dc_tts
1.0.0
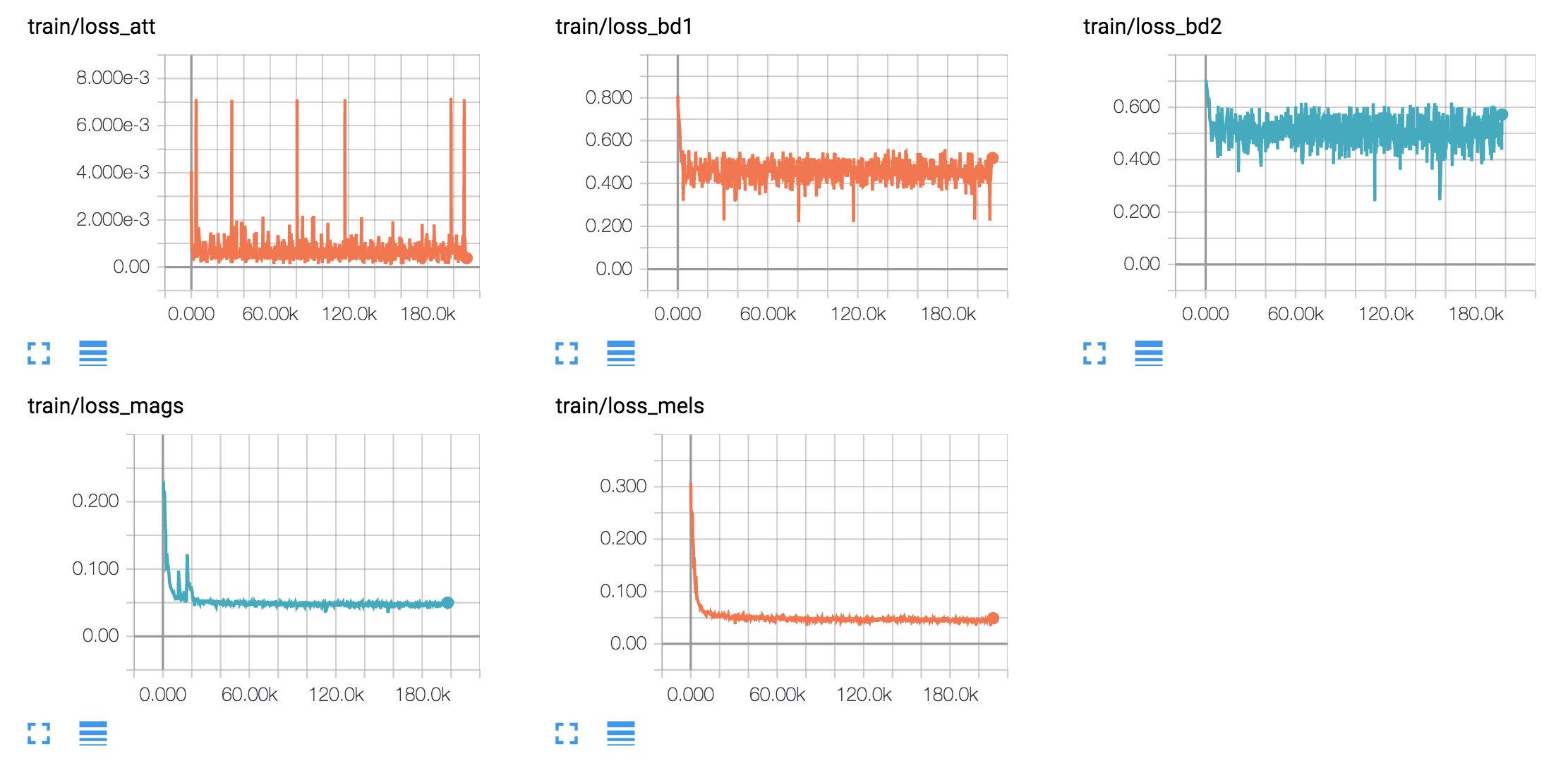
Ich implementiere ein weiteres Text-zu-Sprache-Modell, DC-TTS, das in effizient trainierbarem Text-zu-Sprache-System auf Basis von tiefen Faltungsnetzwerken mit geführter Aufmerksamkeit eingeführt wurde. Mein Ziel ist es jedoch nicht nur, das Papier zu replizieren. Vielmehr möchte ich Einblicke in verschiedene Klangprojekte erhalten.
tf.contrib.layers.layer_norm seit 1.3 geändert hat)Ich trainiere englische Modelle und ein koreanisches Modell für vier verschiedene Sprachdatensätze.
1. LJ Sprachdatensatz
2. Hörbücher von Nick Offermans Hörbüchern
3. Hörbuch von Kate Winslets
4. KSS -Datensatz
LJ Sprachdatensatz wird in letzter Zeit häufig als Benchmark -Datensatz in der TTS -Aufgabe verwendet, da es öffentlich verfügbar ist und 24 Stunden angemessener Qualitätsmuster enthält. Nick's und Kates Hörbücher werden zusätzlich verwendet, um festzustellen, ob das Modell auch mit weniger Daten und variablen Sprachproben lernen kann. Sie sind 18 Stunden bzw. 5 Stunden lang. Schließlich ist KSS -Datensatz ein koreanischer Sprachdatensatz für Single -Lautsprecher, der mehr als 12 Stunden dauert.
hyperparams.py . (Wenn Sie die Vorverarbeitung durchführen möchten, setzen Sie Prepro true`.python train.py 1 für Training Text2Mel. (Wenn Sie Prepro True einstellen, führen Sie Python prepro.py zuerst aus) aus.python train.py 2 für das Training ssrn.Sie können Schritt 2 und 3 gleichzeitig ausführen, wenn Sie mehr als eine GPU -Karte haben.
