PortaSpeech
v0.2.0
Implémentation de Pytorch de PortaspaspEech: Texte-voca-vocation génératif portable et de haute qualité.
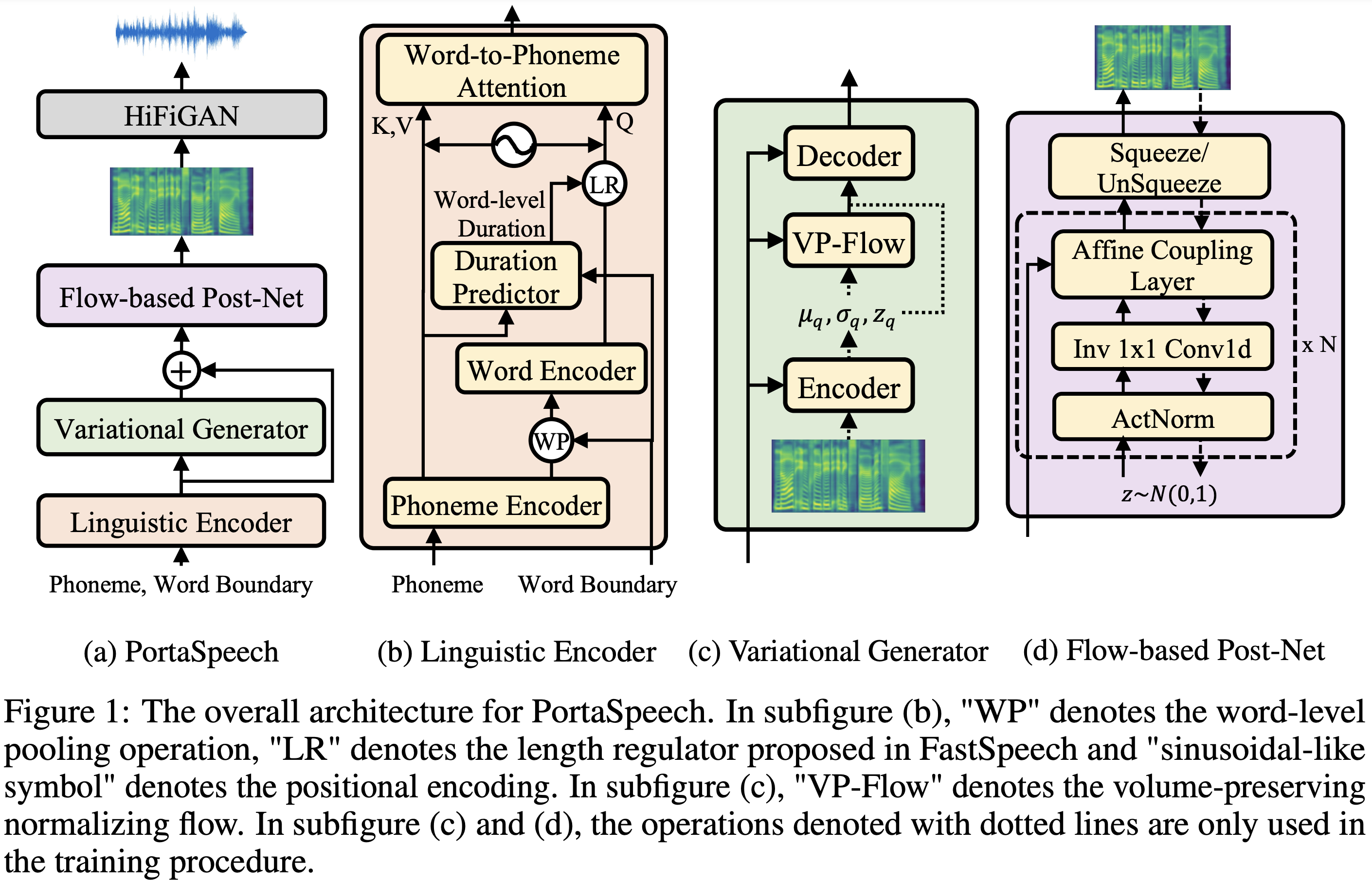
Des échantillons audio sont disponibles à / démo.
| Module | Normale | Petit | Normal (papier) | Petit (papier) |
|---|---|---|---|---|
| Total | 24m | 7,6 m | 21,8 m | 6,7 m |
| Linguistique | 3,7 m | 1,4 m | - | - |
| VariationalGenerator | 11m | 2,8 m | - | - |
| FlowPostNet | 9.3m | 3,4 m | - | - |
L'ensemble de données fait référence aux noms des ensembles de données tels que LJSpeech dans les documents suivants.
Vous pouvez installer les dépendances Python avec
pip3 install -r requirements.txt
De plus, Dockerfile est fourni pour les utilisateurs Docker .
