dc_tts
1.0.0
Я внедряю еще одну модель текста в речь, DC-TTS, представленная в эффективной обучаемой системе текста в речь, основанной на глубоких сверточных сетях с руководством. Моя цель, однако, - не просто копирование бумаги. Скорее, я хотел бы получить представление о различных звуковых проектах.
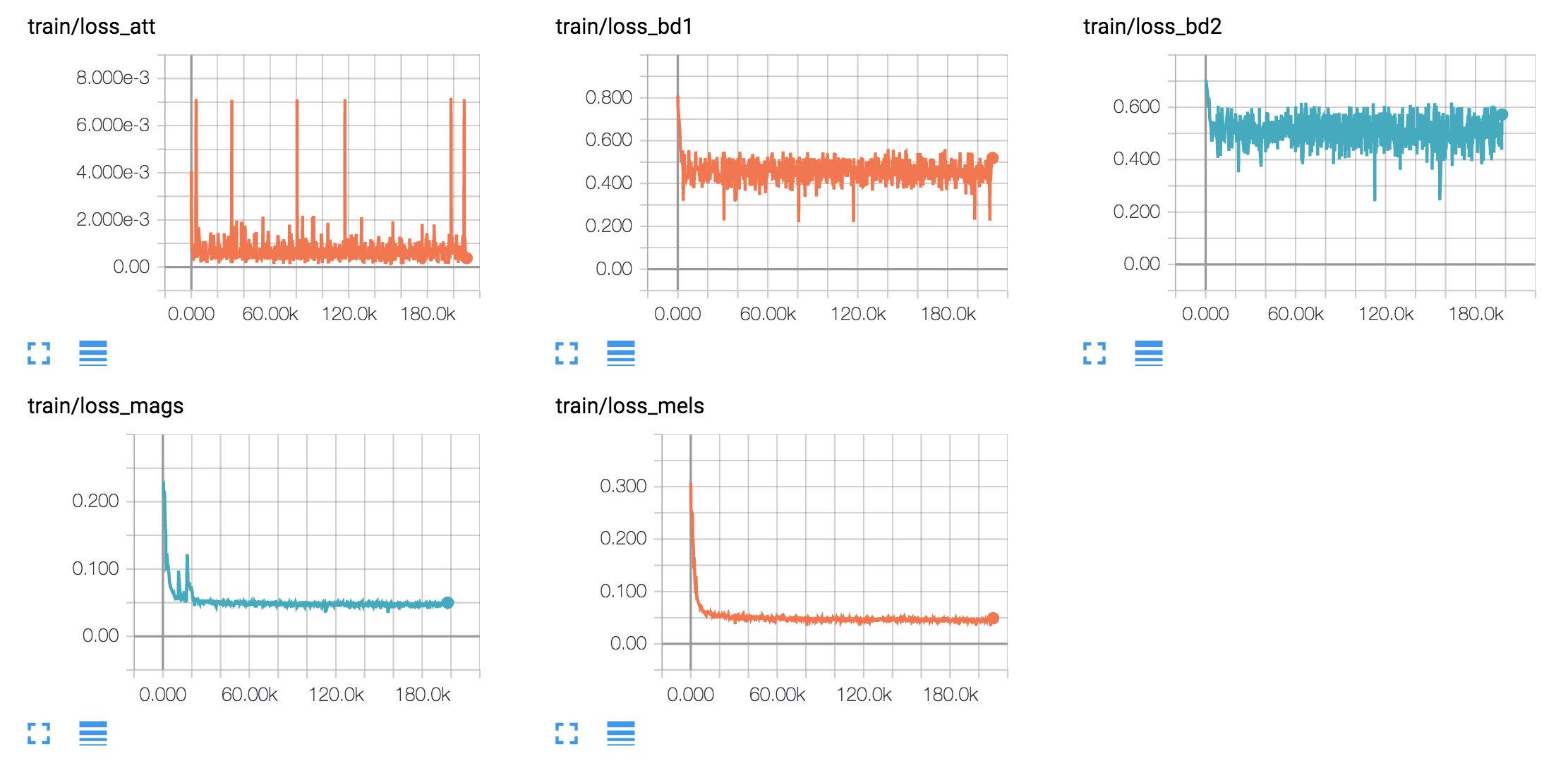
tf.contrib.layers.layer_norm изменился с 1.3)Я обучаю английские модели и корейскую модель на четырех различных наборах данных.
1. Набор данных речи LJ
2. Аудиокниги Ника Оффермана
3. Аудиокнига Кейт Уинслет
4. Набор данных KSS
Набор данных речи LJ недавно широко используется в качестве контрольного набора данных в задаче TTS, поскольку он общедоступен, и у него 24 часа разумных качественных образцов. Аудиокниги Ника и Кейт дополнительно используются, чтобы увидеть, сможет ли модель изучать даже с меньшими данными, переменными речевыми образцами. Они 18 часов и 5 часов, соответственно. Наконец, набор данных KSS - это корейский набор речевой данных для одного динамика, который длится более 12 часов.
hyperparams.py . (Если вы хотите сделать предварительную обработку, установите Prefro True '.python train.py 1 для обучения Text2mel. (Если вы установите Prefro True, сначала запустите Python prefro.py)python train.py 2 для обучения SSRN.Вы можете сделать шаг 2 и 3 одновременно, если у вас есть более одной карты графического процессора.
