PortaSpeech
v0.2.0
Реализация Pytorch Portaspeech: портативный и высококачественный генеративный текст в речь.
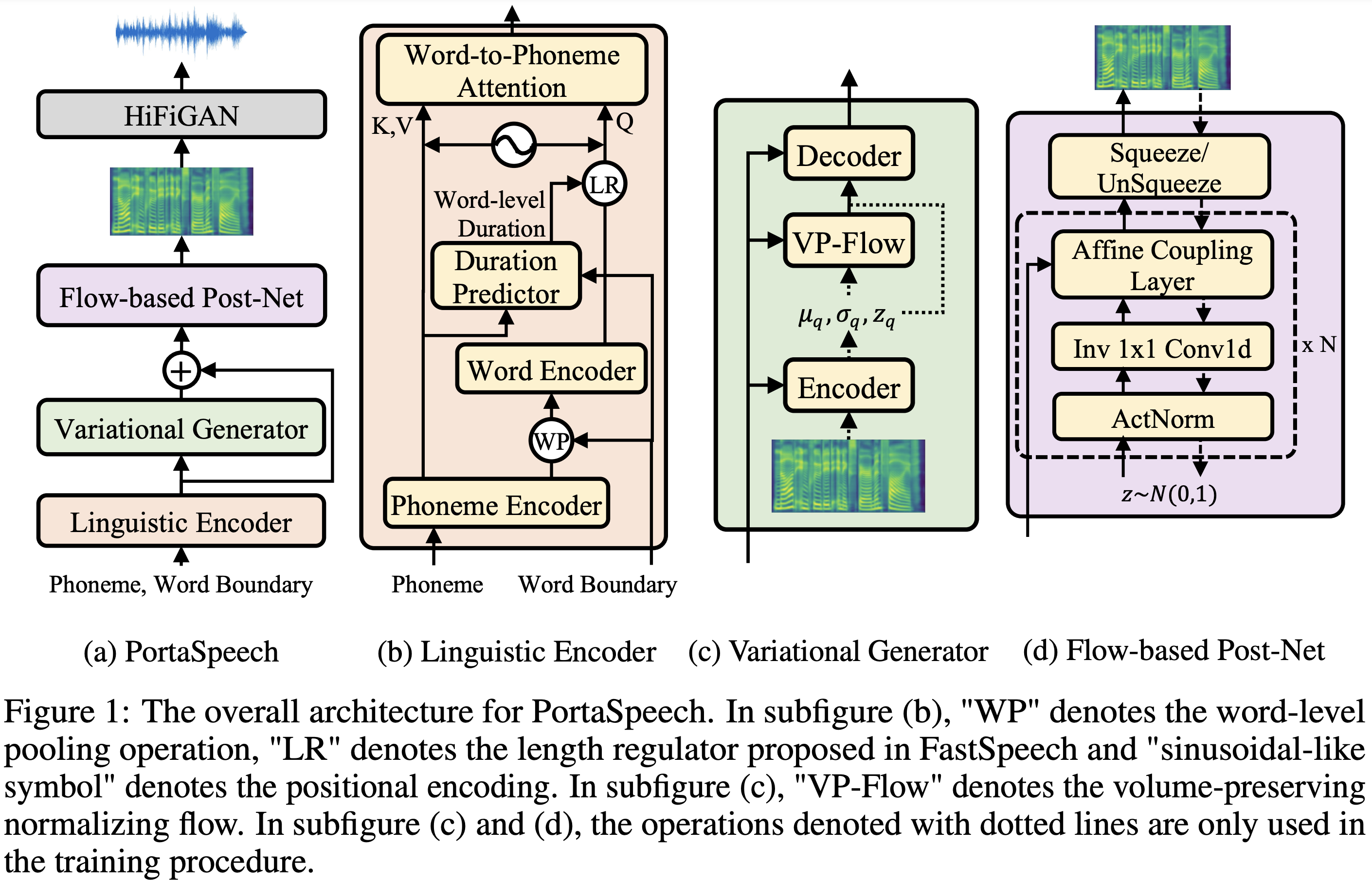
Образцы аудио доступны в /демо.
| Модуль | Нормальный | Маленький | Нормальный (бумага) | Маленький (бумага) |
|---|---|---|---|---|
| Общий | 24 м | 7,6 м | 21,8 млн | 6,7 м |
| Linguisticencoder | 3,7 м | 1,4 м | - | - |
| VariationalGenerator | 11m | 2,8 м | - | - |
| Flowpostnet | 9,3 м | 3,4 м | - | - |
Набор данных относится к именам наборов данных, таких как LJSpeech в следующих документах.
