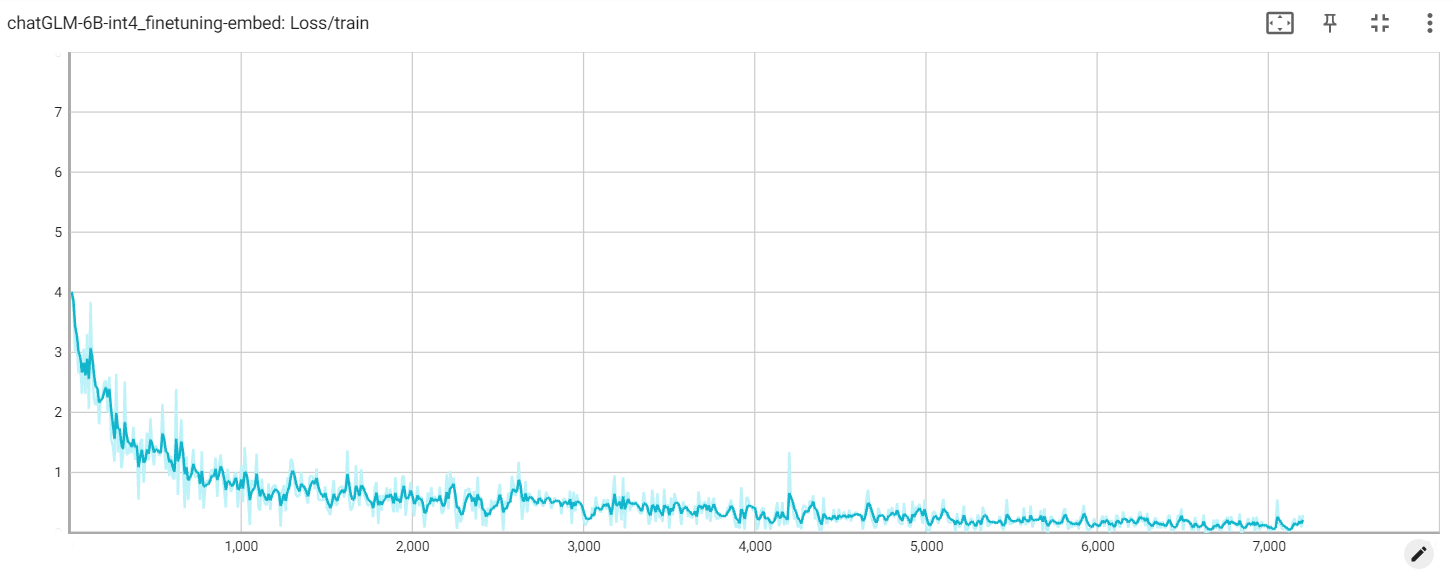
การสูญเสีย PT