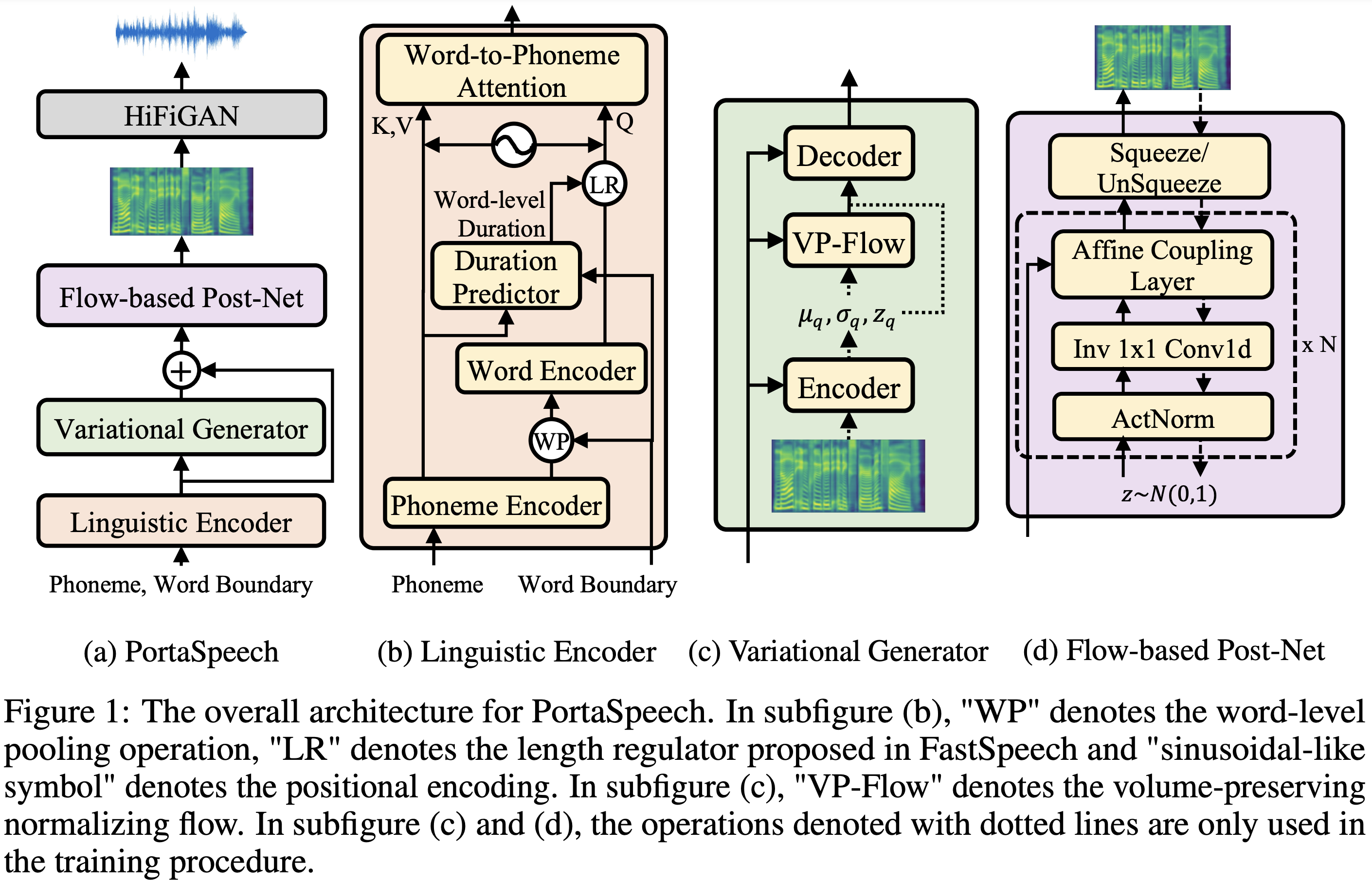
PortaSpeech
v0.2.0
PORTASPEECH的PYTORCH实现:便携式和高质量的生成文本到语音。
音频样本可在 /演示中找到。
| 模块 | 普通的 | 小的 | 正常(纸) | 小(纸) |
|---|---|---|---|---|
| 全部的 | 24m | 76m | 2180万 | 6.7m |
| 语言语言编码器 | 3.7m | 14m | - | - |
| 变性生机体 | 11m | 28m | - | - |
| FlowPostnet | 9.3m | 3.4m | - | - |
