dc_tts
1.0.0
Saya mengimplementasikan model teks-ke-ucapan lain, DC-TTS, diperkenalkan dalam sistem teks-ke-speech yang dapat dilatih secara efisien berdasarkan jaringan konvolusional yang dalam dengan perhatian yang dipandu. Namun, tujuan saya bukan hanya meniru kertas. Sebaliknya, saya ingin mendapatkan wawasan tentang berbagai proyek suara.
tf.contrib.layers.layer_norm telah berubah sejak 1.3)Saya melatih model bahasa Inggris dan model Korea pada empat dataset pidato yang berbeda.
1. Dataset Pidato LJ
2. Buku audio Nick Offerman
3. Audiobook Kate Winslet
4. Dataset KSS
Dataset LJ Speech baru -baru ini banyak digunakan sebagai dataset tolok ukur dalam tugas TTS karena tersedia untuk umum, dan memiliki 24 jam sampel kualitas yang wajar. Buku audio Nick's dan Kate juga digunakan untuk melihat apakah model dapat belajar bahkan dengan lebih sedikit data, sampel ucapan variabel. Mereka masing -masing 18 jam dan panjangnya 5 jam. Akhirnya, KSS Dataset adalah dataset pidato pembicara tunggal Korea yang berlangsung lebih dari 12 jam.
