dc_tts
1.0.0
我实施了另一个文本到语音模型DC-TTS,该模型基于有效的卷积网络,在有效的卷积网络中引入了具有指导性的注意力。但是,我的目标不只是复制论文。相反,我想了解有关各种声音项目的见解。
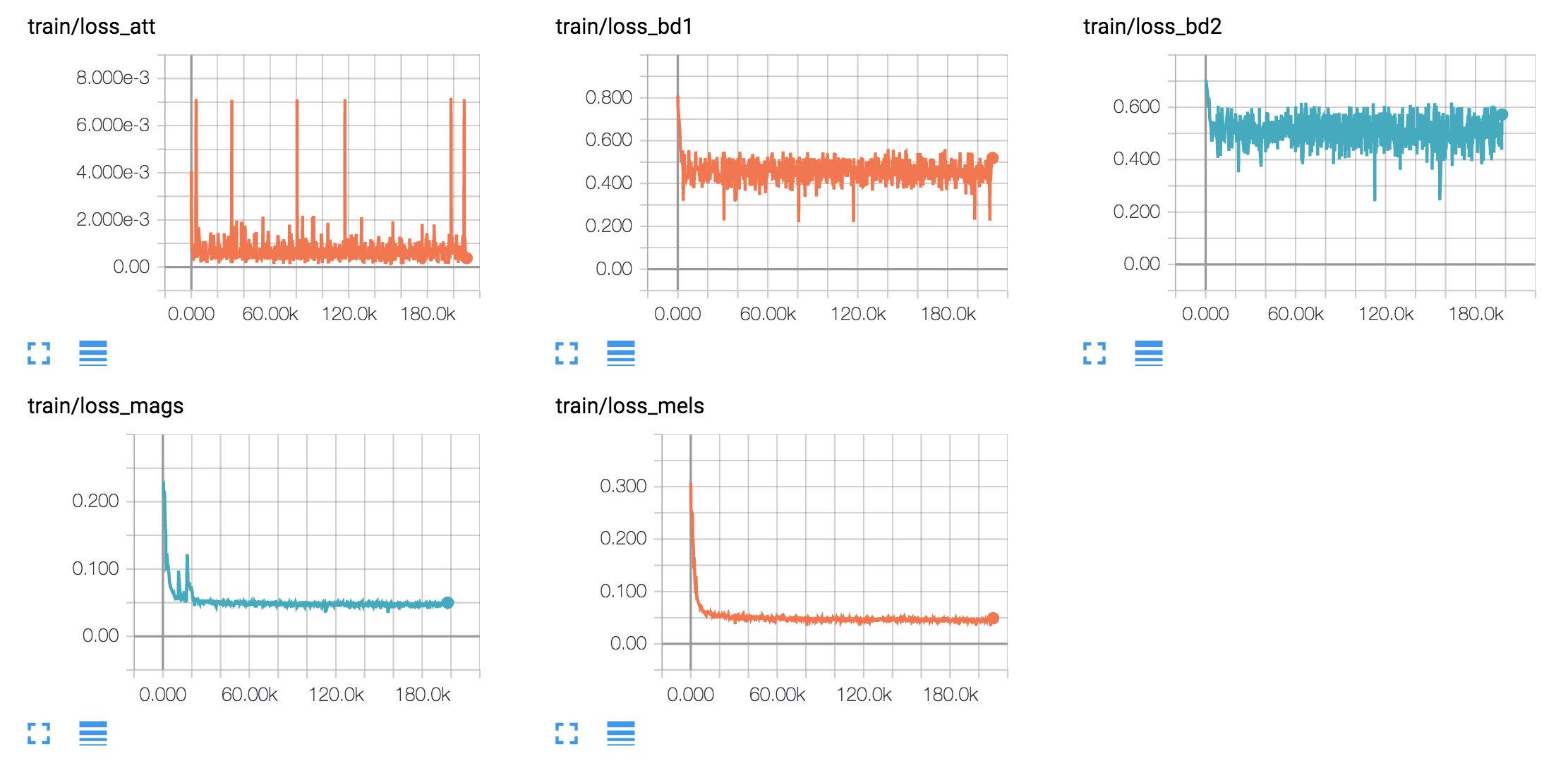
tf.contrib.layers.layer_norm的API已更改)我在四个不同的语音数据集上培训英语模型和韩国模型。
1。LJ语音数据集
2。尼克·奥弗曼(Nick Offerman)的有声读物
3。凯特·温斯莱特的有声读物
4。KSS数据集
LJ语音数据集最近被广泛用作TTS任务中的基准数据集,因为它已公开可用,并且具有24小时合理的质量样本。尼克和凯特的有声读物还用于查看该模型是否可以通过更少的数据(可变语音样本)学习。它们分别为18小时5小时。最后,KSS数据集是韩国单扬声器语音数据集,持续超过12小时。
