PortaSpeech
v0.2.0
Pytorch Implementasi Portaspeech: Teks-ke-portabel dan berkualitas tinggi.
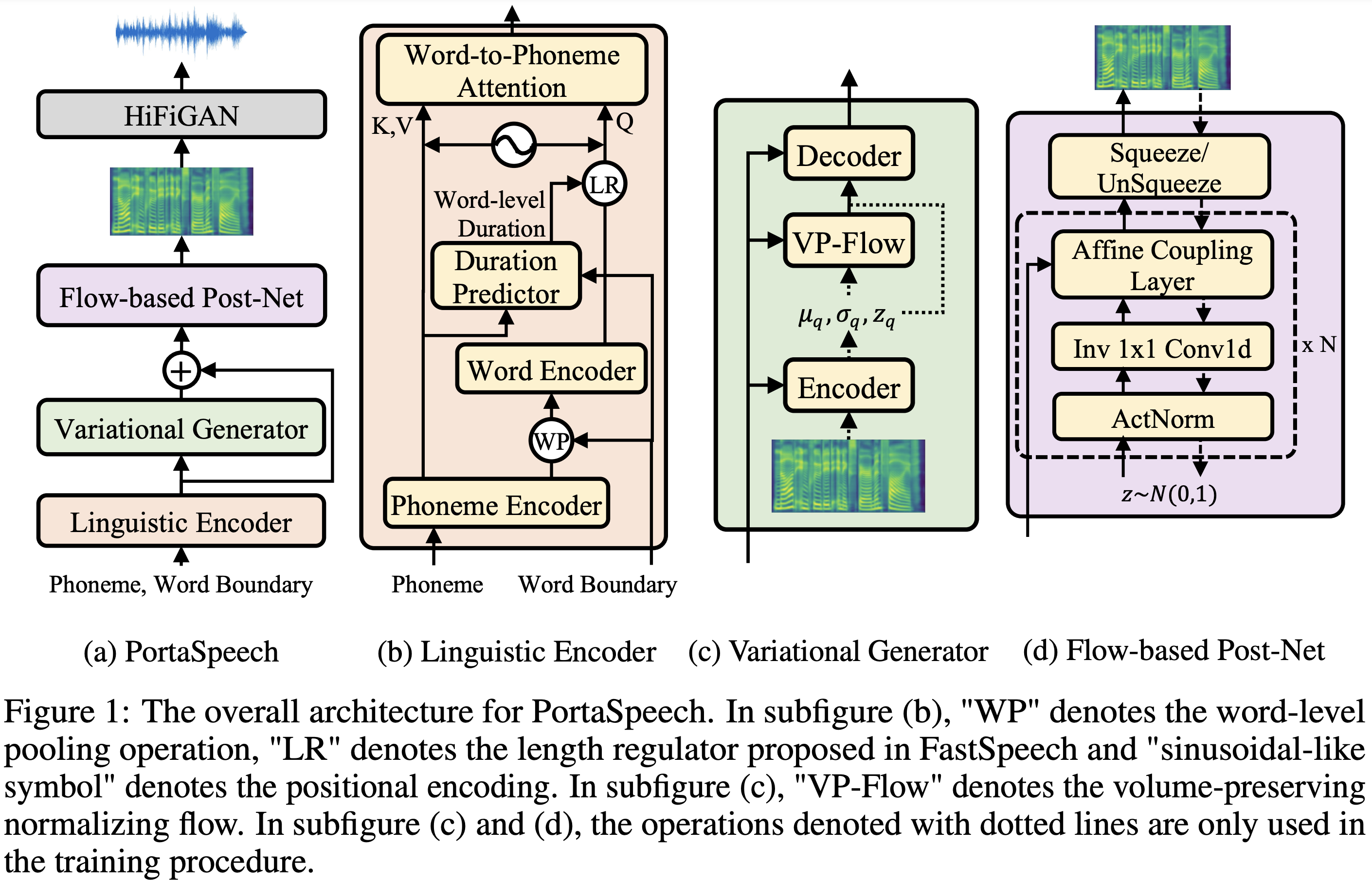
Sampel audio tersedia di /demo.
| Modul | Normal | Kecil | Normal (kertas) | Kecil (kertas) |
|---|---|---|---|---|
| Total | 24m | 7.6m | 21.8m | 6.7m |
| Linguisticencoder | 3.7m | 1.4m | - | - |
| Variasionalenerator | 11m | 2.8m | - | - |
| Flowpostnet | 9.3m | 3.4m | - | - |
Dataset mengacu pada nama dataset seperti LJSpeech dalam dokumen berikut.
