dc_tts
1.0.0
ฉันใช้รูปแบบการพูดแบบข้อความเป็นคำพูด DC-TTS อีกรุ่นหนึ่งซึ่งเปิดตัวในระบบการพูดแบบข้อความที่สามารถฝึกอบรมได้อย่างมีประสิทธิภาพโดยใช้เครือข่ายที่ลึกล้ำด้วยความสนใจที่ได้รับความสนใจ อย่างไรก็ตามเป้าหมายของฉันไม่ได้เป็นเพียงการจำลองกระดาษ ค่อนข้างฉันต้องการที่จะได้รับข้อมูลเชิงลึกเกี่ยวกับโครงการเสียงต่าง ๆ
tf.contrib.layers.layer_norm มีการเปลี่ยนแปลงตั้งแต่ 1.3)ฉันฝึกฝนโมเดลภาษาอังกฤษและโมเดลเกาหลีในชุดข้อมูลการพูดที่แตกต่างกันสี่ชุด
1. ชุดข้อมูลคำพูด LJ
2. หนังสือเสียงของ Nick Offerman
3. หนังสือเสียงของ Kate Winslet
4. ชุดข้อมูล KSS
ชุดข้อมูลคำพูด LJ เพิ่งถูกใช้อย่างกว้างขวางเป็นชุดข้อมูลมาตรฐานในงาน TTS เพราะมีให้บริการแบบสาธารณะและมีตัวอย่างคุณภาพที่สมเหตุสมผล 24 ชั่วโมง หนังสือเสียงของ Nick และ Kate นั้นใช้เพื่อดูว่าโมเดลสามารถเรียนรู้ได้หรือไม่แม้จะมีข้อมูลน้อยลง พวกเขามีความยาว 18 ชั่วโมงและ 5 ชั่วโมงตามลำดับ ในที่สุดชุดข้อมูล KSS เป็นชุดข้อมูลคำพูดลำโพงเดี่ยวเกาหลีที่ใช้เวลานานกว่า 12 ชั่วโมง