Вы можете установить зависимости Python с
pip3 install -r requirements.txt
Кроме того, Dockerfile предоставлен для пользователей Docker .
Вы должны загрузить предварительно подготовленные модели и поместить их в output/ckpt/DATASET/ .
Для одноразовых TTS , бегите
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Сгенерированные высказывания будут помещены в output/result/ .
Пакетный вывод также поддерживается, попробуйте
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Чтобы синтезировать все высказывания в preprocessed_data/DATASET/val.txt .
Скорость разговора синтезированных высказываний может контролироваться путем указания желаемых коэффициентов продолжительности. Например, можно увеличить скорость разговора на 20 на
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8
Обратите внимание, что управляемость происходит от Fastspeech2, а не жизненно важного интереса Portaspeech.
Поддерживаемые наборы данных
Бегать
python3 prepare_align.py --dataset DATASET
для некоторых приготовлений.
Для принудительного выравнивания Монреаль принудительный выравниватель (MFA) используется для получения выравнивания между высказываниями и последовательностями фонем. Предварительные выравнивания для наборов данных представлены здесь. Вы должны расстегнуть разанипировать файлы в preprocessed_data/DATASET/TextGrid/ . С другой стороны, вы можете запустить выравниватель самостоятельно.
После этого запустите сценарий предварительной обработки
python3 preprocess.py --dataset DATASET
