dc_tts
1.0.0
أقوم بتطبيق نموذج آخر من النص إلى كلام ، DC-TTS ، الذي تم تقديمه في نظام النص إلى الكلام القابل للتدريب بكفاءة استنادًا إلى شبكات تلافيفية عميقة مع اهتمام موجه. هدفي ، ومع ذلك ، ليس فقط تكرار الورقة. بدلاً من ذلك ، أود الحصول على رؤى حول مشاريع الصوت المختلفة.
tf.contrib.layers.layer_norm قد تغيرت منذ 1.3)أقوم بتدريب النماذج الإنجليزية ونموذج كوري على أربع مجموعات بيانات الكلام المختلفة.
1. مجموعة بيانات الكلام LJ
2. كتب نيك أوفيمان المسموعة
3.
4. KSS Dataset
تستخدم مجموعة بيانات الكلام LJ مؤخرًا كمجموعة بيانات قياسية في مهمة TTS لأنها متوفرة للجمهور ، ولديها 24 ساعة من عينات الجودة المعقولة. بالإضافة إلى ذلك ، يتم استخدام الكتب المسموعة المسموعة في Nick's و Kate لمعرفة ما إذا كان يمكن أن يتعلم النموذج حتى مع بيانات الكلام المتغيرة أقل. هم 18 ساعة و 5 ساعات ، على التوالي. أخيرًا ، KSS Dataset هي مجموعة بيانات خطاب الكلمة الكورية التي تدوم أكثر من 12 ساعة.
