dc_tts
1.0.0
Implemento otro modelo de texto a voz, DC-TTS, introducido en un sistema de texto a voz de eficiencia eficiente basado en redes convolucionales profundas con atención guiada. Mi objetivo, sin embargo, no es solo replicar el papel. Más bien, me gustaría obtener información sobre varios proyectos de sonido.
tf.contrib.layers.layer_norm ha cambiado desde 1.3)Entreno modelos ingleses y un modelo coreano en cuatro conjuntos de datos de voz diferentes.
1. LJ de conjunto de datos de discurso
2. Audiolibros de Nick Offerman
3. Audiolibro de Kate Winslet
4. Conjunto de datos KSS
El conjunto de datos de discurso LJ se usa recientemente como un conjunto de datos de referencia en la tarea TTS porque está disponible públicamente, y tiene 24 horas de muestras de calidad razonables. Los audiolibros de Nick y Kate también se usan para ver si el modelo puede aprender incluso con menos datos, muestras de voz variables. Tienen 18 horas y 5 horas, respectivamente. Finalmente, el conjunto de datos KSS es un conjunto de datos de discurso de un solo hablante coreano que dura más de 12 horas.
hyperparams.py . (Si desea realizar el preprocesamiento, configure Prepro True`.python train.py 1 para Text2Mel de entrenamiento. (Si configura Prepro True, ejecute Python Prepro.py primero)python train.py 2 para entrenamiento SSRN.Puede hacer el paso 2 y 3 al mismo tiempo, si tiene más de una tarjeta GPU.
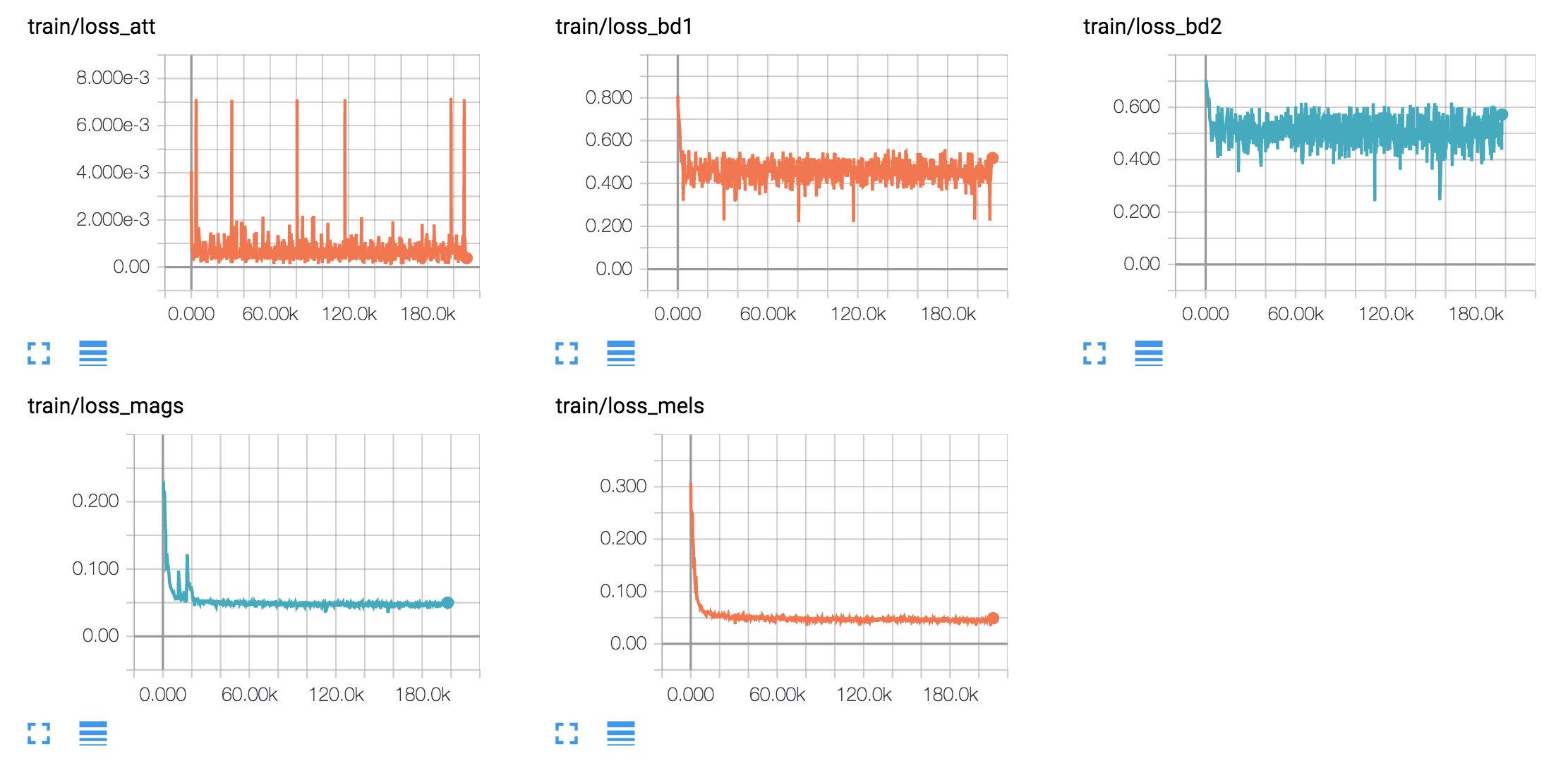
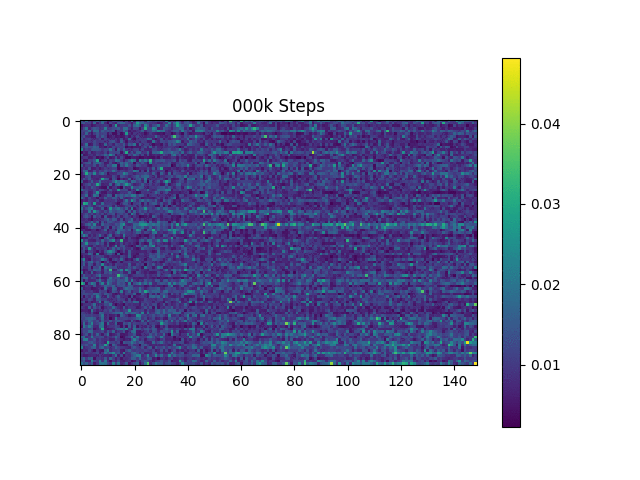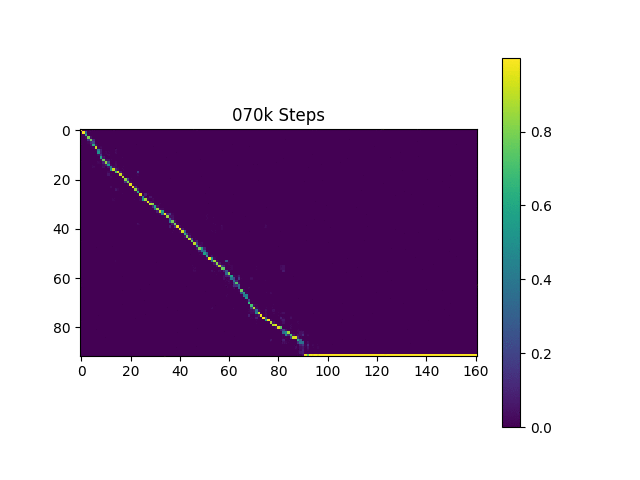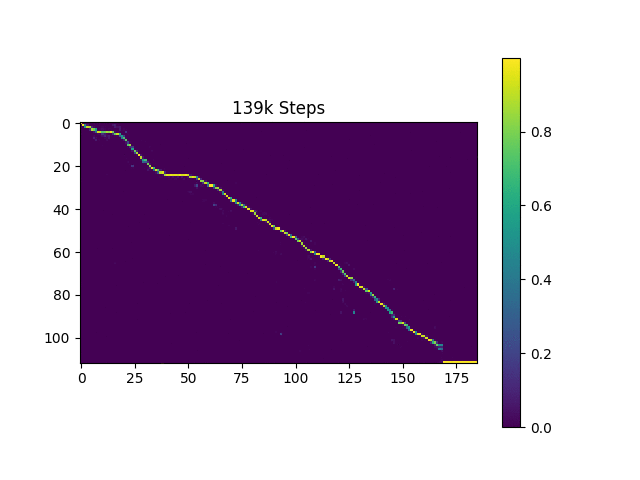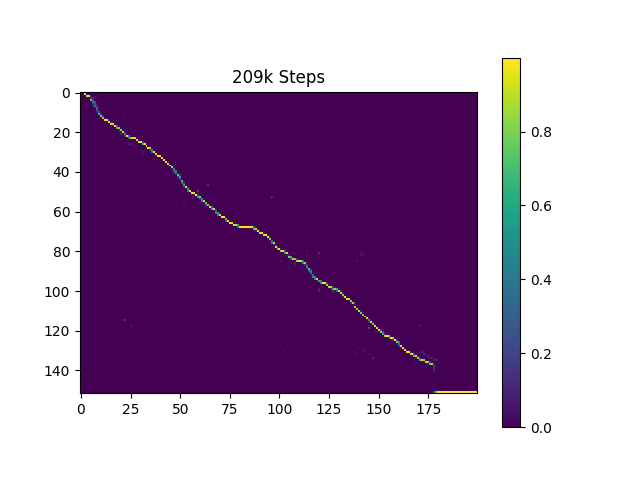
Generaron muestras de habla basadas en oraciones de Harvard como lo hace el documento original. Ya está incluido en el repositorio.
synthesize.py y verifique los archivos en samples . | Conjunto de datos | Muestras |
|---|---|
| Lj | 50k 200k 310k 800k |
| Mella | 40K 170K 300K 800K |
| Kate | 40k 160k 300k 800k |
| KSS | 400k |
Descargue esto.


