dc_tts
1.0.0
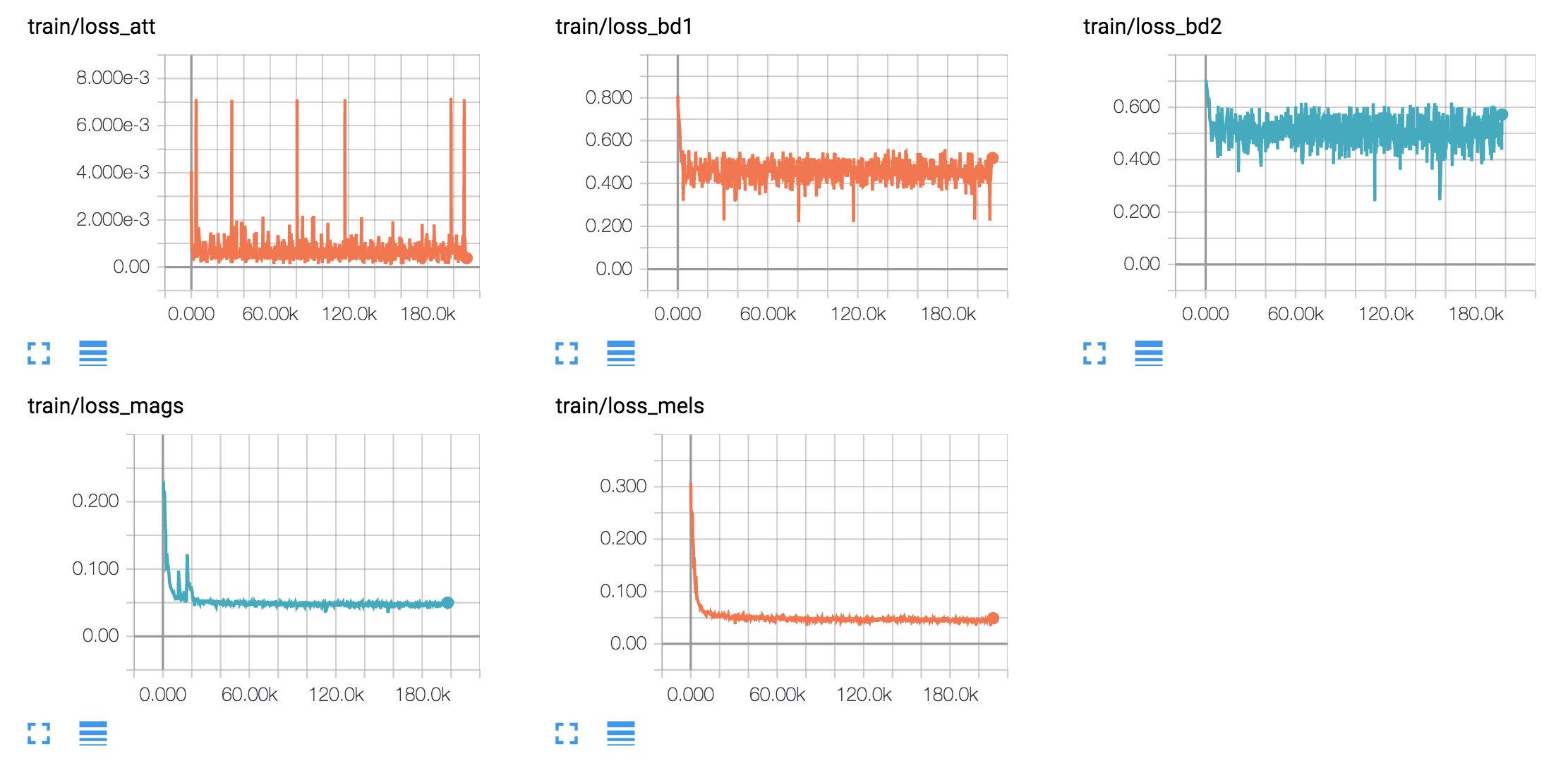
私は、誘導された注意を払った深い畳み込みネットワークに基づいて、効率的にトレーニング可能なテキストからスピーチへのスピーチシステムで導入された、さらに別のテキストからスピーチへのモデルであるDC-TTSを実装しています。しかし、私の目標は、論文を複製するだけではありません。むしろ、さまざまなサウンドプロジェクトについての洞察を得たいと思います。
tf.contrib.layers.layer_normのAPIが1.3以降変更されていることに注意してください)4つの異なる音声データセットで英語モデルと韓国モデルをトレーニングします。
1。LJ音声データセット
2。ニック・オファーマンのオーディオブック
3。ケイトウィンスレットのオーディオブック
4。KSSデータセット
LJ Speech Datasetは最近、TTSタスクのベンチマークデータセットとして広く使用されており、公開されており、24時間の合理的な品質サンプルがあります。 Nick'sとKateのオーディオブックは、モデルがより少ないデータ、可変音声サンプルでも学習できるかどうかを確認するためにさらに使用されます。それらはそれぞれ18時間5時間です。最後に、KSSデータセットは、12時間以上続く韓国の単一スピーカー音声データセットです。