Vous devez télécharger les modèles pré-entraînés et les mettre dans output/ckpt/DATASET/ .
Pour un TTS à un seul haut-parleur , courez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Les énoncés générés seront placés en output/result/ .
L'inférence par lots est également prise en charge, essayez
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Pour synthétiser toutes les énoncés dans preprocessed_data/DATASET/val.txt .
Le taux de parole des énoncés synthétisés peut être contrôlé en spécifiant les rapports de durée souhaités. Par exemple, on peut augmenter le taux de parole de 20 par
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8
Veuillez noter que la contrôlabilité est originaire de FastSpeech2 et non un intérêt vital de PortaspaspEech.
Les ensembles de données pris en charge sont
Courir
python3 prepare_align.py --dataset DATASET
pour certaines préparatifs.
Pour l'alignement forcé, l'aligneur forcé de Montréal (MFA) est utilisé pour obtenir les alignements entre les énoncés et les séquences de phonèmes. Les alignements pré-extractés pour les ensembles de données sont fournis ici. Vous devez décompresser les fichiers dans preprocessed_data/DATASET/TextGrid/ . Alternativement, vous pouvez exécuter l'aligneur par vous-même.
Après cela, exécutez le script de prétraitement par
python3 preprocess.py --dataset DATASET
Former votre modèle avec
python3 train.py --dataset DATASET
Options utiles:
--use_amp à la commande ci-dessus.CUDA_VISIBLE_DEVICES=<GPU_IDs> au début de la commande ci-dessus.Utiliser
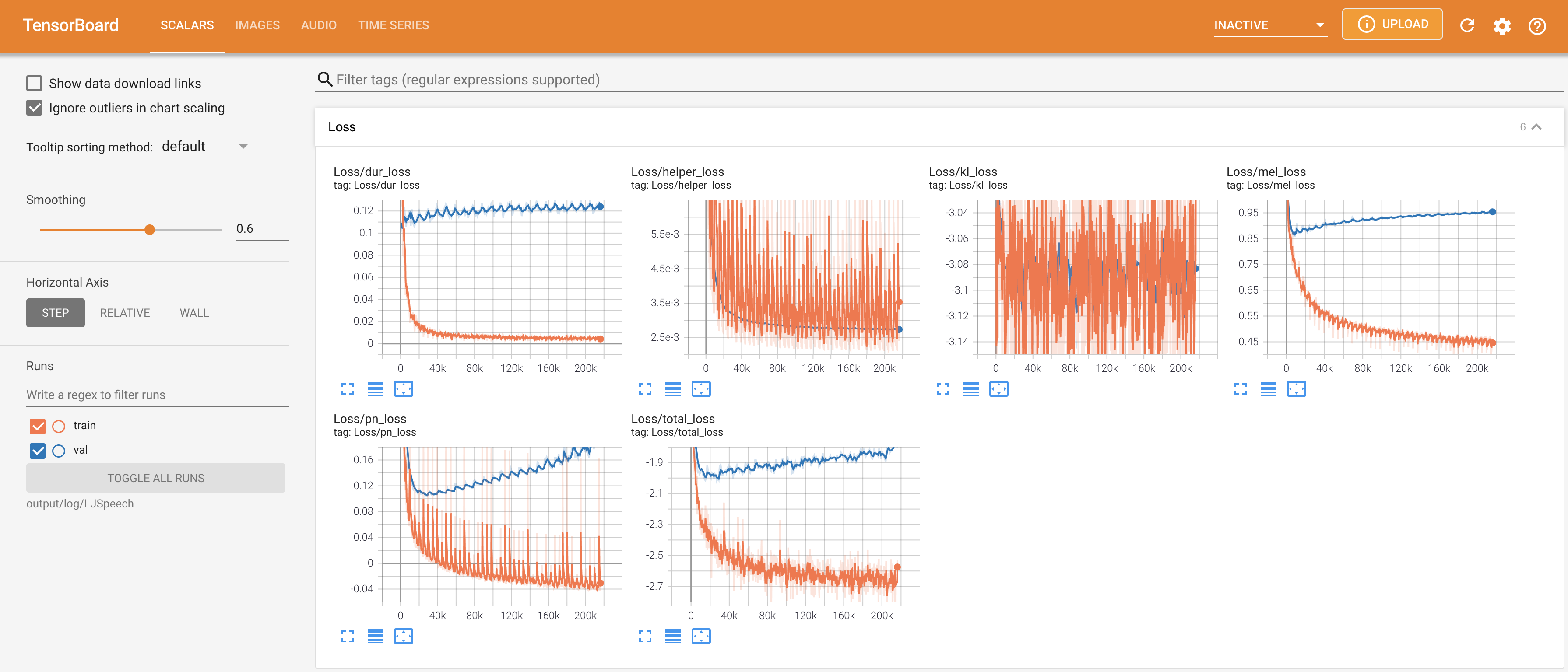
tensorboard --logdir output/log
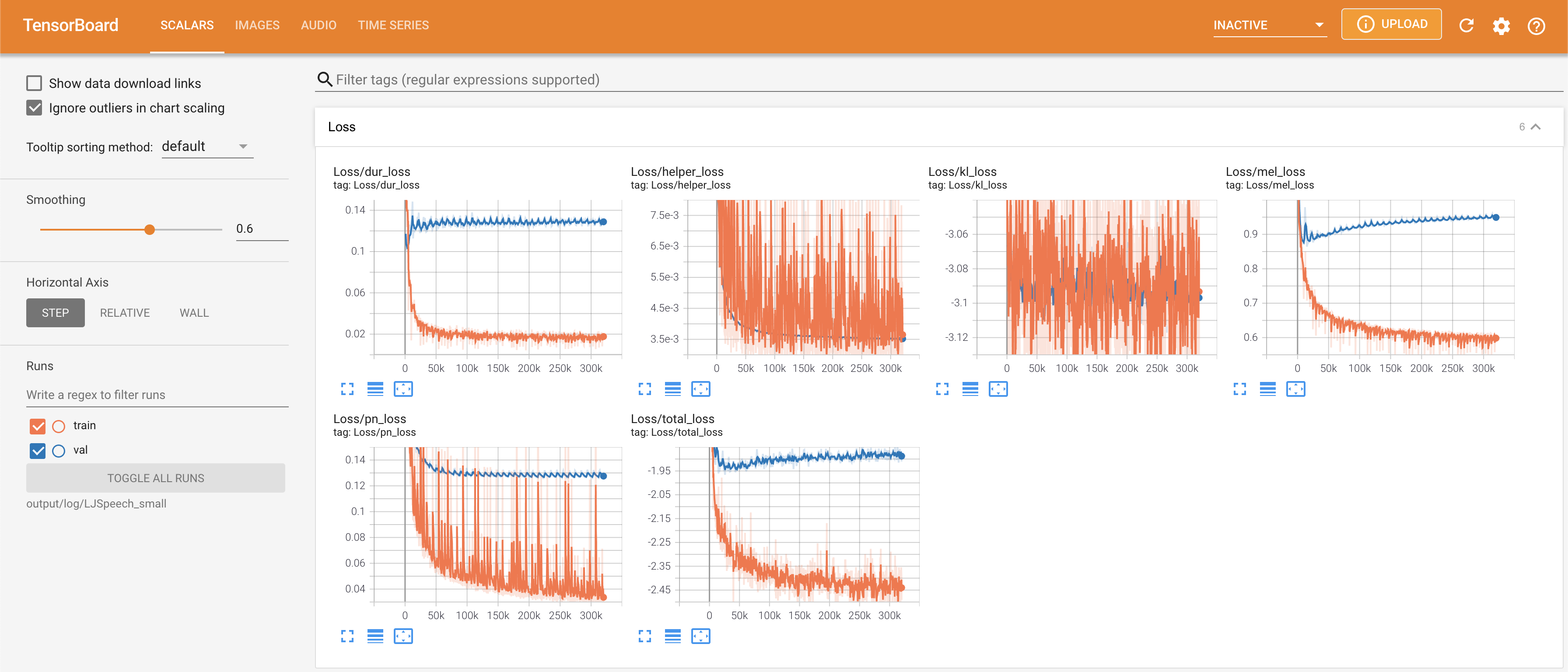
pour servir Tensorboard sur votre hôte local. Les courbes de perte, les spectrogrammes de MEL synthétisés et les audios sont affichés.
