dc_tts
1.0.0
나는주의를 기울인 깊은 컨볼 루션 네트워크를 기반으로 효율적으로 훈련 가능한 텍스트 음성 음성 시스템에 도입 된 또 다른 텍스트 음성 모델 인 DC-TTS를 구현합니다. 그러나 저의 목표는 단지 논문을 복제하는 것이 아닙니다. 오히려 다양한 사운드 프로젝트에 대한 통찰력을 얻고 싶습니다.
tf.contrib.layers.layer_norm 의 API가 1.3 이후로 변경되었습니다)나는 4 개의 다른 음성 데이터 세트에서 영어 모델과 한국 모델을 훈련시킵니다.
1. LJ 음성 데이터 세트
2. Nick Offerman의 오디오 북
3. 케이트 윈슬렛의 오디오 북
4. KSS 데이터 세트
LJ Speech DataSet은 최근 공개적으로 사용할 수 있기 때문에 TTS 작업의 벤치 마크 데이터 세트로 널리 사용되며 24 시간의 합리적인 품질 샘플이 있습니다. Nick 's와 Kate의 오디오 북은 데이터가 적은 데이터, 가변 음성 샘플로도 배울 수 있는지 확인하는 데 추가로 사용됩니다. 그들은 각각 18 시간 5 시간 길이입니다. 마지막으로 KSS 데이터 세트는 12 시간 이상 지속되는 한국의 단일 스피커 음성 데이터 세트입니다.
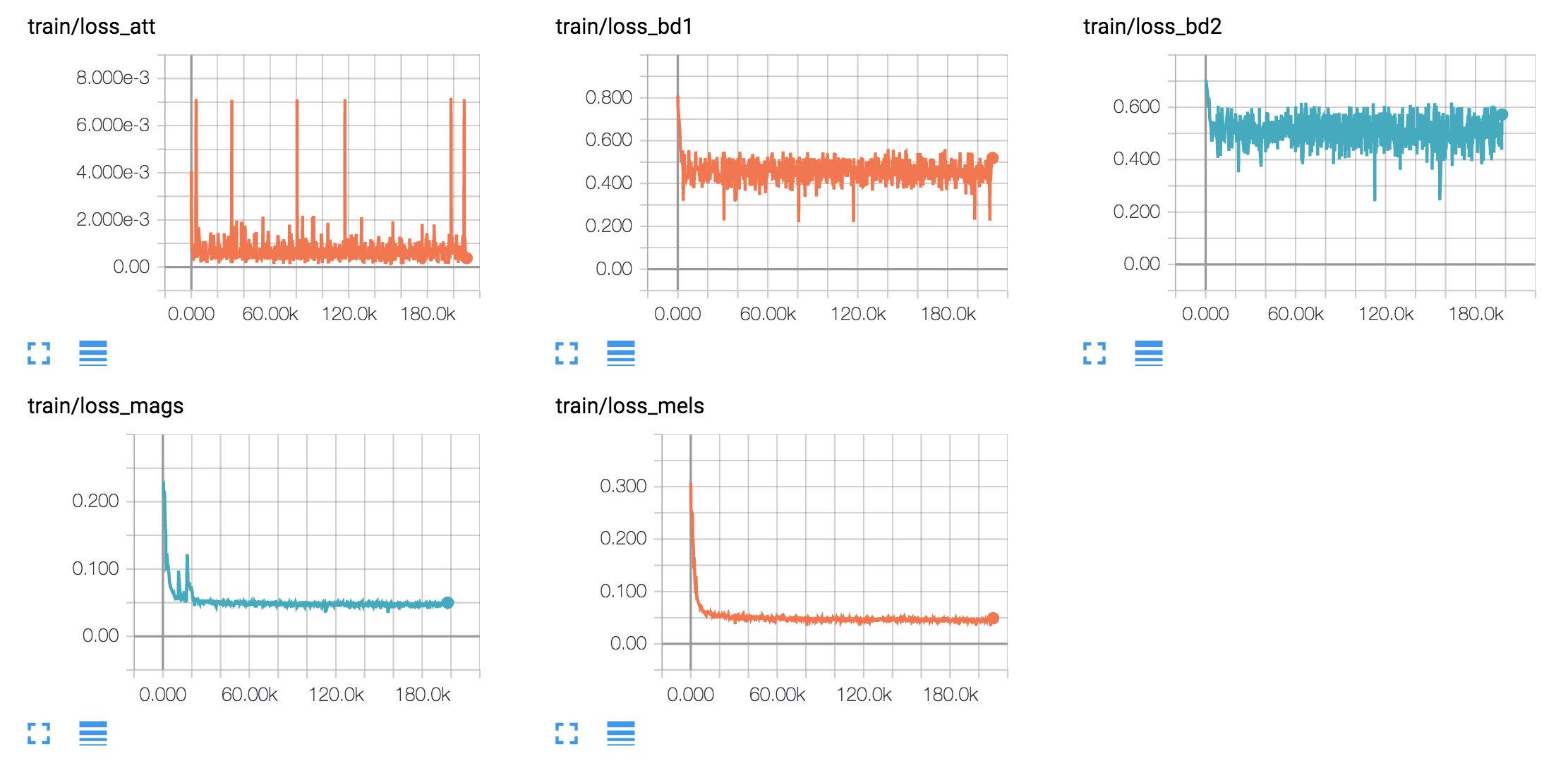
hyperparams.py 에서 하이퍼 파라미터를 조정하십시오. (사전 처리를하고 싶다면 Prepro True`를 설정하십시오.python train.py 1 실행하십시오. (Prepro True를 설정하면 Python Prepro.py를 먼저 실행하십시오)python train.py 2 실행하십시오.둘 이상의 GPU 카드가있는 경우 2 단계와 3 단계를 동시에 수행 할 수 있습니다.