hyperparams.pyパラメーターを調整します。 (前処理をしたい場合は、pretro true `を設定します。python train.py 1実行します。 (Pretro Trueを設定した場合は、Python Prepro.pyを最初に実行します)python train.py 2実行します。複数のGPUカードがある場合は、ステップ2と3を同時に実行できます。
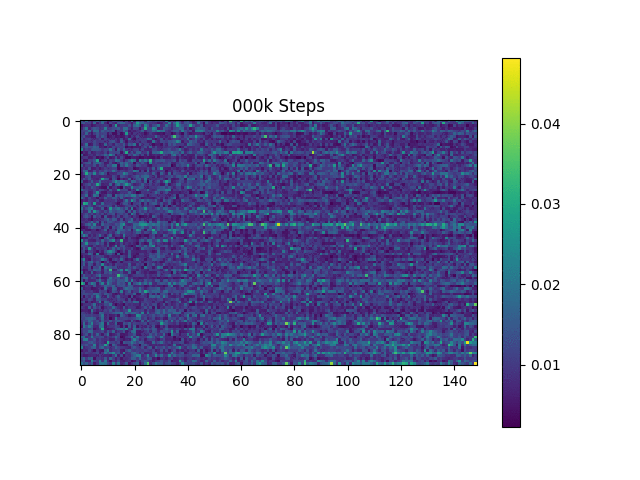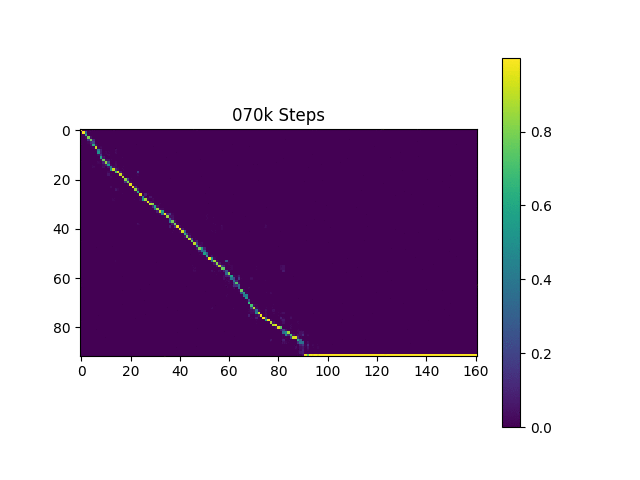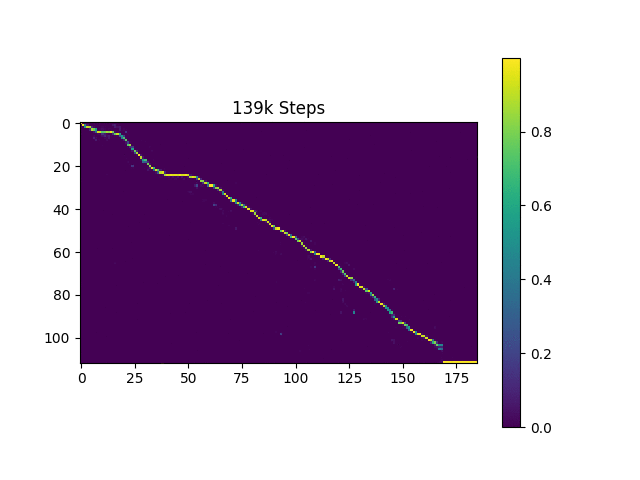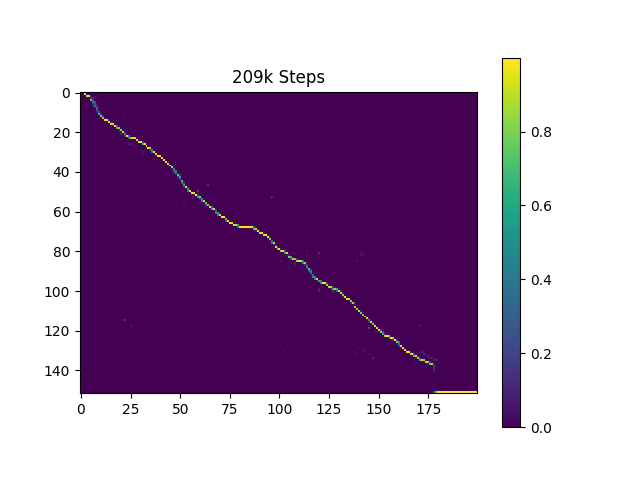
元の論文と同じように、ハーバードの文に基づいて音声サンプルを生成します。すでにリポジトリに含まれています。
synthesize.pyを実行し、 samplesでファイルを確認します。 | データセット | サンプル |
|---|---|
| LJ | 50K 200K 310K 800K |
| ニック | 40K 170K 300K 800K |
| ケイト | 40K 160K 300K 800K |
| KSS | 400k |
これをダウンロードしてください。