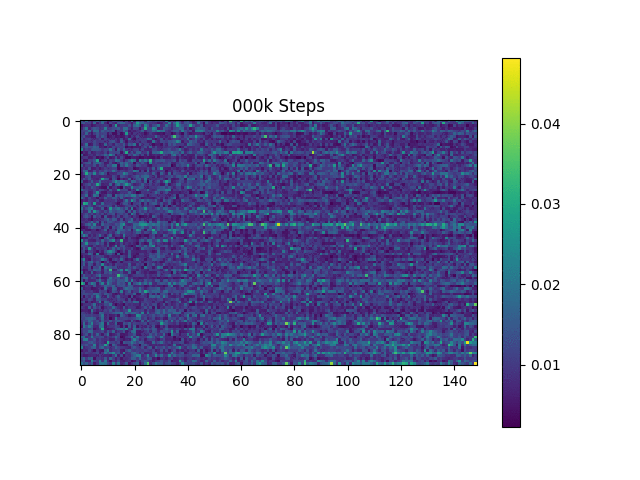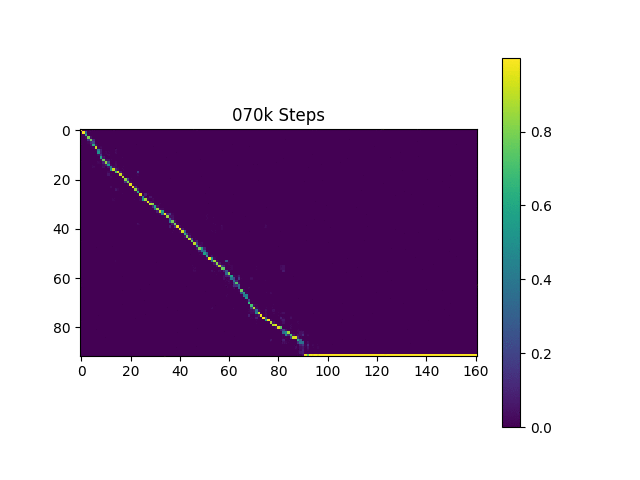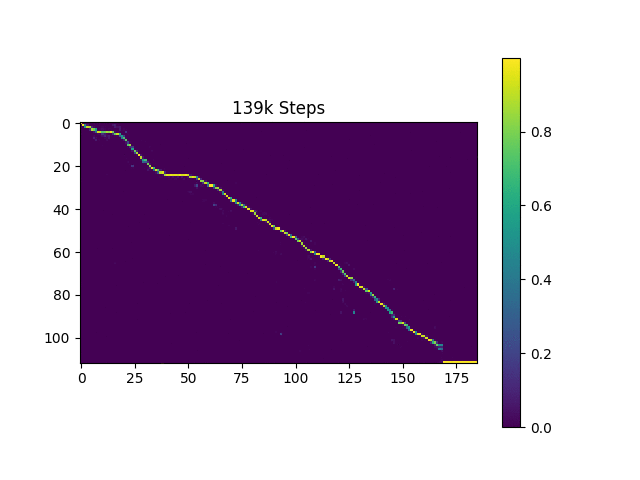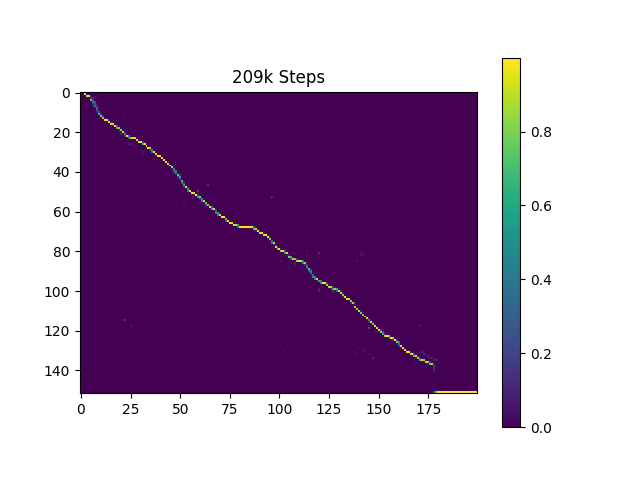
Ich generiere Sprachproben, die auf Harvard -Sätzen basieren, wie es das Originalpapier tut. Es ist bereits im Repo enthalten.
synthesize.py aus und überprüfen Sie die Dateien in samples . | Datensatz | Proben |
|---|---|
| Lj | 50k 200k 310k 800k |
| Nick | 40k 170k 300k 800k |
| Kate | 40k 160k 300k 800k |
| KSS | 400k |
Laden Sie dies herunter.