Anda dapat menginstal dependensi Python dengan
pip3 install -r requirements.txt
Juga, Dockerfile disediakan untuk pengguna Docker .
Anda harus mengunduh model pretrained dan memasukkannya ke dalam output/ckpt/DATASET/ .
Untuk TTS penutur tunggal , jalankan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Ucapan yang dihasilkan akan dimasukkan ke dalam output/result/ .
Inferensi batch juga didukung, coba
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Untuk mensintesis semua ucapan di preprocessed_data/DATASET/val.txt .
Tingkat berbicara dari ucapan yang disintesis dapat dikontrol dengan menentukan rasio durasi yang diinginkan. Misalnya, seseorang dapat meningkatkan tingkat berbicara sebesar 20 oleh
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8
Harap dicatat bahwa kemampuan kontrol berasal dari FastSpeech2 dan bukan minat vital dari Portaspeech.
Dataset yang didukung adalah
Berlari
python3 prepare_align.py --dataset DATASET
untuk beberapa persiapan.
Untuk penyelarasan paksa, Montreal memaksa Aligner (MFA) digunakan untuk mendapatkan keberpihakan antara ucapan dan urutan fonem. Penyelarasan yang telah diekstraksi untuk set data disediakan di sini. Anda harus membuka ritsleting file di preprocessed_data/DATASET/TextGrid/ . Bergantian, Anda dapat menjalankan pelurus sendiri.
Setelah itu, jalankan skrip preprocessing dengan
python3 preprocess.py --dataset DATASET
Latih model Anda dengan
python3 train.py --dataset DATASET
Opsi yang berguna:
--use_amp ke perintah di atas.CUDA_VISIBLE_DEVICES=<GPU_IDs> di awal perintah di atas.Menggunakan
tensorboard --logdir output/log
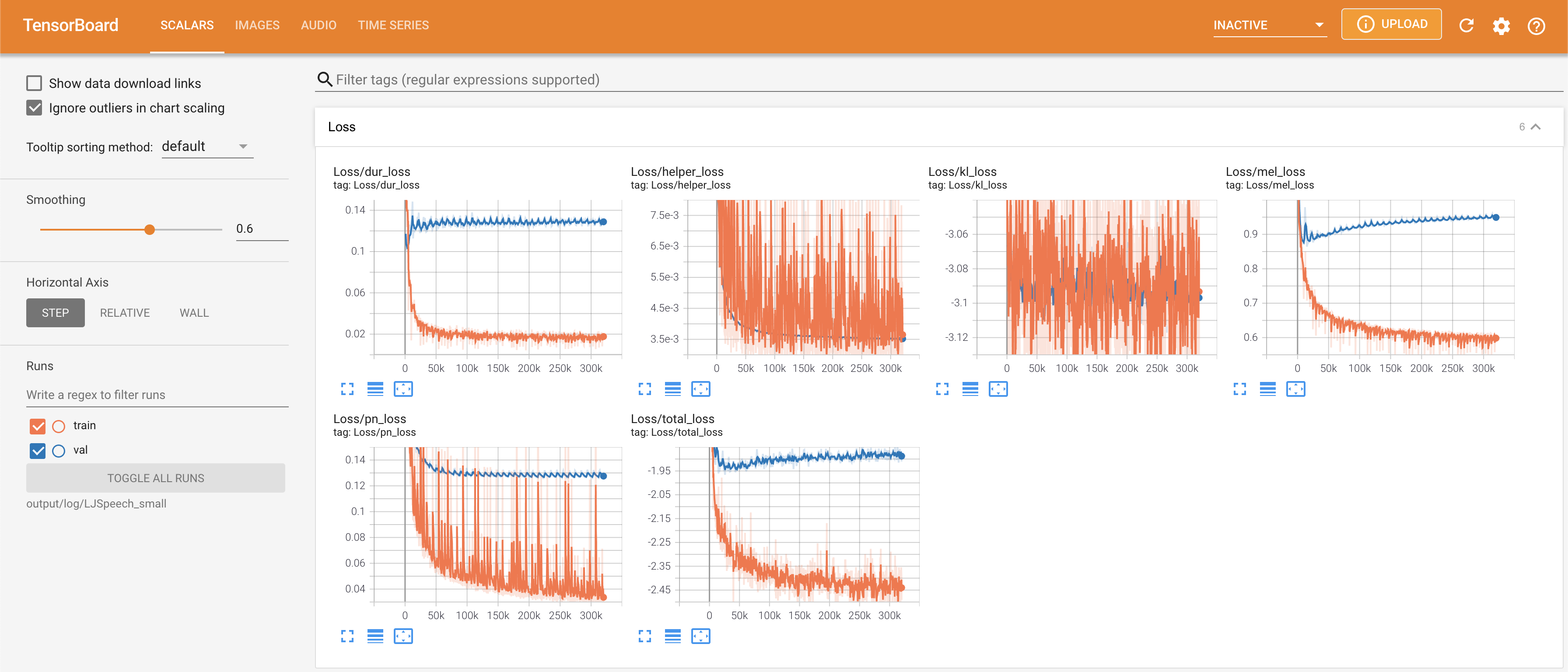
untuk melayani Tensorboard di Localhost Anda. Kurva kehilangan, sintesis mel-spectrograms, dan audio ditampilkan.
