dc_tts
1.0.0
J'implémente un autre modèle de texte vocal, DC-TTS, introduit dans un système de texte vocal à dispection efficace basé sur des réseaux de convolution profonde avec une attention guidée. Mon objectif, cependant, n'est pas seulement de reproduire le papier. J'aimerais plutôt obtenir des informations sur divers projets sonores.
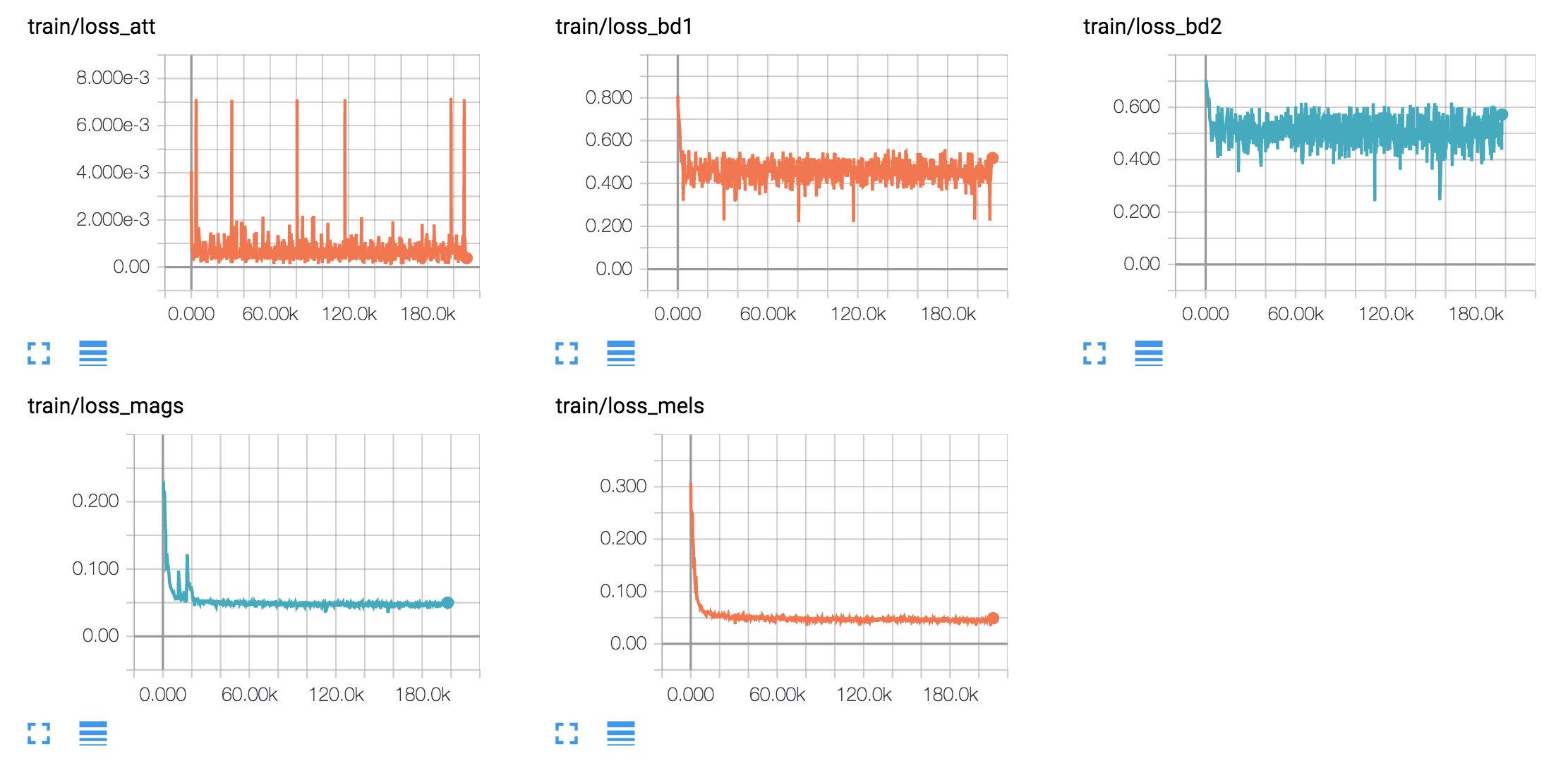
tf.contrib.layers.layer_norm a changé depuis 1.3)Je forme des modèles en anglais et un modèle coréen sur quatre ensembles de données vocaux différents.
1. Ensemble de données de discours LJ
2. Les livres audio de Nick Offerman
3. Look audio de Kate Winslet
4. ensemble de données KSS
L'ensemble de données de la parole LJ est récemment largement utilisé comme ensemble de données de référence dans la tâche TTS car il est accessible au public, et il a 24 heures d'échantillons de qualité raisonnable. Les livres audio de Nick et Kate sont également utilisés pour voir si le modèle peut apprendre même avec moins de données, des échantillons de parole variables. Ils durent respectivement 18 heures et 5 heures. Enfin, l'ensemble de données KSS est un ensemble de données de discours de haut-parleur unique coréen qui dure plus de 12 heures.
hyperparams.py . (Si vous voulez faire du prétraitement, définissez Prepro True`.python train.py 1 pour la formation Text2Mel. (Si vous définissez Prepro True, exécutez Python Prepro.py d'abord)python train.py 2 pour la formation SSRN.Vous pouvez faire les étapes 2 et 3 en même temps, si vous avez plus d'une carte GPU.