数据集是指以下文档中的数据集的名称,例如LJSpeech 。
您可以使用
pip3 install -r requirements.txt
此外,还为Docker用户提供Dockerfile 。
您必须下载验证的型号,并将它们放入output/ckpt/DATASET/ 。
对于单扬声器TTS ,运行
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
生成的话语将放入output/result/ 。
也支持批次推理,尝试
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
综合preprocessed_data/DATASET/val.txt中的所有话语。
可以通过指定所需的持续时间比来控制合成的话语的口语速率。例如,一个人可以将口语率提高20
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8
请注意,可控性起源于FastSpeech2,而不是PortAspeech的重要利益。
支持的数据集是
跑步
python3 prepare_align.py --dataset DATASET
用于一些准备工作。
对于强制对准,蒙特利尔强制对准器(MFA)用于获得发音和音素序列之间的比对。此处提供了数据集的预提取对齐。您必须在preprocessed_data/DATASET/TextGrid/中解压缩文件。或者,您可以自己运行对准器。
之后,通过
python3 preprocess.py --dataset DATASET
培训您的模型
python3 train.py --dataset DATASET
有用的选项:
--use_amp参数附加到上述命令中。CUDA_VISIBLE_DEVICES=<GPU_IDs> 。使用
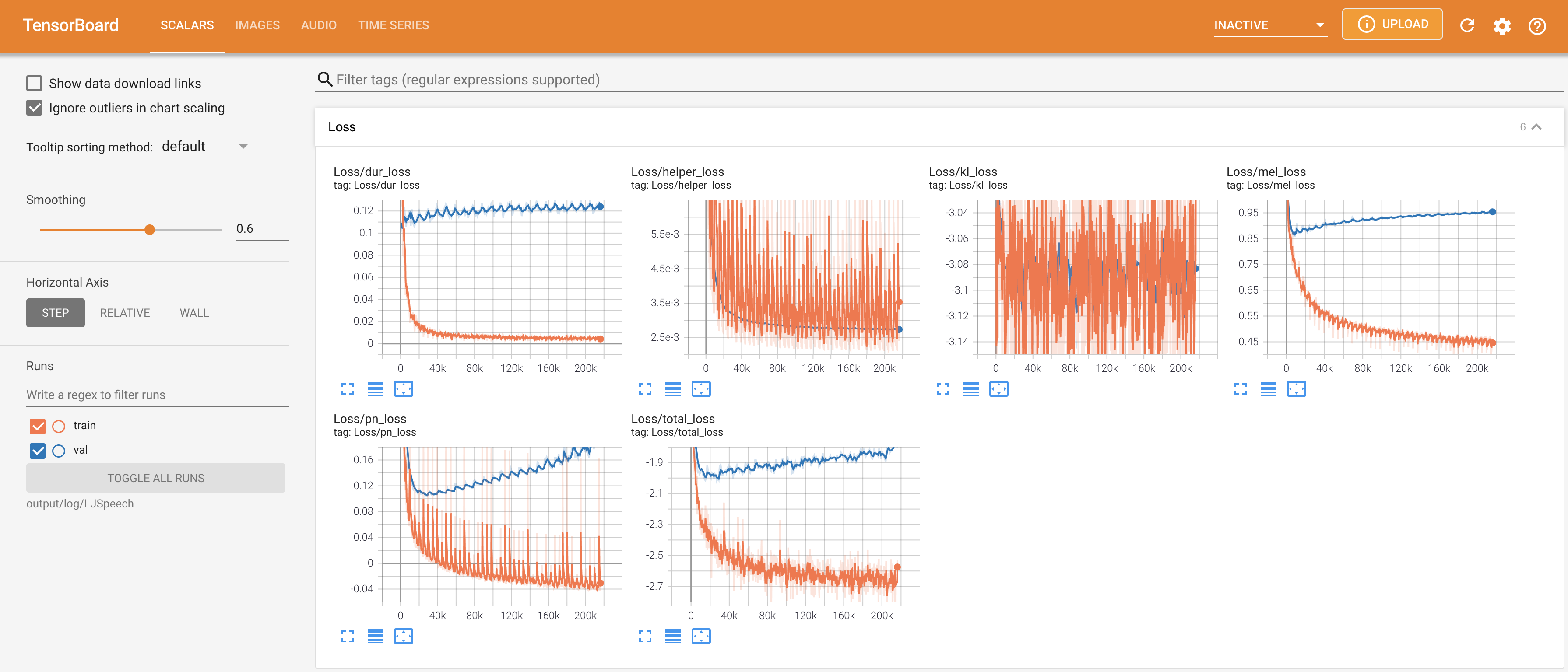
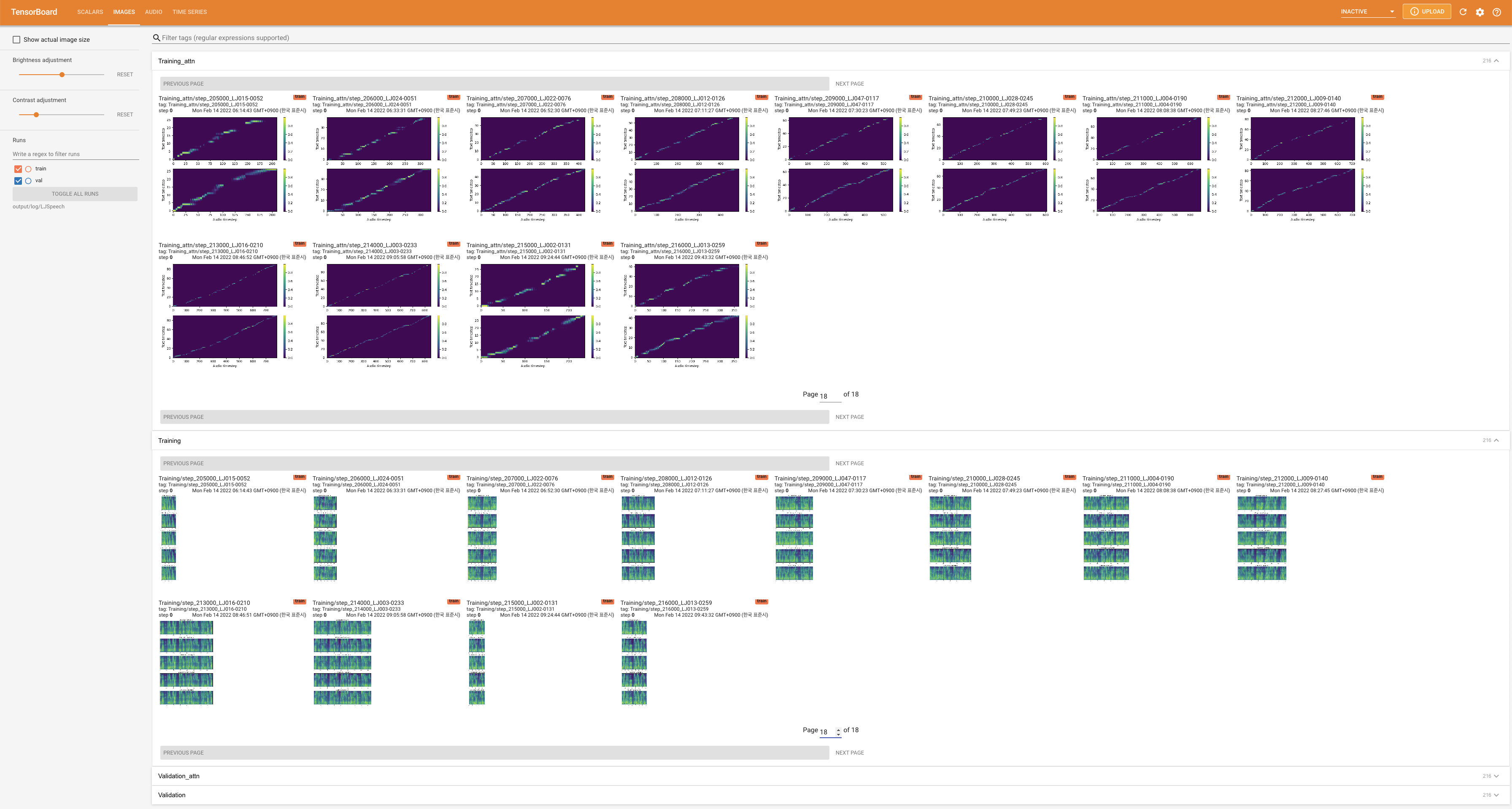
tensorboard --logdir output/log