hyperparams.py (หากคุณต้องการทำการประมวลผลล่วงหน้าให้ตั้งค่า prepro true`python train.py 1 สำหรับการฝึกอบรม text2mel (หากคุณตั้งค่า prepro จริงให้เรียกใช้ python prepro.py ก่อน)python train.py 2 สำหรับการฝึกอบรม SSRNคุณสามารถทำขั้นตอนที่ 2 และ 3 ในเวลาเดียวกันหากคุณมีการ์ด GPU มากกว่าหนึ่งใบ
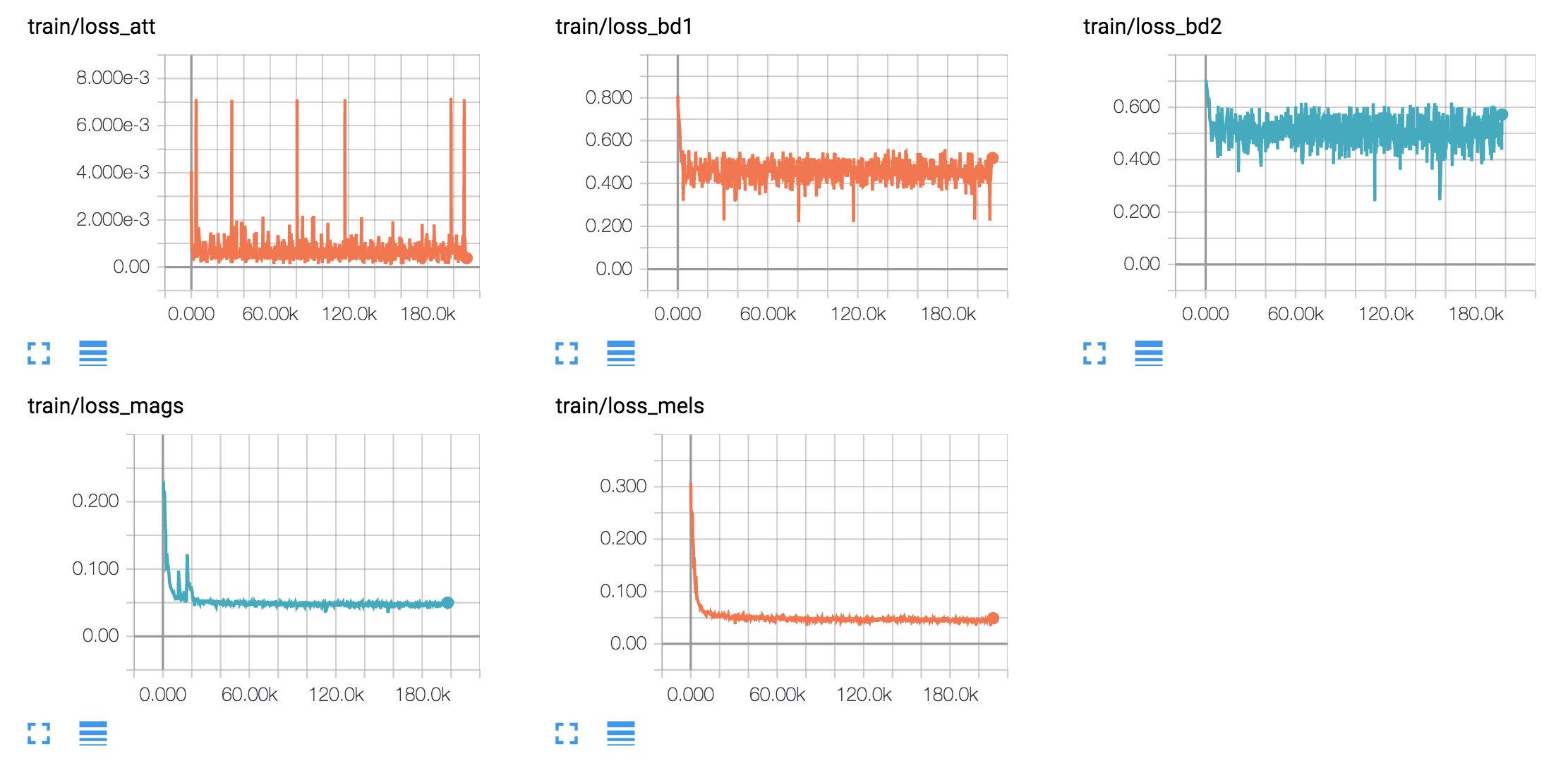
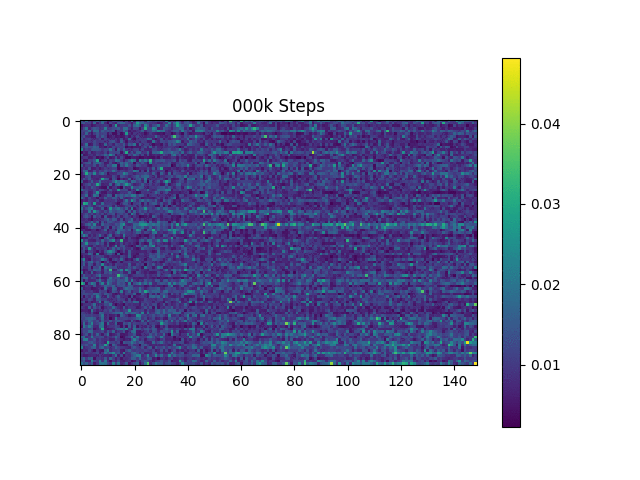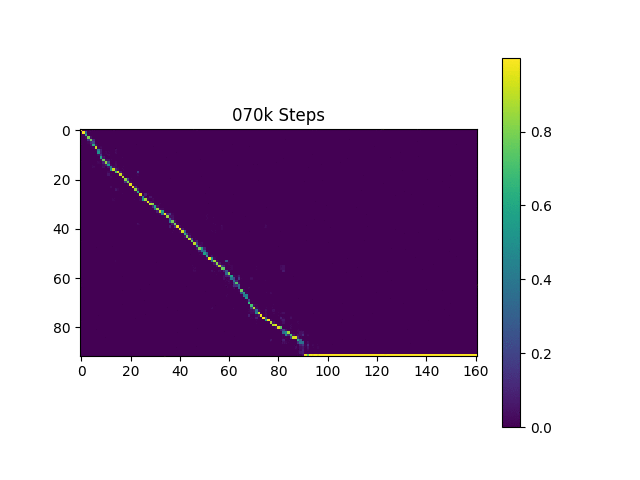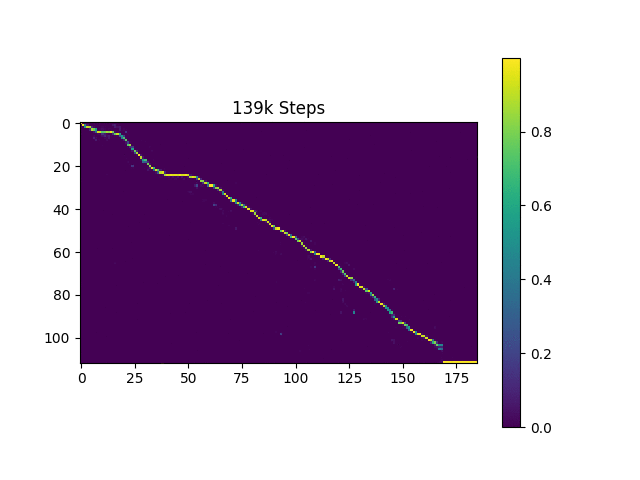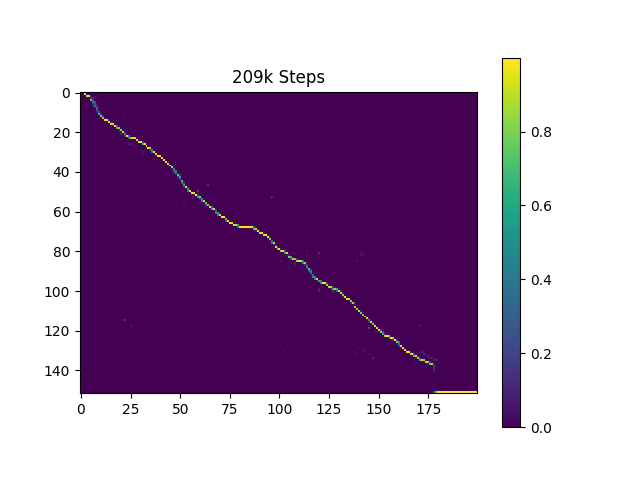
ฉันสร้างตัวอย่างการพูดตามประโยคฮาร์วาร์ดเหมือนกระดาษต้นฉบับ มันรวมอยู่ใน repo แล้ว
synthesize.py และตรวจสอบไฟล์ใน samples | ชุดข้อมูล | ตัวอย่าง |
|---|---|
| LJ | 50K 200K 310K 800K |
| นิค | 40K 170K 300K 800K |
| เคท | 40K 160K 300K 800K |
| KSS | 400K |
ดาวน์โหลดสิ่งนี้