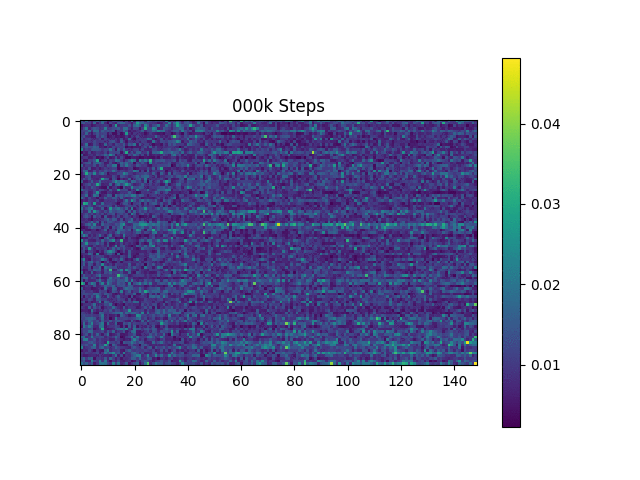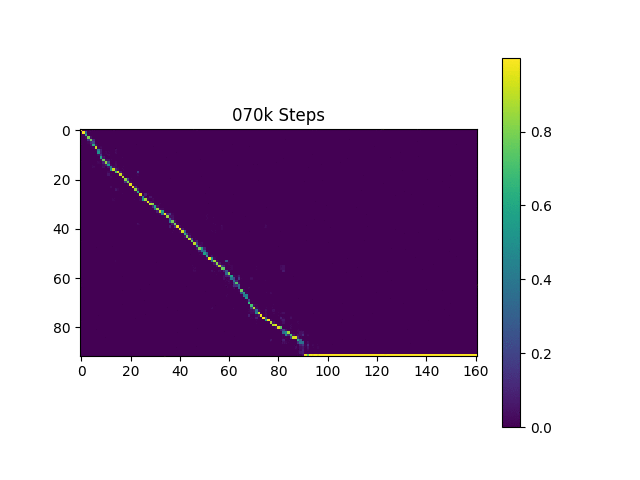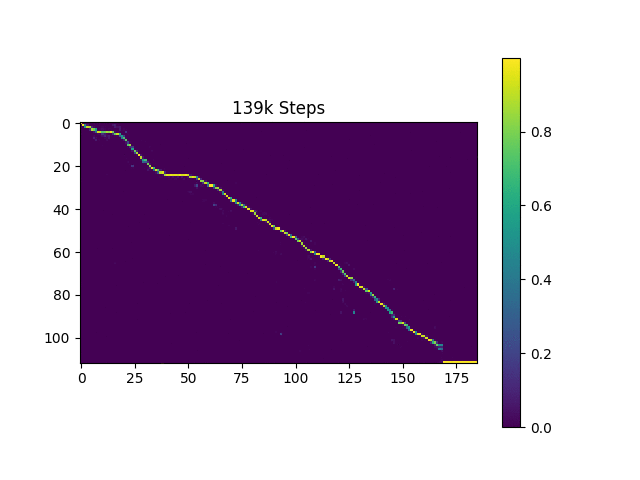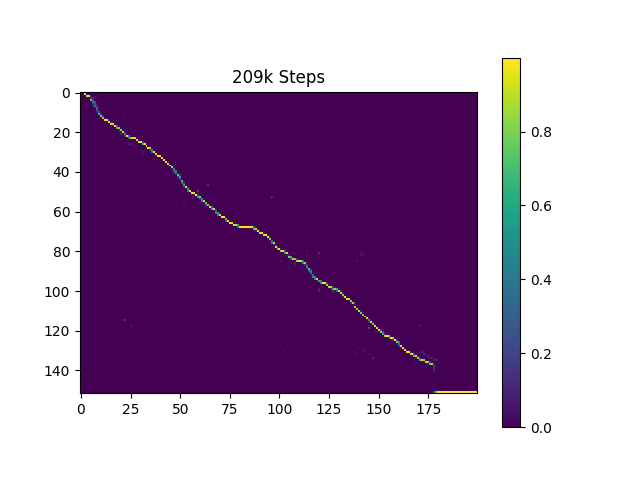
Je génère des échantillons de discours basés sur les phrases de Harvard comme le fait le papier d'origine. Il est déjà inclus dans le dépôt.
synthesize.py et vérifiez les fichiers dans samples . | Ensemble de données | Échantillons |
|---|---|
| LJ | 50K 200K 310K 800K |
| Entaille | 40K 170K 300K 800K |
| Kate | 40K 160K 300K 800K |
| KSS | 400k |
Téléchargez ce.