hyperparams.py . (Jika Anda ingin melakukan preprocessing, atur Prepro True`.python train.py 1 untuk pelatihan Text2mel. (Jika Anda mengatur prepro true, jalankan python prepro.py pertama)python train.py 2 untuk pelatihan ssrn.Anda dapat melakukan langkah 2 dan 3 secara bersamaan, jika Anda memiliki lebih dari satu kartu GPU.
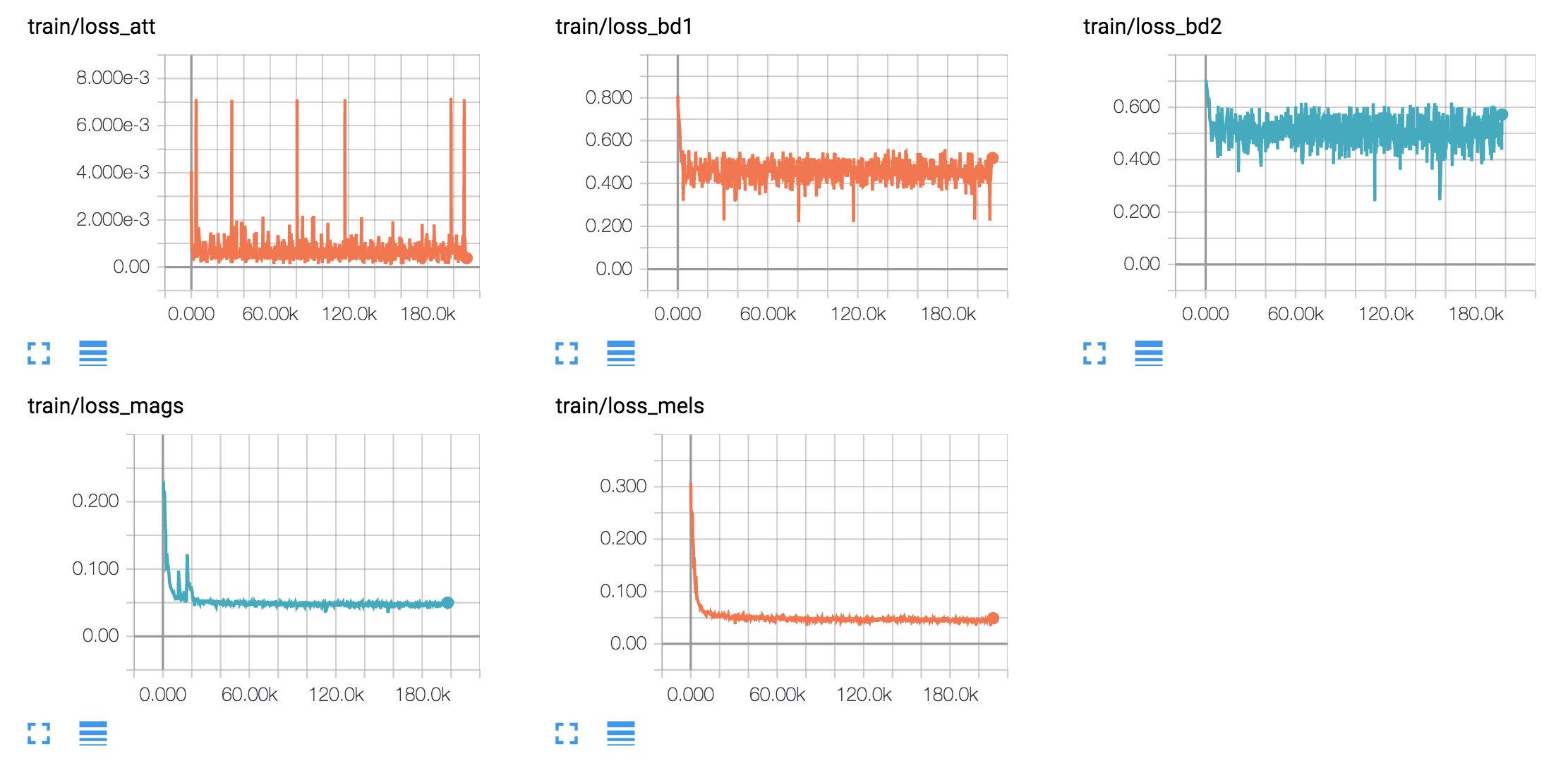
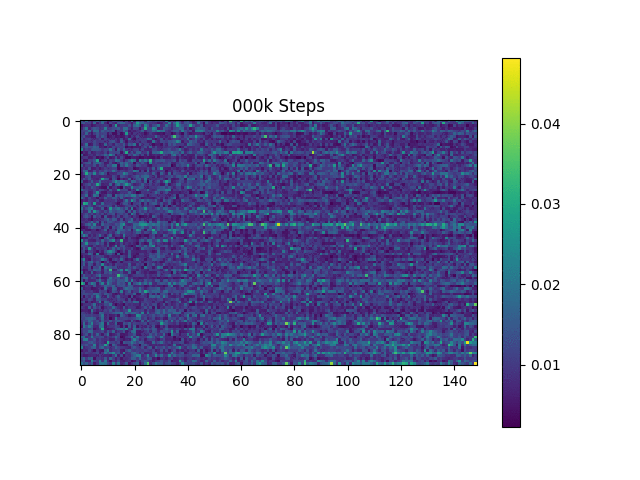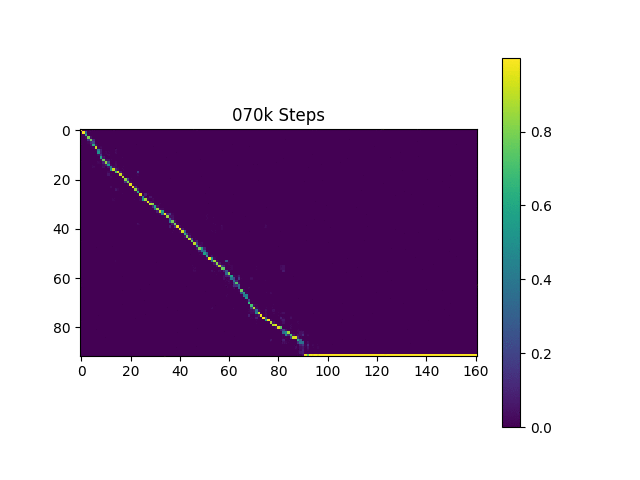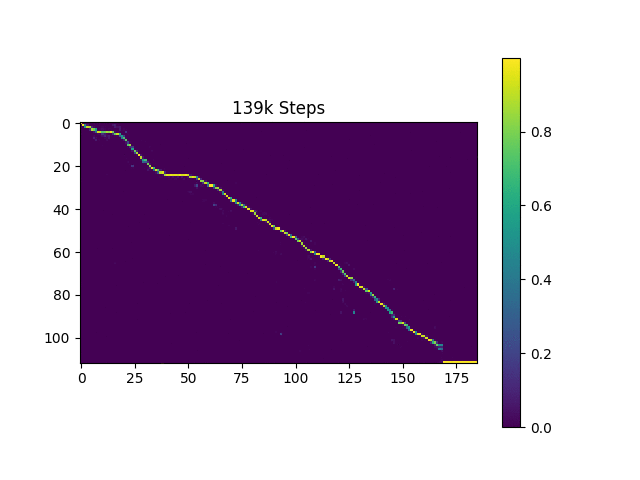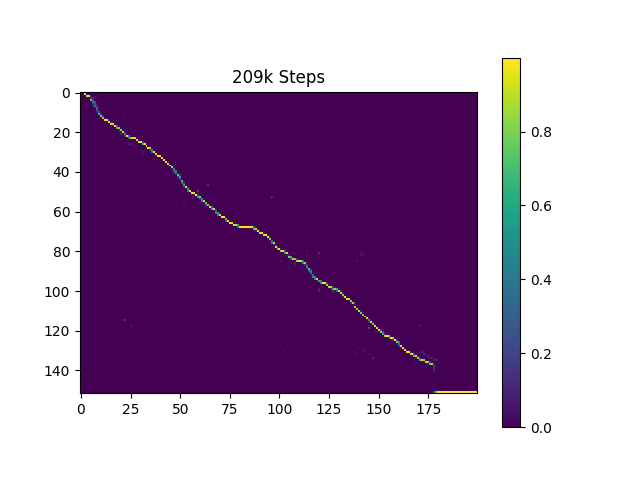
Saya menghasilkan sampel ucapan berdasarkan kalimat Harvard seperti yang dilakukan kertas asli. Ini sudah termasuk dalam repo.
synthesize.py dan periksa file dalam samples . | Dataset | Sampel |
|---|---|
| LJ | 50K 200K 310K 800K |
| Nick | 40K 170K 300K 800K |
| Kate | 40K 160K 300K 800K |
| KSS | 400K |
Unduh ini.