Тренировать свою модель с
python3 train.py --dataset DATASET
Полезные варианты:
--use_amp к вышеуказанной команде.CUDA_VISIBLE_DEVICES=<GPU_IDs> в начале вышеуказанной команды.Использовать
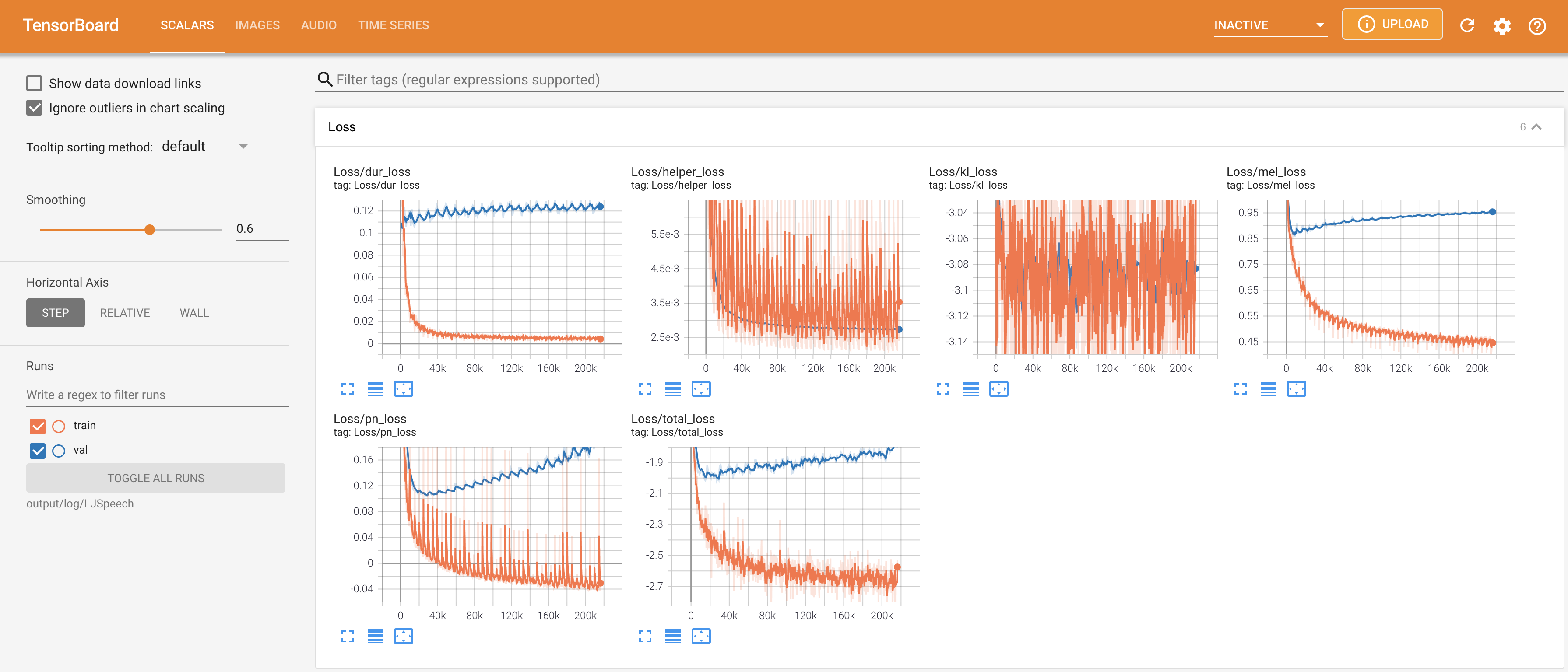
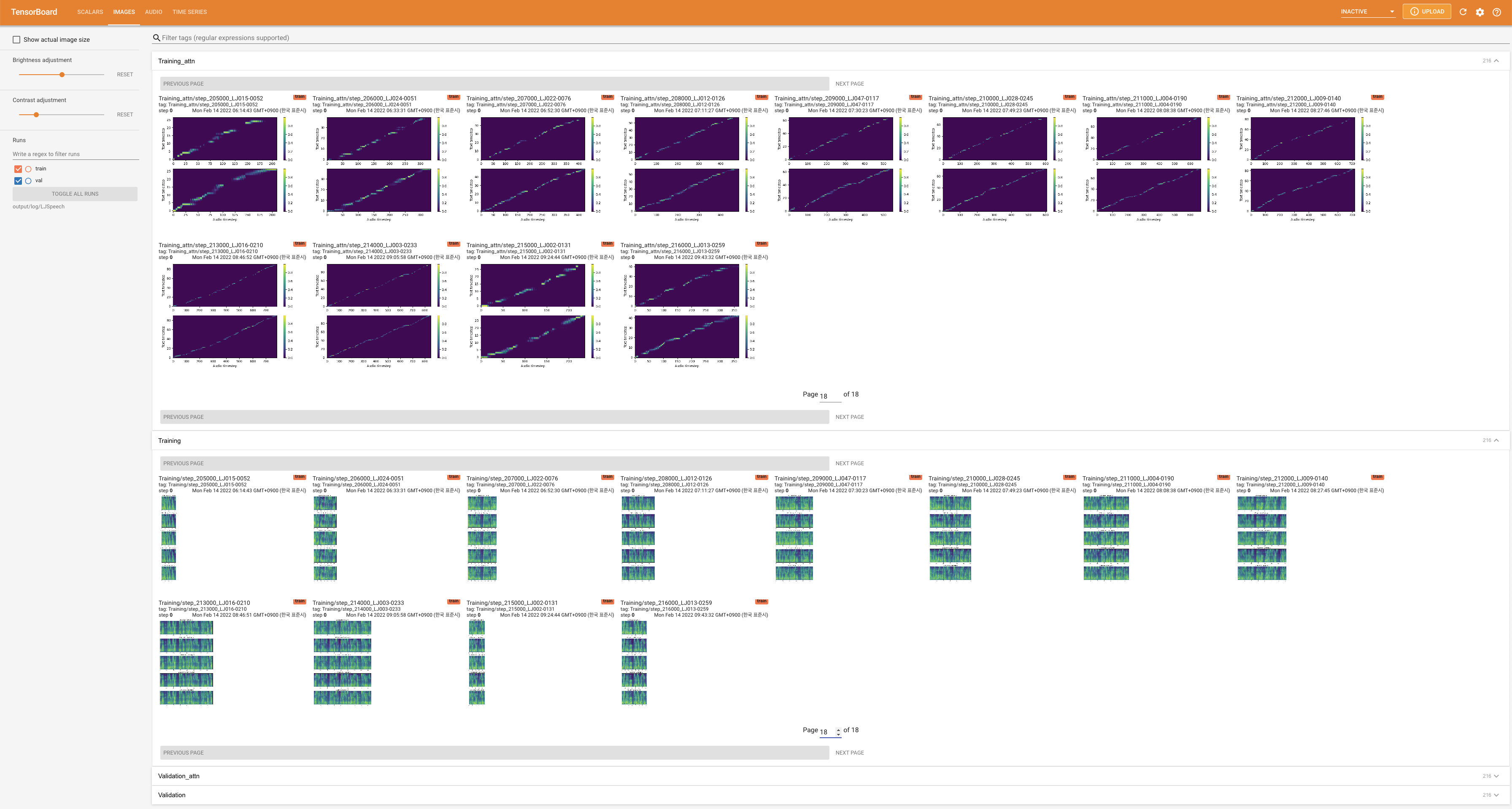
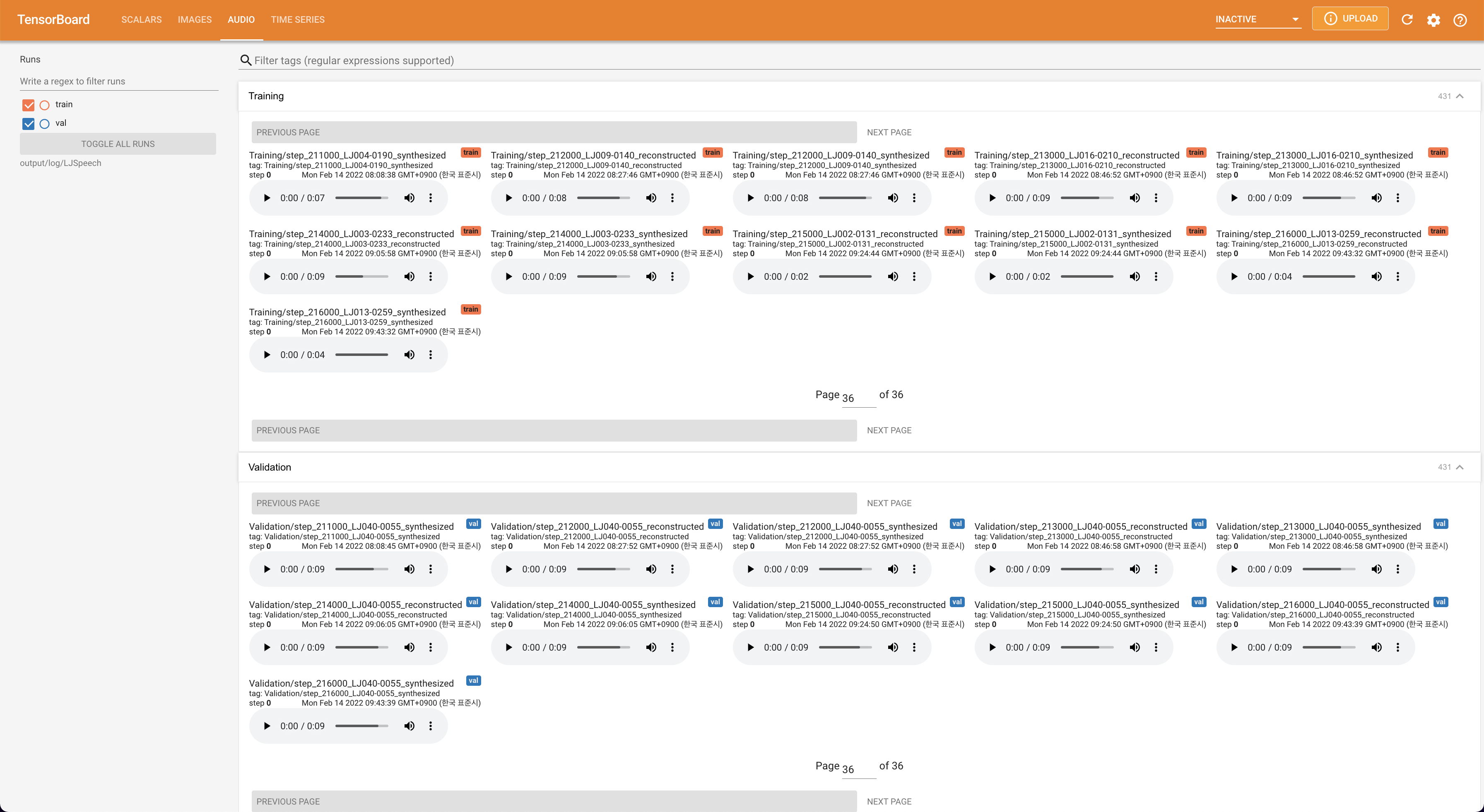
tensorboard --logdir output/log
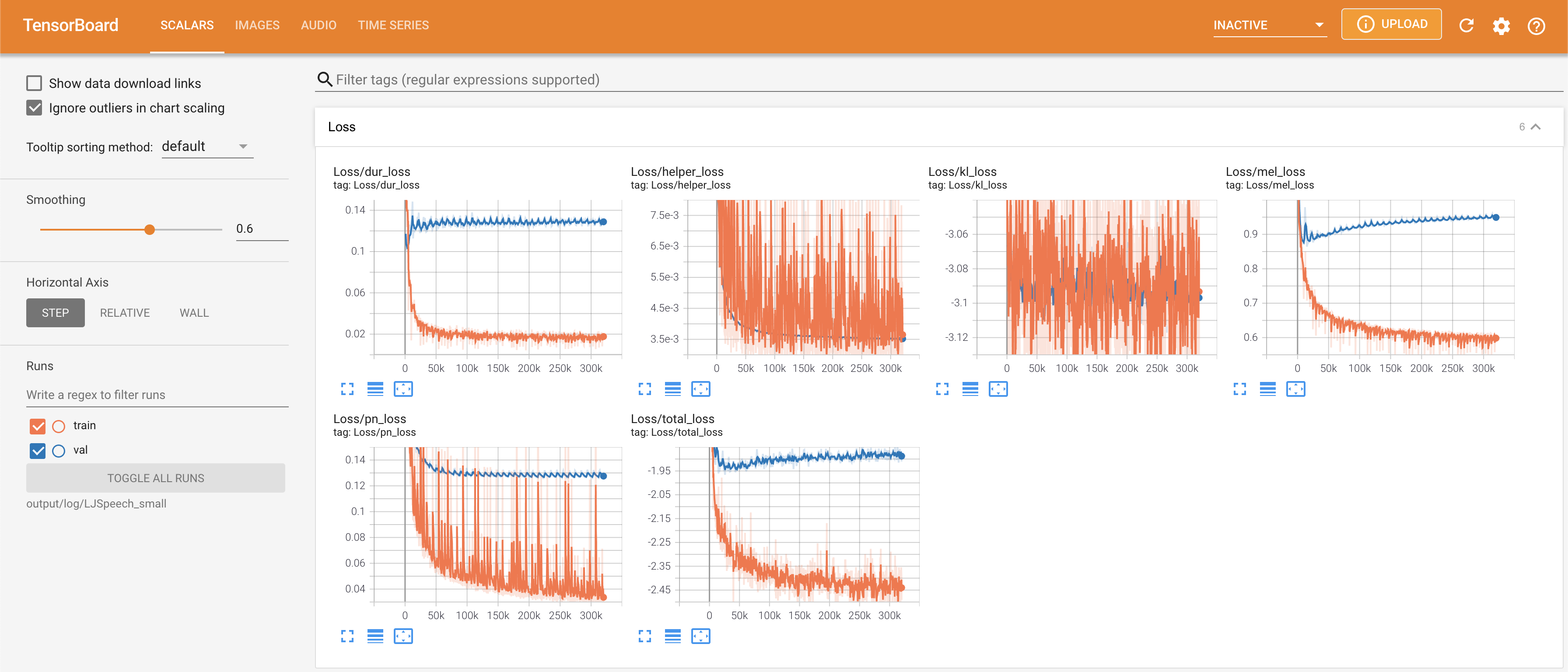
Подавать в Tensorboard на вашем местном хосте. Кривые потерь, синтезированные мель-спектрограммы и аудио показаны.