hyperparams.py中调整超级参数。 (如果您想进行预处理,请设置Prepro true`。python train.py 1用于培训Text2Mel。 (如果设置prepro true,请首先运行python prepro.py)python train.py 2用于训练SSRN。如果您拥有多个GPU卡,则可以同时执行步骤2和3。
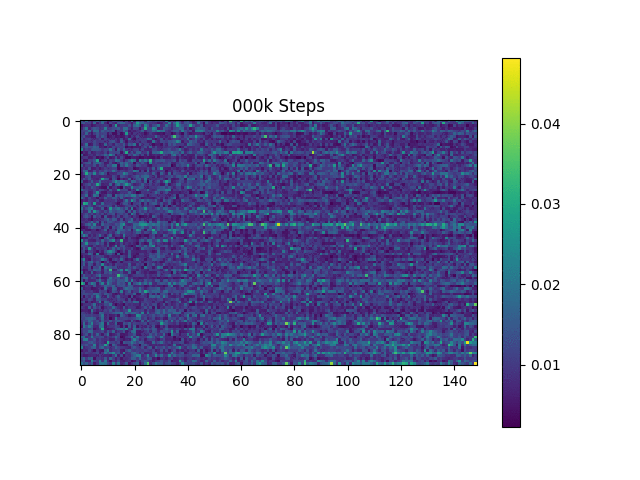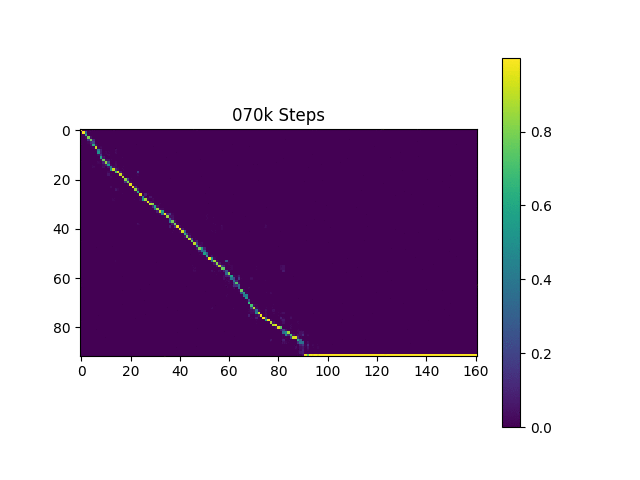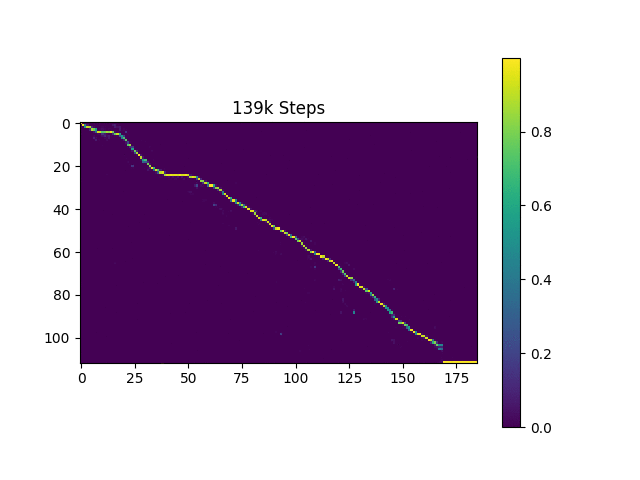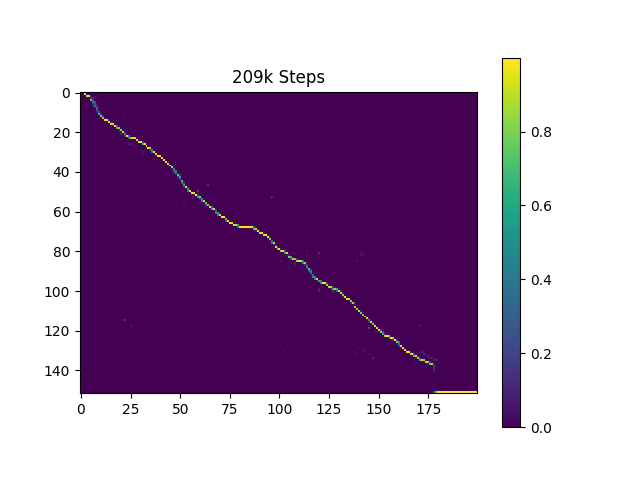
我像原始论文一样,根据哈佛句子来生成语音样本。它已经包含在存储库中。
synthesize.py并检查samples中的文件。 | 数据集 | 样品 |
|---|---|
| LJ | 50k 200k 310k 800k |
| 缺口 | 40k 170k 300k 800k |
| 凯特 | 40k 160k 300k 800k |
| KSS | 400k |
下载此。