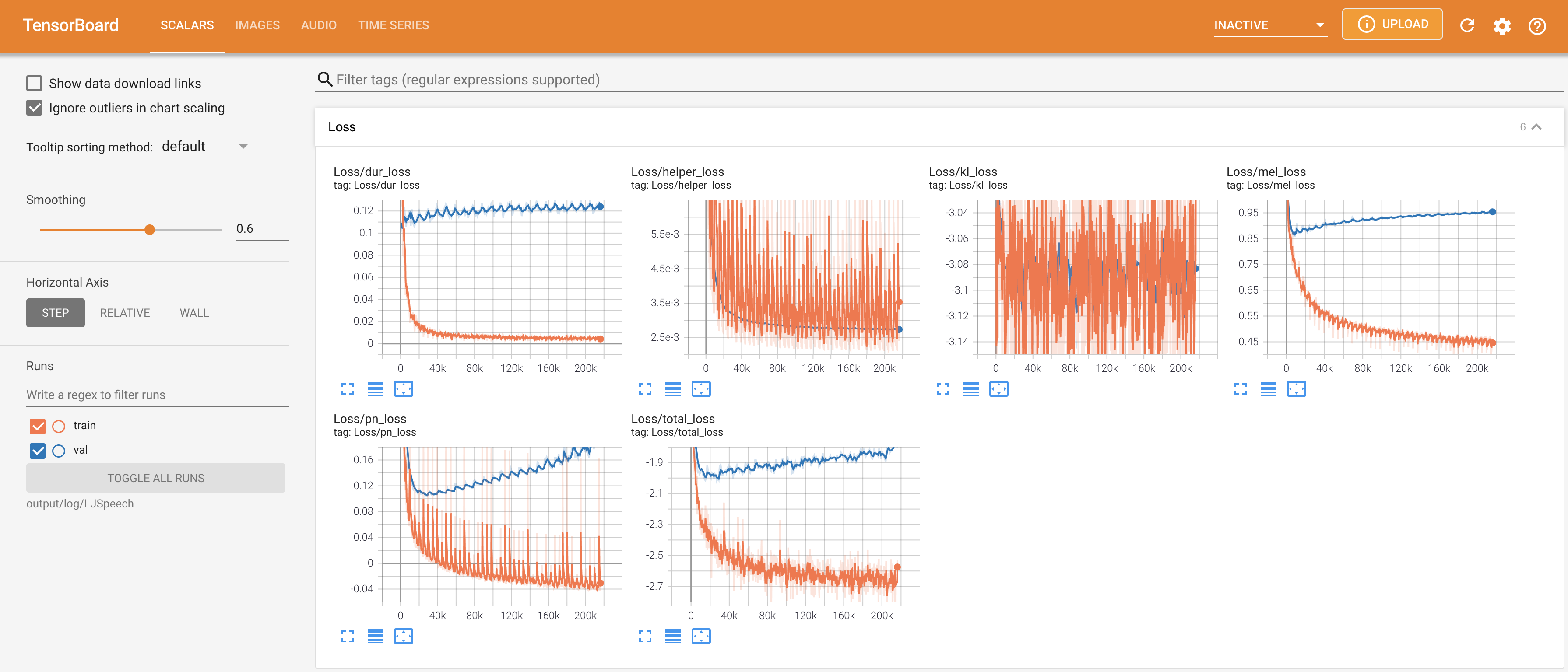
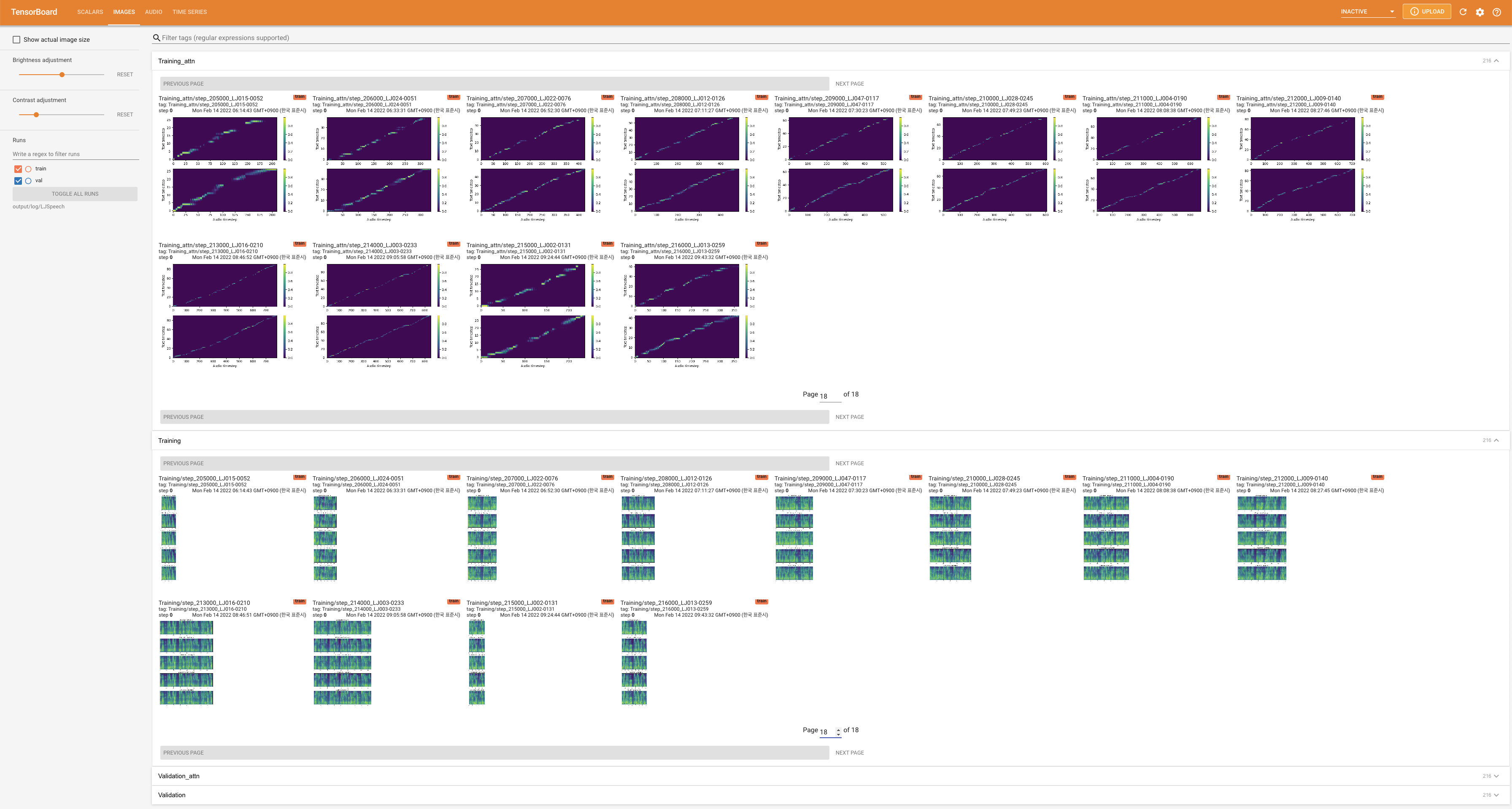
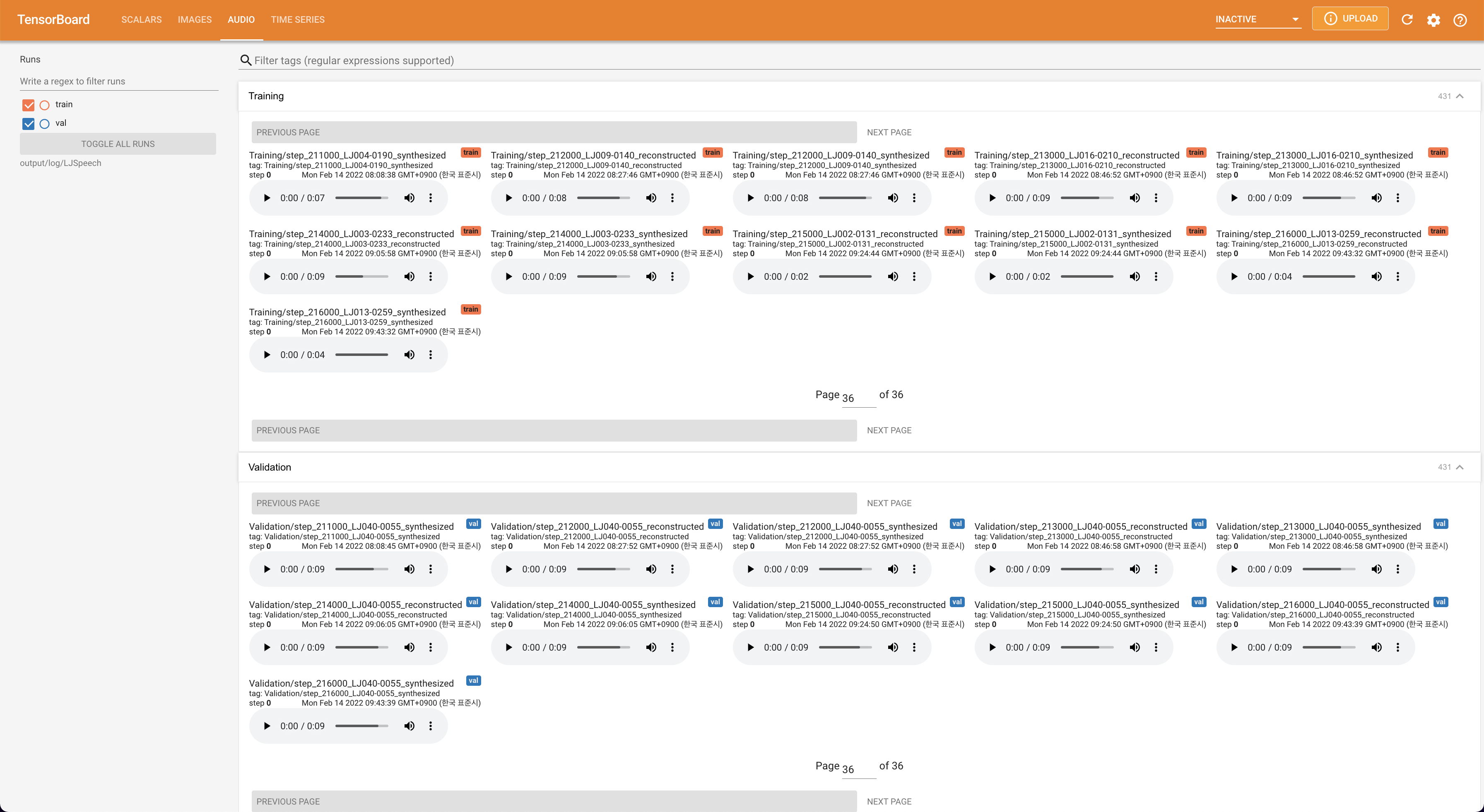