hyperparams.py . (إذا كنت ترغب في القيام بالمعالجة المسبقة ، فقم بتعيين prepro true`.python train.py 1 للتدريب Text2mel. (إذا قمت بتعيين prepro true ، قم بتشغيل python prepro.py أولاً)python train.py 2 لتدريب SSRN.يمكنك القيام بخطوة 2 و 3 في نفس الوقت ، إذا كان لديك أكثر من بطاقة GPU واحدة.
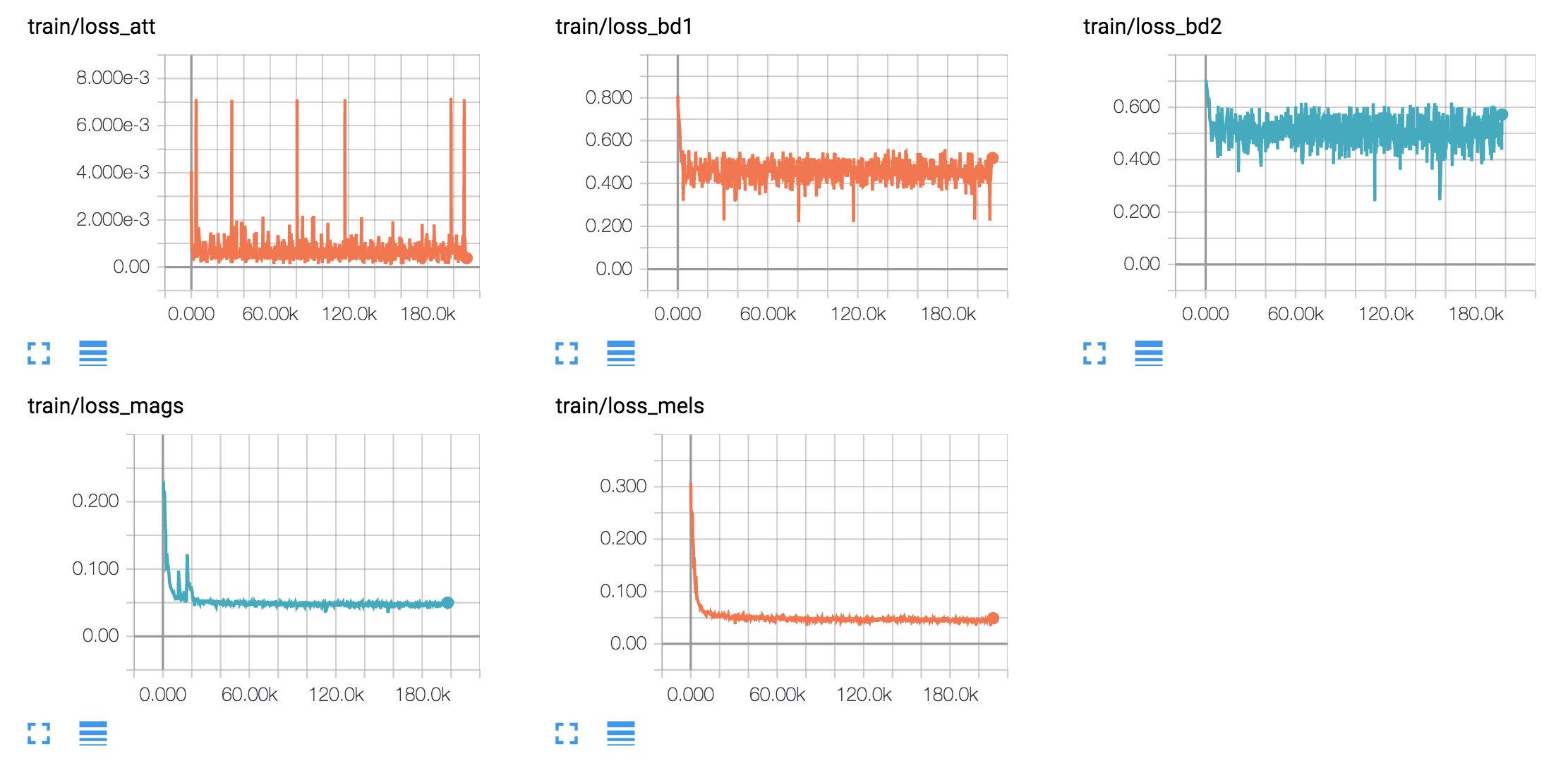
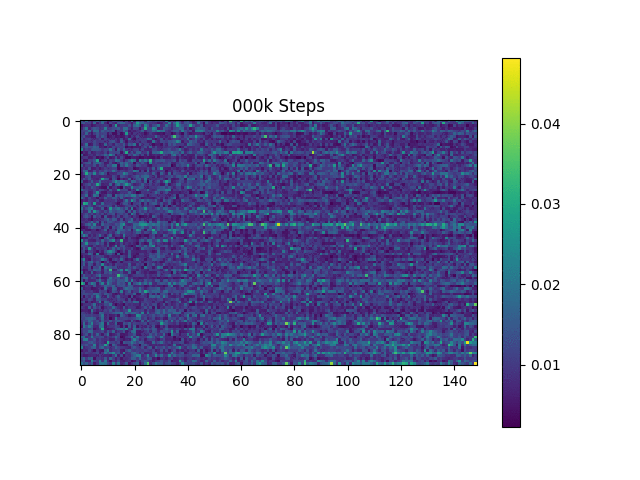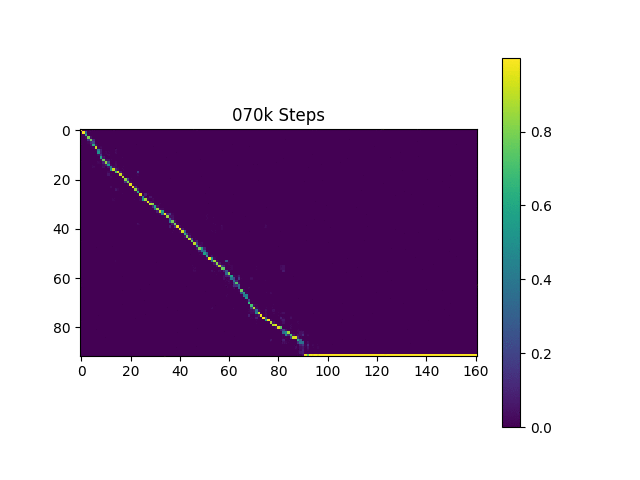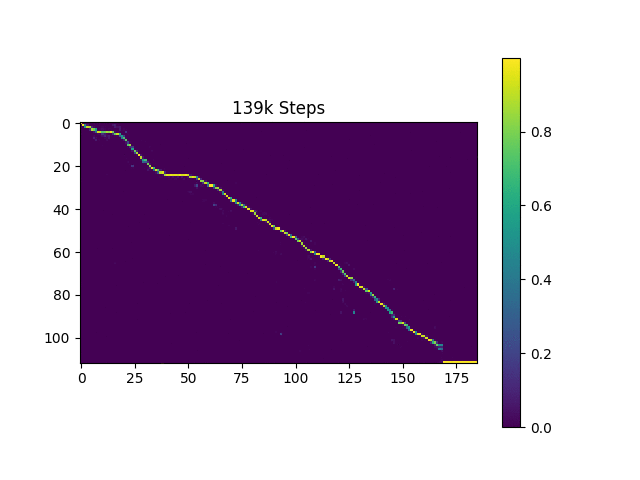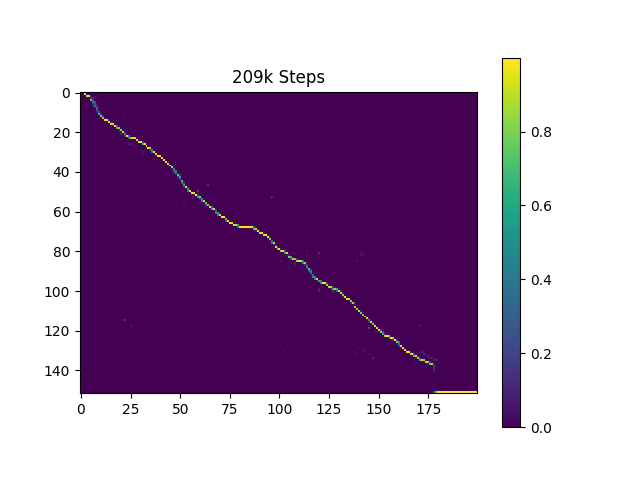
أقوم بإنشاء عينات الكلام على أساس جمل هارفارد كما تفعل الورقة الأصلية. تم تضمينه بالفعل في الريبو.
synthesize.py وتحقق من الملفات في samples . | مجموعة البيانات | عينات |
|---|---|
| LJ | 50K 200K 310K 800K |
| نيك | 40K 170K 300K 800K |
| كيت | 40K 160K 300K 800K |
| KSS | 400 كيلو |
قم بتنزيل هذا.


