dc_tts
1.0.0
Implementei outro modelo de texto para fala, o DC-TTS, introduzido em um sistema de texto para fala com eficientemente treinável, com base em redes convolucionais profundas com atenção guiada. Meu objetivo, no entanto, não é apenas replicar o papel. Em vez disso, gostaria de obter idéias sobre vários projetos de som.
tf.contrib.layers.layer_norm mudou desde 1.3)Treino modelos em inglês e um modelo coreano em quatro conjuntos de dados de fala diferentes.
1. LJ DataSet de fala
2. Audiobooks do Nick Offerman
3. Audiobook de Kate Winslet
4. DATASET KSS
O conjunto de dados de fala do LJ é recentemente amplamente utilizado como um conjunto de dados de referência na tarefa TTS porque está disponível ao público e possui 24 horas de amostras de qualidade razoável. Os audiolivros de Nick e Kate também são usados para ver se o modelo pode aprender mesmo com menos dados, amostras de fala variáveis. Eles têm 18 horas e 5 horas, respectivamente. Finalmente, o KSS DataSet é um conjunto de dados de discurso de falante único coreano que dura mais de 12 horas.
hyperparams.py . (Se você quiser fazer pré -processamento, defina o pré -prove true`.python train.py 1 para treinamento text2mel. (Se você definir o Prepro true, execute o python prepro.py primeiro)python train.py 2 para o treinamento de ssrn.Você pode fazer as etapas 2 e 3 ao mesmo tempo, se tiver mais de um cartão GPU.
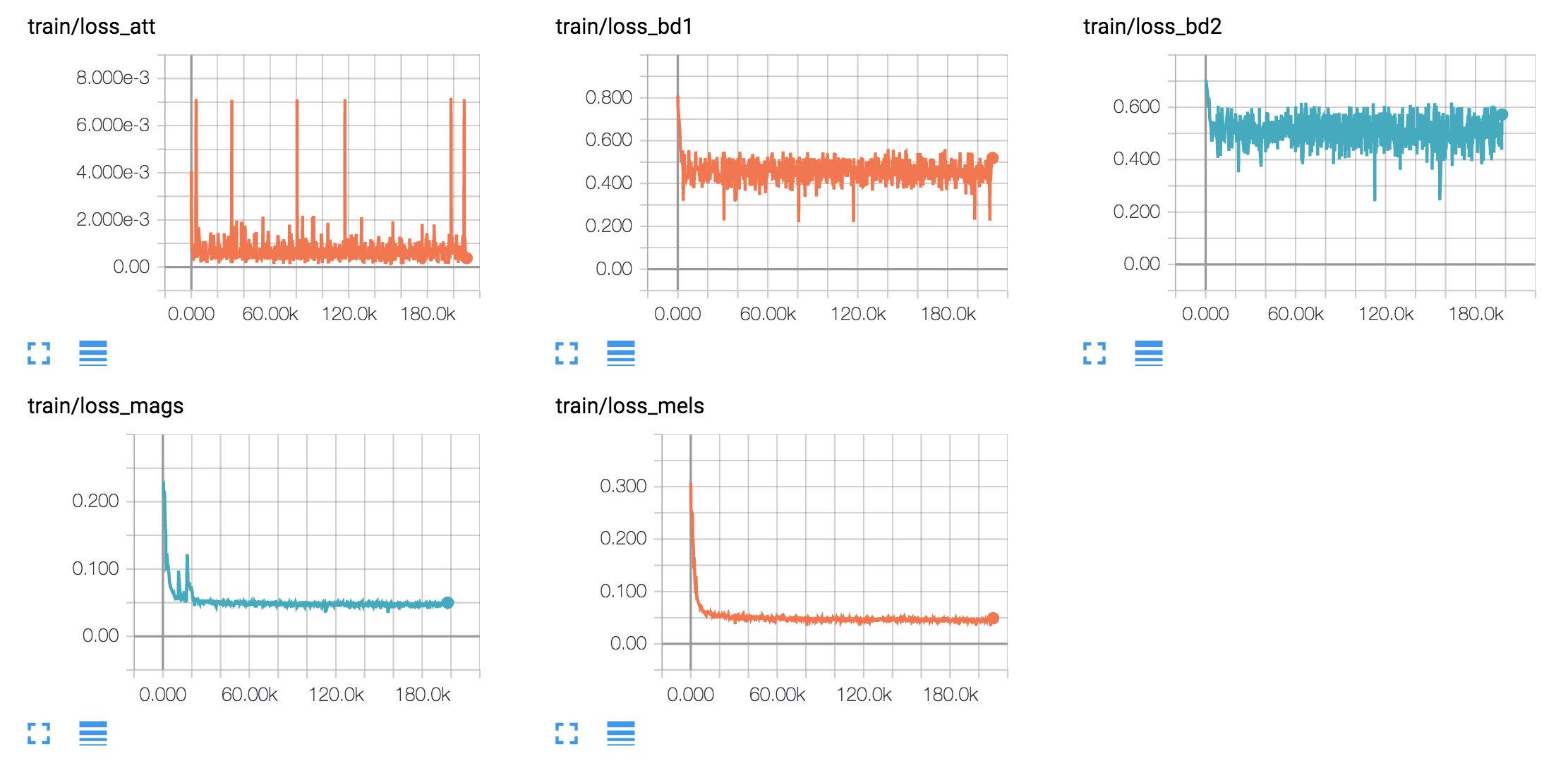
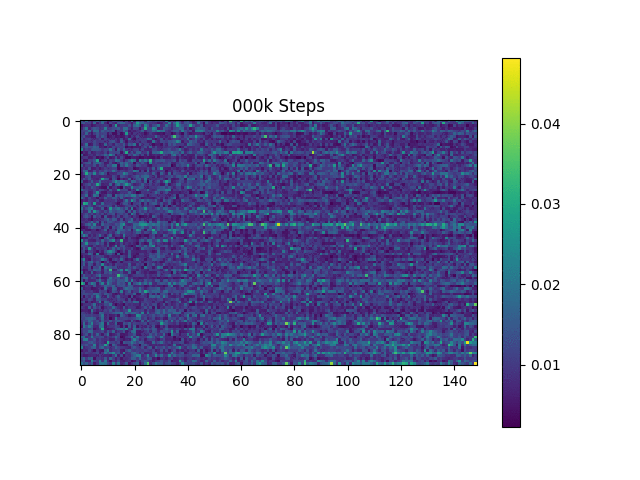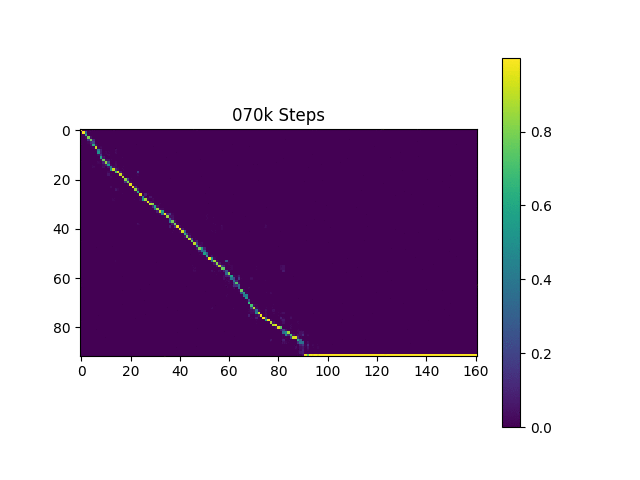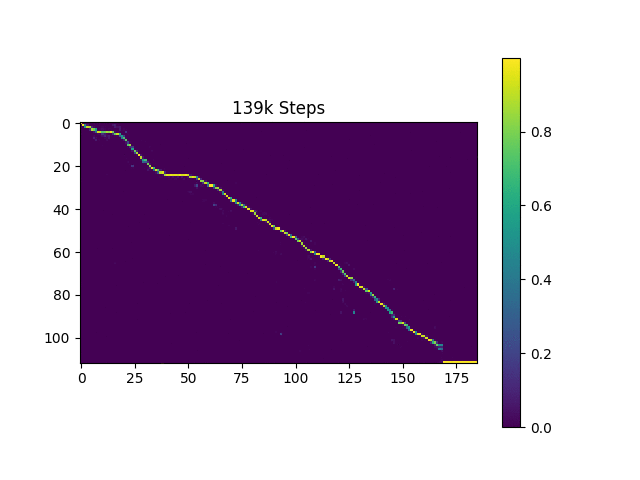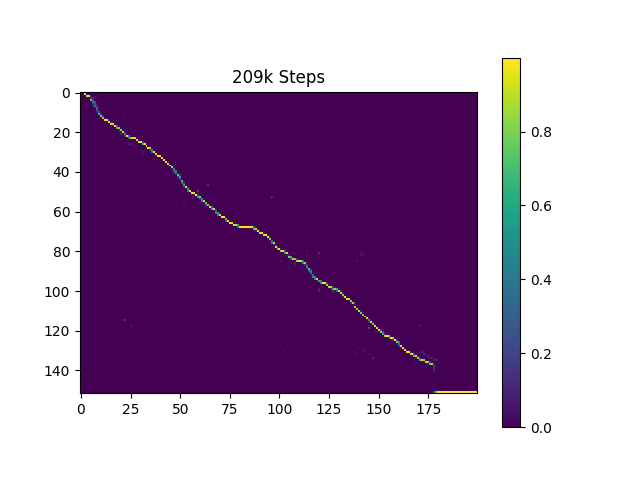
Eu gero amostras de fala com base nas frases de Harvard como o artigo original. Já está incluído no repo.
synthesize.py e verifique os arquivos nas samples . | Conjunto de dados | Amostras |
|---|---|
| LJ | 50k 200k 310k 800k |
| Nick | 40k 170k 300k 800k |
| Kate | 40k 160k 300k 800k |
| KSS | 400K |
Baixe isso.