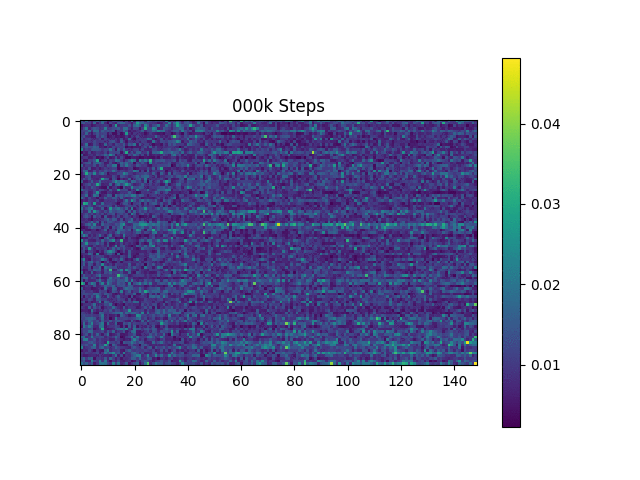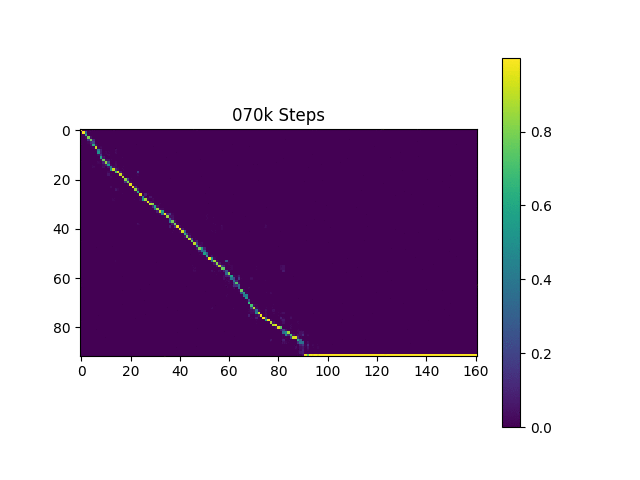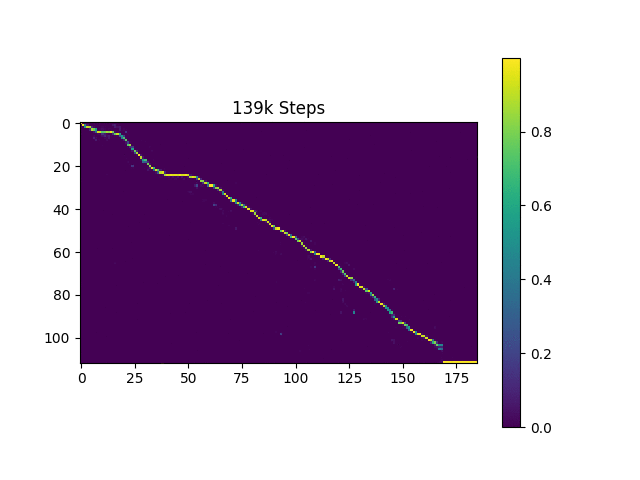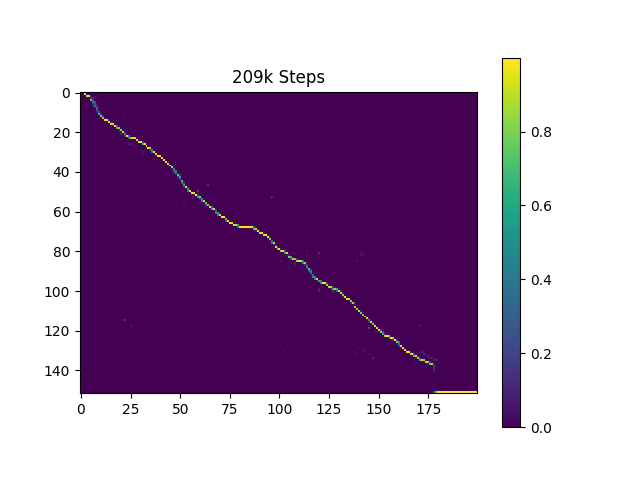
원래 논문과 마찬가지로 하버드 문장을 기반으로 한 언어 샘플을 생성합니다. 이미 리포에 포함되어 있습니다.
synthesize.py 실행하고 samples 에서 파일을 확인하십시오. | 데이터 세트 | 샘플 |
|---|---|
| LJ | 50K 200K 310K 800K |
| 건강 상태 | 40K 170K 300K 800K |
| 케이트 | 40K 160K 300K 800K |
| KSS | 400K |
이것을 다운로드하십시오.