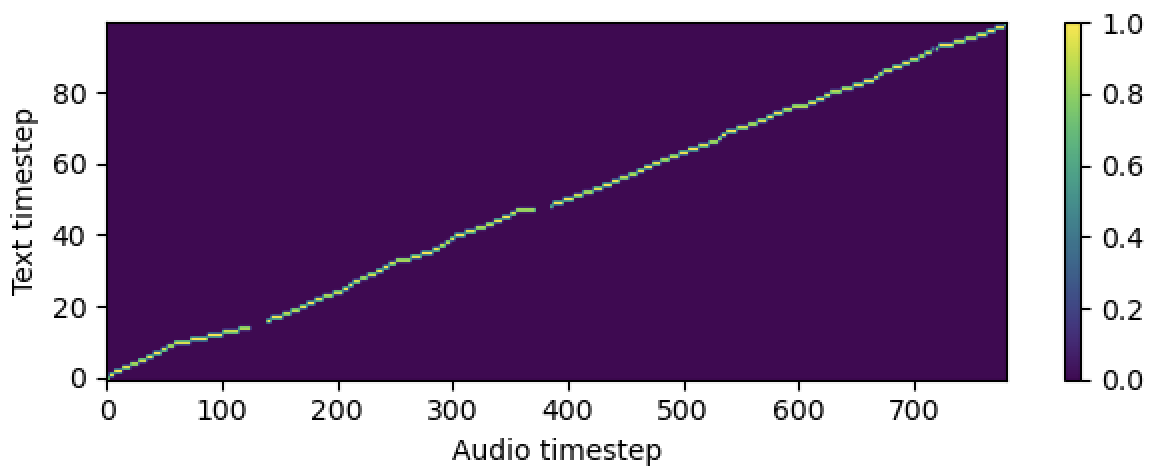
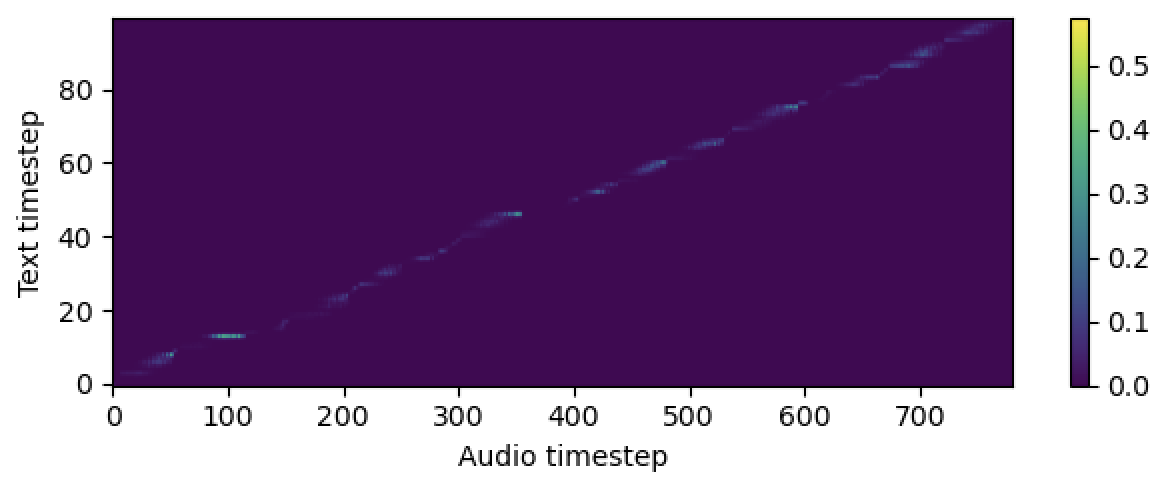