# In the train.yaml
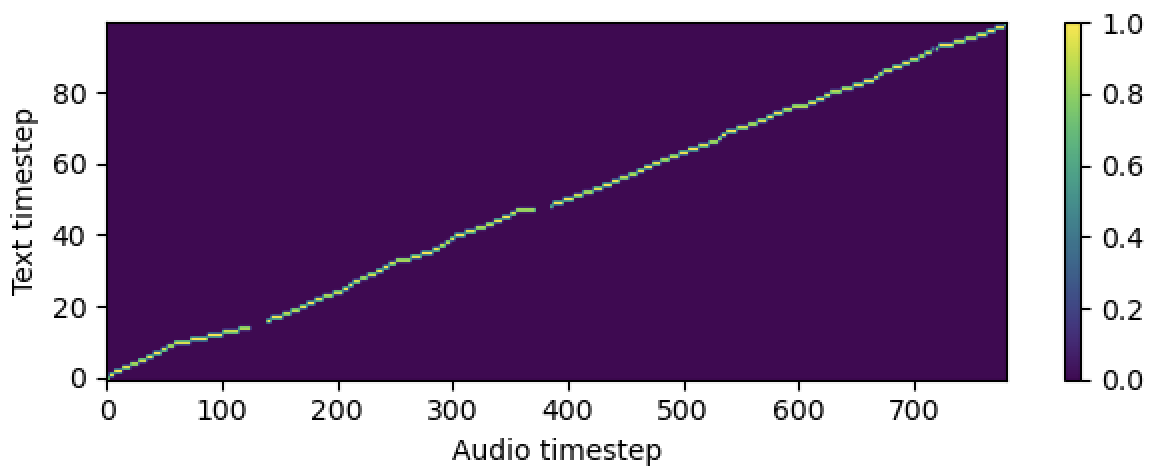
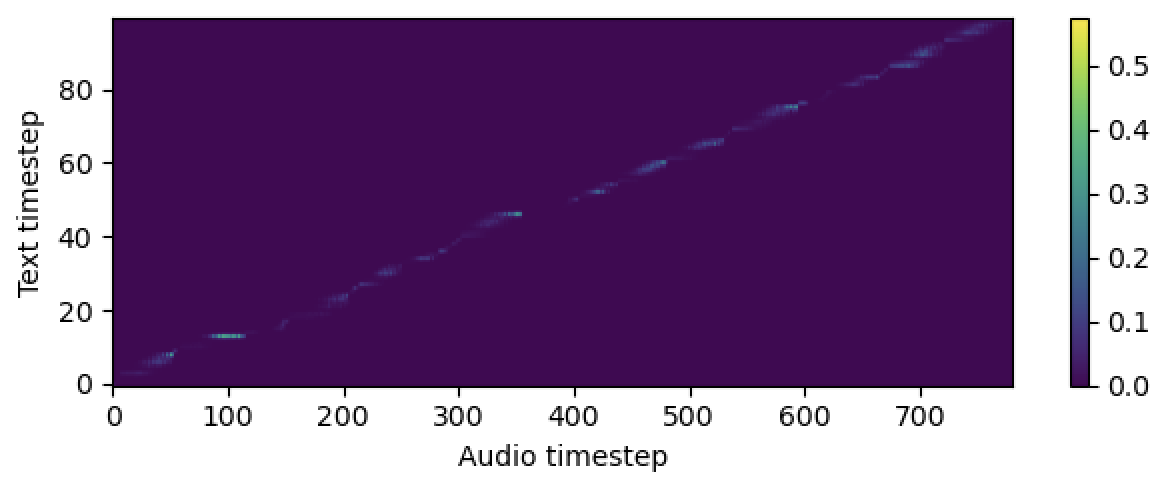
aligner :
helper_type : " dga " # ["dga", "ctc", "none"]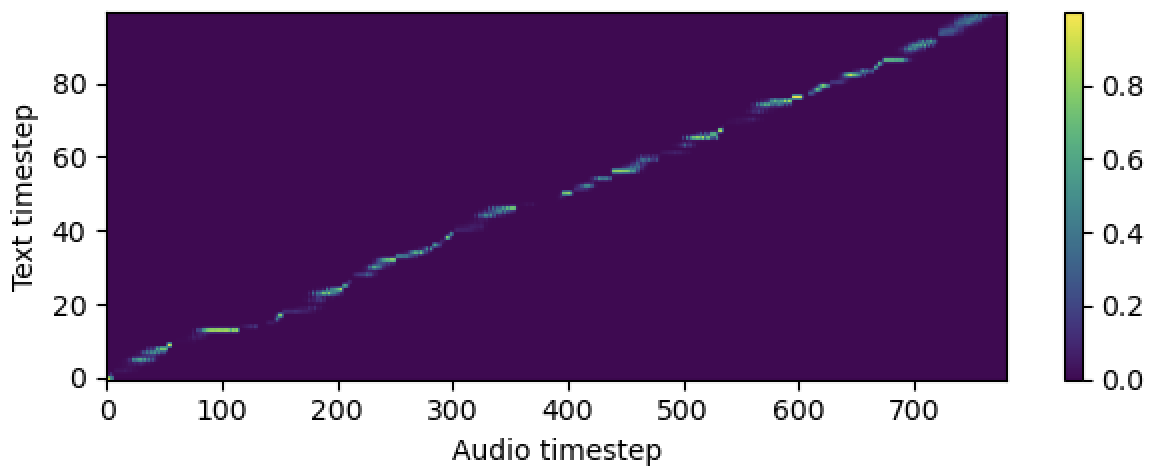
Veuillez citer ce référentiel par le "Citez ce référentiel" de la section environ (en haut à droite de la page principale).