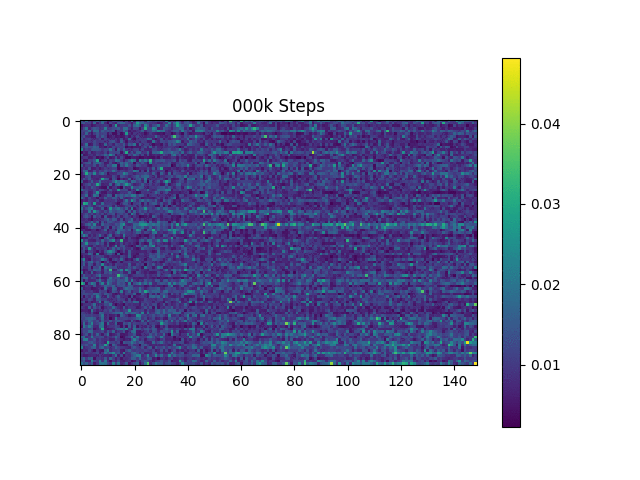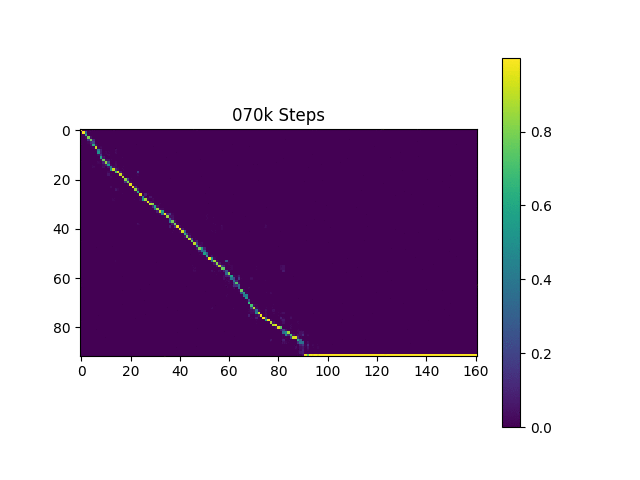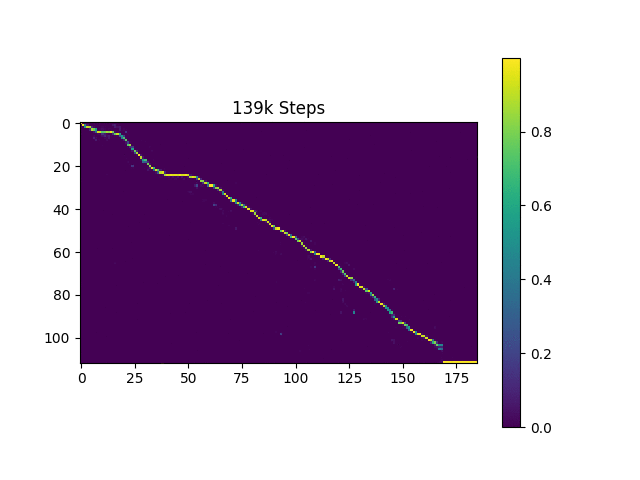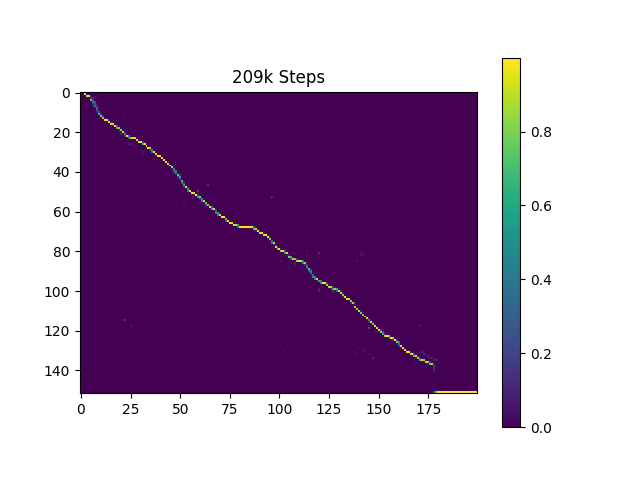
Я генерирую выборочные выборы на основе Гарвардских предложений, как это делает оригинальная статья. Он уже включен в репо.
synthesize.py и проверьте файлы в samples . | Набор данных | Образцы |
|---|---|
| LJ | 50K 200K 310K 800K |
| Ник | 40K 170K 300K 800K |
| Кейт | 40K 160K 300K 800K |
| KSS | 400K |
Скачать это.