# In the train.yaml
aligner :
helper_type : " dga " # ["dga", "ctc", "none"]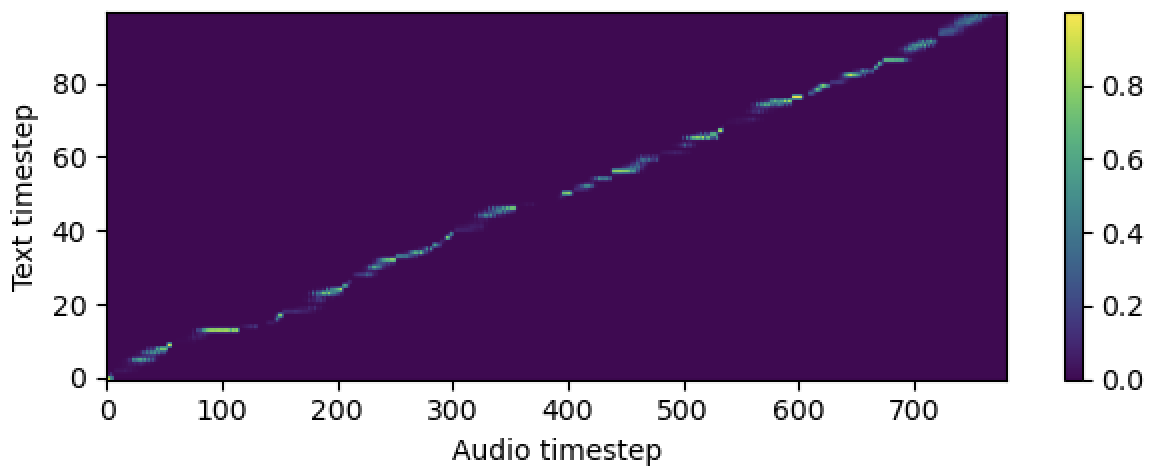
Harap kutip repositori ini dengan "CITE Repositori ini" dari bagian sekitar (kanan atas halaman utama).