# In the train.yaml
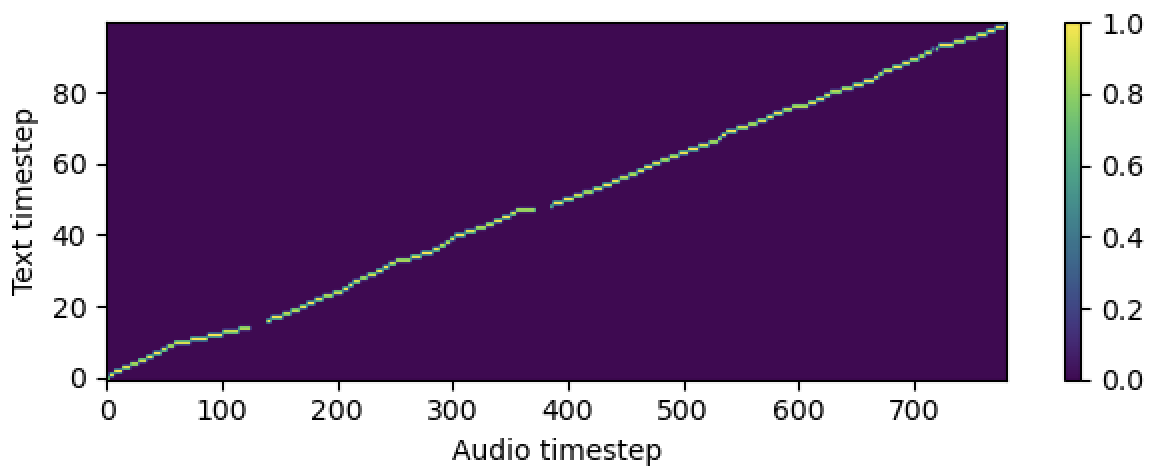
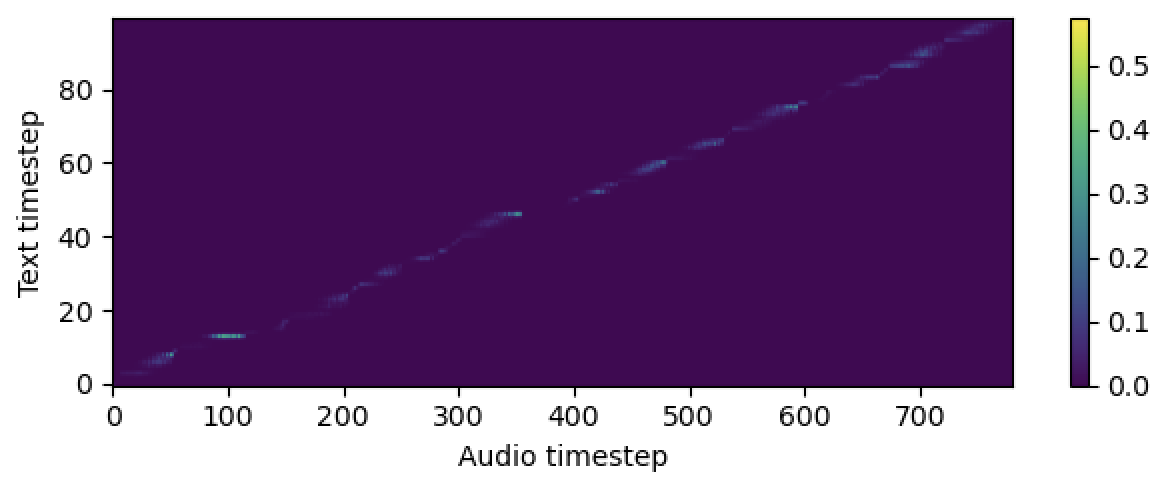
aligner :
helper_type : " dga " # ["dga", "ctc", "none"]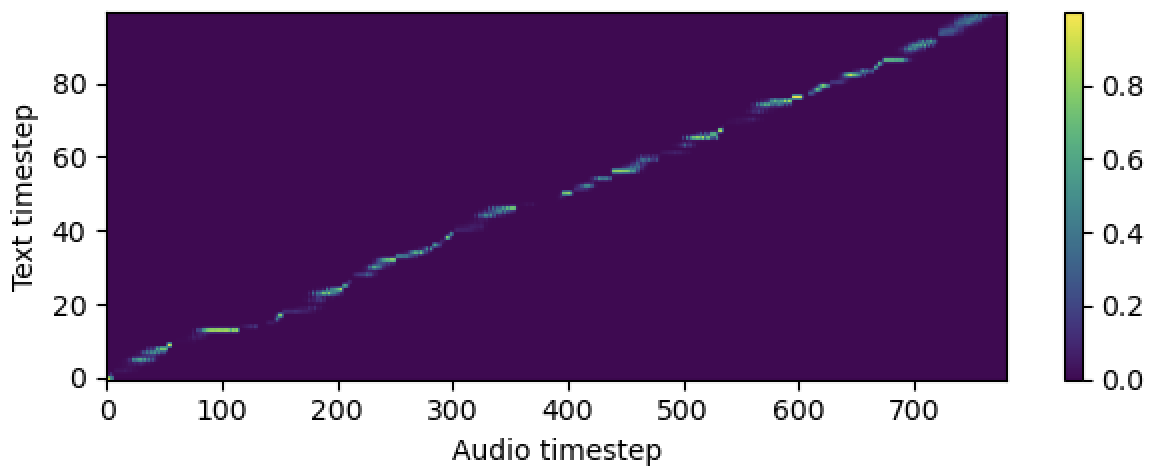
Пожалуйста, цитируйте этот репозиторий с помощью «цитируйте этот репозиторий» о разделе (верхняя правая на главной странице).