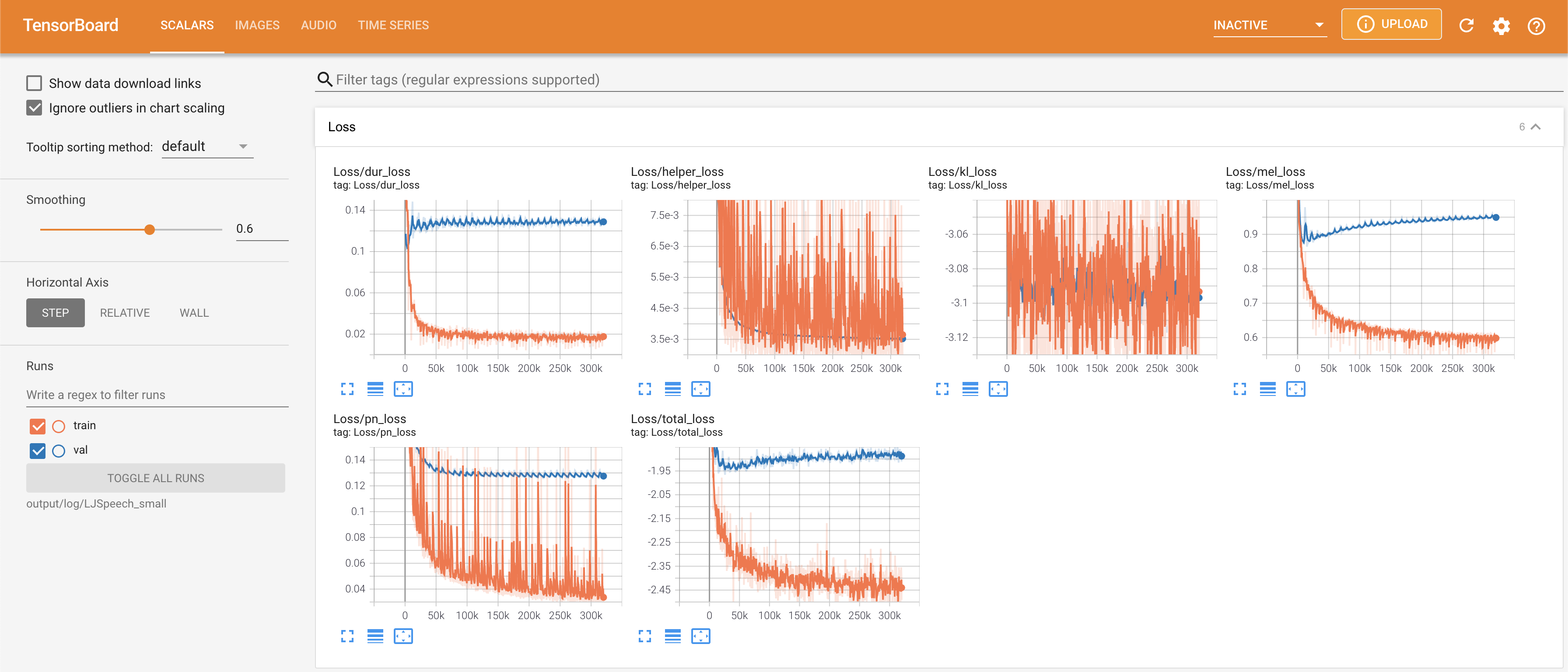
在您的本地主机上提供张板。显示了损耗曲线,合成的MEL光谱图和音频。
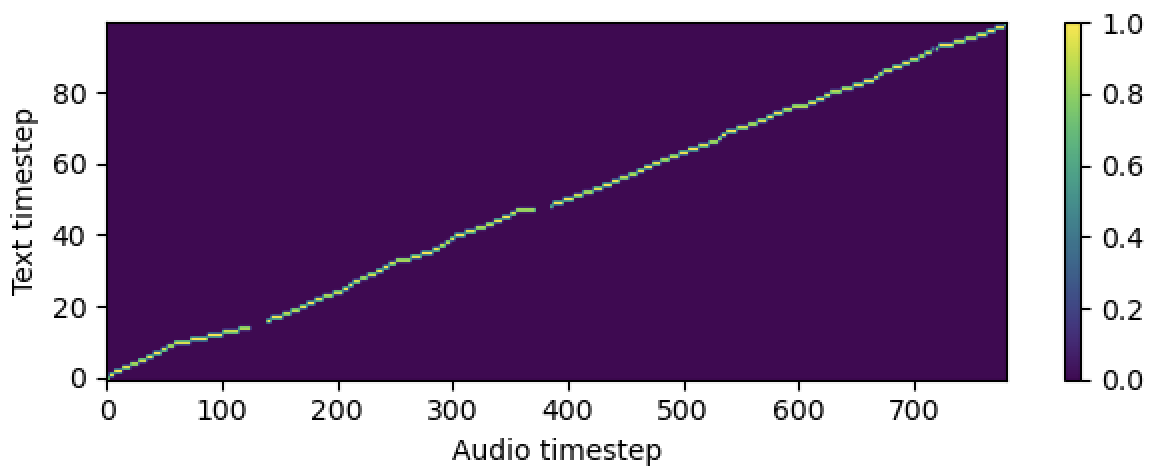
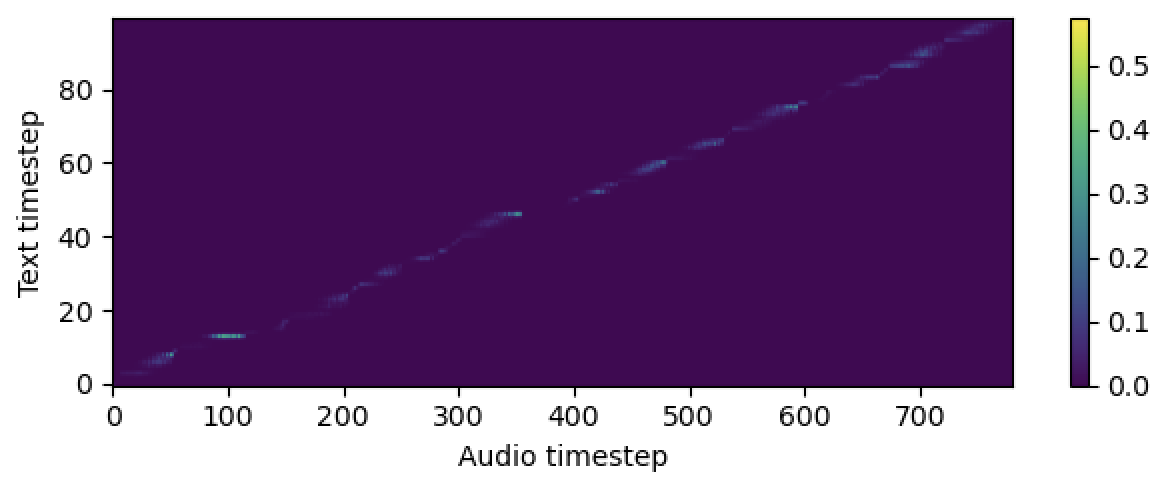
# In the train.yaml
aligner :
helper_type : " dga " # ["dga", "ctc", "none"]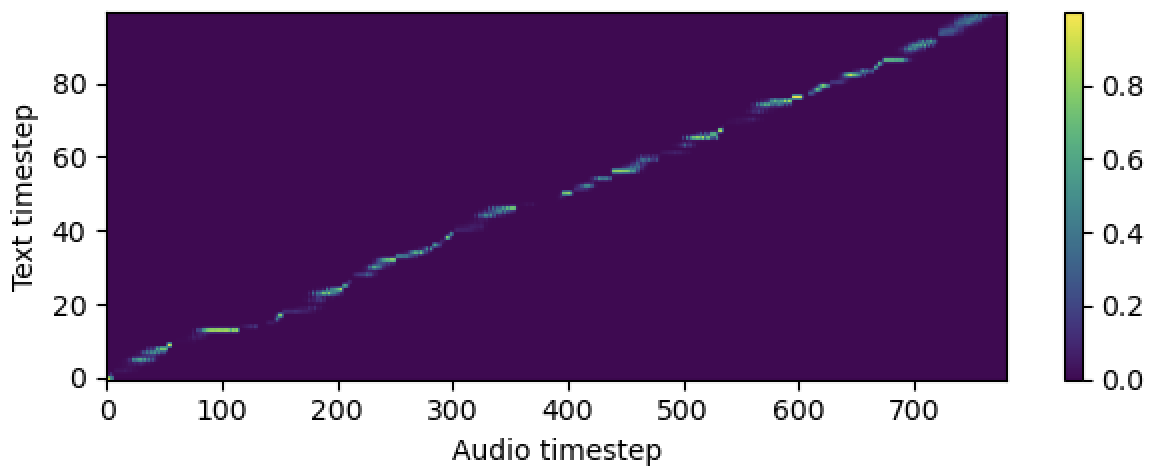
请用“引用此存储库”的“关于部分”(主页的右上角)引用此存储库。


